


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (10): 3281-3287.DOI: 10.11772/j.issn.1001-9081.2023101558
• The 40th CCF National Database Conference (NDBC 2023) • Previous Articles Next Articles
Zhaoze GAO, Xiaofei ZHU( ), Nengqiang XIANG
), Nengqiang XIANG
Received:2023-11-13
Revised:2023-12-28
Accepted:2024-01-02
Online:2024-10-15
Published:2024-10-10
Contact:
Xiaofei ZHU
About author:GAO Zhaoze, born in 1996, M. S. candidate. His research interests include natural language processing, stance detection.Supported by:
高肇泽, 朱小飞(), 项能强
通讯作者:
朱小飞
作者简介:高肇泽(1996—),男,山东枣庄人,硕士研究生,CCF会员,主要研究方向:自然语言处理、立场检测基金资助:CLC Number:
Zhaoze GAO, Xiaofei ZHU, Nengqiang XIANG. Semi-supervised stance detection based on category-aware curriculum learning[J]. Journal of Computer Applications, 2024, 44(10): 3281-3287.
高肇泽, 朱小飞, 项能强. 基于类别感知课程学习的半监督立场检测[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3281-3287.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023101558

Fig. 1 Overall framework of SDCL model
| 数据集 | 标签类别 | 有标签推文数 | 测试 样本数 | ||
|---|---|---|---|---|---|
| 划分方式1 | 划分方式2 | 划分方式3 | |||
| StanceUS | Pro-Dem | 320 | 654 | 981 | 1 543 |
| Anti-Dem | 9 | 22 | 32 | 46 | |
| Pro-Rep | 133 | 253 | 381 | 576 | |
| Anti-Rep | 13 | 17 | 29 | 46 | |
| other | 25 | 54 | 77 | 111 | |
| 总数 | 500 | 1 000 | 1 500 | 2 322 | |
| StanceIN | Pro-BJP | 67 | 149 | 208 | 360 |
| Anti-BJP | 136 | 275 | 425 | 680 | |
| Pro-INC | 24 | 60 | 83 | 158 | |
| Anti-INC | 2 | 3 | 6 | 15 | |
| Pro-AAP | 35 | 61 | 99 | 142 | |
| Anti-AAP | 52 | 101 | 163 | 210 | |
| other | 184 | 351 | 516 | 1 120 | |
| 总数 | 500 | 1 000 | 1 500 | 2 685 | |
Tab. 1 Distribution of training and test samples for labeled datasets under different splits
| 数据集 | 标签类别 | 有标签推文数 | 测试 样本数 | ||
|---|---|---|---|---|---|
| 划分方式1 | 划分方式2 | 划分方式3 | |||
| StanceUS | Pro-Dem | 320 | 654 | 981 | 1 543 |
| Anti-Dem | 9 | 22 | 32 | 46 | |
| Pro-Rep | 133 | 253 | 381 | 576 | |
| Anti-Rep | 13 | 17 | 29 | 46 | |
| other | 25 | 54 | 77 | 111 | |
| 总数 | 500 | 1 000 | 1 500 | 2 322 | |
| StanceIN | Pro-BJP | 67 | 149 | 208 | 360 |
| Anti-BJP | 136 | 275 | 425 | 680 | |
| Pro-INC | 24 | 60 | 83 | 158 | |
| Anti-INC | 2 | 3 | 6 | 15 | |
| Pro-AAP | 35 | 61 | 99 | 142 | |
| Anti-AAP | 52 | 101 | 163 | 210 | |
| other | 184 | 351 | 516 | 1 120 | |
| 总数 | 500 | 1 000 | 1 500 | 2 685 | |
| 模型 | StanceUS | StanceIN | ||||
|---|---|---|---|---|---|---|
划分 方 | 划分 方 | 划分 方 | 划分 方 | 划分 方 | 划分 方 | |
| SiamNet | 0.39 | 0.43 | 0.42 | 0.12 | 0.14 | 0.13 |
| BICE | 0.27 | 0.30 | 0.33 | 0.16 | 0.17 | 0.23 |
| TAN | 0.38 | 0.46 | 0.45 | 0.14 | 0.14 | 0.17 |
| SVM | 0.37 | 0.37 | 0.45 | 0.13 | 0.13 | 0.16 |
| BERT | 0.39 | 0.50 | 0.51 | 0.17 | 0.17 | 0.21 |
| ConvNet | 0.37 | 0.43 | 0.45 | 0.35 | 0.40 | 0.41 |
| BLSTM | 0.35 | 0.43 | 0.44 | 0.31 | 0.39 | 0.38 |
| LS-SVM | 0.39 | 0.42 | 0.44 | 0.18 | 0.19 | 0.18 |
| ST-ConvNet | 0.13 | 0.15 | 0.16 | 0.10 | 0.11 | 0.11 |
| ST-BLSTM | 0.13 | 0.16 | 0.19 | 0.09 | 0.12 | 0.11 |
| UST | 0.35 | 0.42 | 0.41 | 0.12 | 0.16 | 0.16 |
| GCN-ConvNet | 0.41 | 0.45 | 0.47 | 0.33 | 0.35 | 0.40 |
| GCN-BLSTM | 0.39 | 0.42 | 0.46 | 0.36 | 0.41 | 0.42 |
| SANDS | 0.49 | 0.53 | 0.55 | 0.42 | 0.45 | 0.47 |
| SDCL | 0.51 | 0.54 | 0.58 | 0.43 | 0.46 | 0.48 |
Tab. 2 Mac-F1 scores of different models under different splits of labeled training data on StanceUS and StanceIN datasets
| 模型 | StanceUS | StanceIN | ||||
|---|---|---|---|---|---|---|
划分 方 | 划分 方 | 划分 方 | 划分 方 | 划分 方 | 划分 方 | |
| SiamNet | 0.39 | 0.43 | 0.42 | 0.12 | 0.14 | 0.13 |
| BICE | 0.27 | 0.30 | 0.33 | 0.16 | 0.17 | 0.23 |
| TAN | 0.38 | 0.46 | 0.45 | 0.14 | 0.14 | 0.17 |
| SVM | 0.37 | 0.37 | 0.45 | 0.13 | 0.13 | 0.16 |
| BERT | 0.39 | 0.50 | 0.51 | 0.17 | 0.17 | 0.21 |
| ConvNet | 0.37 | 0.43 | 0.45 | 0.35 | 0.40 | 0.41 |
| BLSTM | 0.35 | 0.43 | 0.44 | 0.31 | 0.39 | 0.38 |
| LS-SVM | 0.39 | 0.42 | 0.44 | 0.18 | 0.19 | 0.18 |
| ST-ConvNet | 0.13 | 0.15 | 0.16 | 0.10 | 0.11 | 0.11 |
| ST-BLSTM | 0.13 | 0.16 | 0.19 | 0.09 | 0.12 | 0.11 |
| UST | 0.35 | 0.42 | 0.41 | 0.12 | 0.16 | 0.16 |
| GCN-ConvNet | 0.41 | 0.45 | 0.47 | 0.33 | 0.35 | 0.40 |
| GCN-BLSTM | 0.39 | 0.42 | 0.46 | 0.36 | 0.41 | 0.42 |
| SANDS | 0.49 | 0.53 | 0.55 | 0.42 | 0.45 | 0.47 |
| SDCL | 0.51 | 0.54 | 0.58 | 0.43 | 0.46 | 0.48 |
| 模型 | StanceUS | StanceIN | ||||
|---|---|---|---|---|---|---|
划分 方 | 划分 方 | 划分 方 | 划分 方 | 划分 方 | 划分 方 | |
| SDCL | 0.505 | 0.541 | 0.576 | 0.432 | 0.461 | 0.483 |
| w/o curr | 0.499 | 0.539 | 0.575 | 0.424 | 0.455 | 0.476 |
| w/o pre | 0.470 | 0.529 | 0.560 | 0.408 | 0.443 | 0.458 |
| w/o c-a | 0.492 | 0.535 | 0.568 | 0.418 | 0.450 | 0.475 |
Tab. 3 Ablation experiment results (Mac-F1) of SDCL on two datasets
| 模型 | StanceUS | StanceIN | ||||
|---|---|---|---|---|---|---|
划分 方 | 划分 方 | 划分 方 | 划分 方 | 划分 方 | 划分 方 | |
| SDCL | 0.505 | 0.541 | 0.576 | 0.432 | 0.461 | 0.483 |
| w/o curr | 0.499 | 0.539 | 0.575 | 0.424 | 0.455 | 0.476 |
| w/o pre | 0.470 | 0.529 | 0.560 | 0.408 | 0.443 | 0.458 |
| w/o c-a | 0.492 | 0.535 | 0.568 | 0.418 | 0.450 | 0.475 |
无标签推文 使用比例/% | StanceUS | StanceIN | ||||
|---|---|---|---|---|---|---|
划分 方 | 划分 方 | 划分 方 | 划分 方 | 划分 方 | 划分 方 | |
| 100 | 0.505 | 0.541 | 0.576 | 0.432 | 0.461 | 0.483 |
| 80 | 0.494 | 0.540 | 0.574 | 0.424 | 0.456 | 0.477 |
| 50 | 0.490 | 0.536 | 0.570 | 0.423 | 0.456 | 0.475 |
| 30 | 0.465 | 0.526 | 0.554 | 0.418 | 0.450 | 0.469 |
| 10 | 0.454 | 0.516 | 0.550 | 0.407 | 0.442 | 0.466 |
Tab. 4 Mac-F1 of SDCL trained by different proportions of unlabeled data
无标签推文 使用比例/% | StanceUS | StanceIN | ||||
|---|---|---|---|---|---|---|
划分 方 | 划分 方 | 划分 方 | 划分 方 | 划分 方 | 划分 方 | |
| 100 | 0.505 | 0.541 | 0.576 | 0.432 | 0.461 | 0.483 |
| 80 | 0.494 | 0.540 | 0.574 | 0.424 | 0.456 | 0.477 |
| 50 | 0.490 | 0.536 | 0.570 | 0.423 | 0.456 | 0.475 |
| 30 | 0.465 | 0.526 | 0.554 | 0.418 | 0.450 | 0.469 |
| 10 | 0.454 | 0.516 | 0.550 | 0.407 | 0.442 | 0.466 |

Fig. 2 Comparison of Mac-F1 scores between SDCL and baseline SANDS in each category
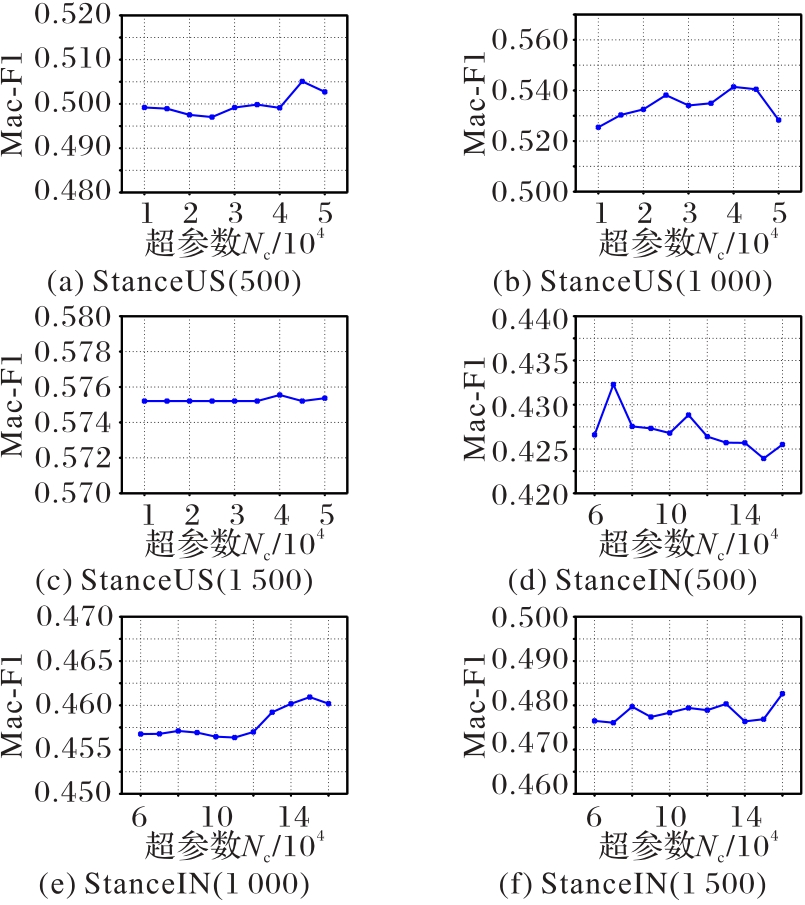
Fig. 3 Performance of hyperparameter Nc on two datasets under different splits
| 1 | AUGENSTEIN I, ROCKTÄSCHEL T, VLACHOS A, et al. Stance detection with bidirectional conditional encoding[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2016: 876-885. |
| 2 | XU C, PARIS C, NEPAL S, et al. Cross-target stance classification with self-attention networks[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg: ACL, 2018: 778-783. |
| 3 | GRIMMINGER L, KLINGER R. Hate towards the political opponent: a Twitter corpus study of the 2020 US elections on the basis of offensive speech and stance detection[C]// Proceedings of the 11th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis. Stroudsburg: ACL, 2021: 171-180. |
| 4 | GRČAR M, CHEREPNALKOSKI D, MOZETIČ I, et al. Stance and influence of Twitter users regarding the Brexit referendum[J]. Computational Social Networks, 2017, 4: No.6. |
| 5 | 张斌,王莉,杨延杰. 联合立场的过程跟踪式多任务谣言验证模型[J]. 计算机应用, 2022, 42(11): 3371-3378. |
| ZHANG B, WANG L, YANG Y J. Process tracking multi‑task rumor verification model combined with stance[J]. Journal of Computer Applications, 2022, 42(11): 3371-3378. | |
| 6 | 李峤,刘宇. 基于机器学习的推特谣言立场分析研究[J]. 电子设计工程, 2019, 27(21):36-39, 44. |
| LI Q, LIU Y. Research on Twitter rumor standpoint analysis based on machine learning[J]. Electronic Design Engineering, 2019, 27(21):36-39, 44. | |
| 7 | JIANG L, YU M, ZHOU M, et al. Target-dependent Twitter sentiment classification[C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2011: 151-160. |
| 8 | WANG B, LIAKATA M, ZUBIAGA A, et al. TDParse: multi-target-specific sentiment recognition on Twitter[C]// Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2017: 483-493. |
| 9 | GUPTA D, SINGH K, CHAKRABARTI S, et al. Multi-task learning for target-dependent sentiment classification[C]// Proceedings of the 2019 Pacific-Asia Conference on Knowledge Discovery and Data Mining, LNCS 11439. Cham: Springer, 2019: 185-197. |
| 10 | KUMAR S, CARLEY K M. Tree LSTMs with convolution units to predict stance and rumor veracity in social media conversations[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 5047-5058. |
| 11 | XUAN K, XIA R. Rumor stance classification via machine learning with text, user and propagation features[C]// Proceedings of the 2019 International Conference on Data Mining Workshops. Piscataway: IEEE, 2019: 560-566. |
| 12 | ZENG L, STARBIRD K, SPIRO E S. #Unconfirmed: classifying rumor stance in crisis-related social media messages[C]// Proceedings of the 2016 International AAAI Conference on Web and Social Media. Palo Alto, CA: AAAI Press, 2016: 747-750. |
| 13 | DARWISH K, STEFANOV P, AUPETIT M, et al. Unsupervised user stance detection on Twitter[C]// Proceedings of the 2020 International AAAI Conference on Web and Social Media. Palo Alto, CA: AAAI Press, 2020: 141-152. |
| 14 | STEFANOV P, DARWISH K, ATANASOV A, et al. Predicting the topical stance and political leaning of media using tweets[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 527-537. |
| 15 | MOHAMMAD S M, SOBHANI P, KIRITCHENKO S. Stance and sentiment in tweets[J]. ACM Transactions on Internet Technology, 2017, 17(3): No.26. |
| 16 | ZOTOVA E, AGERRI R, NUÑEZ M, et al. Multilingual stance detection in tweets: the Catalonia independence corpus[C]// Proceedings of the 12th Language Resources and Evaluation Conference. [S.l.]: European Language Resources Association, 2020: 1368-1375. |
| 17 | CONFORTI C, BERNDT J, PILEHVAR M T, et al. Will-They-Won’t-They: a very large dataset for stance detection on Twitter[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 1715-1724. |
| 18 | DU J, XU R, HE Y, et al. Stance classification with target-specific neural attention networks[C]// Proceedings of the 26th International Joint Conferences on Artificial Intelligence. California: ijcai.org, 2017: 3988-3994. |
| 19 | DUTTA S, CAUR S, CHAKRABARTI S, et al. Semi-supervised stance detection of tweets via distant network supervision[C]// Proceedings of the 15th ACM International Conference on Web Search and Data Mining. New York: ACM, 2022: 241-251. |
| 20 | MAGDY W, DARWISH K, ABOKHODAIR N, et al. #ISISisNotIslam or #DeportAllMuslims? Predicting unspoken views[C]// Proceedings of the 8th ACM Conference on Web Science. New York: ACM, 2016: 95-106. |
| 21 | BLUM A, MITCHELL T. Combining labeled and unlabeled data with co-training[C]// Proceedings of the 11th Annual Conference on Computational Learning Theory. New York: ACM, 1998: 92-100. |
| 22 | KIRITCHENKO S, MATWIN S. Email classification with co-training[C]// Proceedings of the 2001 Conference of the Centre for Advanced Studies on Collaborative Research. Riverton, NJ: IBM Corporation, 2001: 1-10. |
| 23 | CHEN M, WEINBERGER K Q, CHEN Y. Automatic feature decomposition for single view co-training[C]// Proceedings of the 28th International Conference on Machine Learning. Madison, WI: Omnipress, 2011: 953-960. |
| 24 | WAN X. Bilingual co-training for sentiment classification of Chinese product reviews[J]. Computational Linguistics, 2011, 37(3): 587-616. |
| 25 | CHEN J, FENG J, SUN X, et al. Co-training semi-supervised deep learning for sentiment classification of MOOC forum posts[J]. Symmetry, 2020, 12(1): No.8. |
| 26 | BENGIO Y, LOURADOUR J, COLLOBERT R, et al. Curriculum learning[C]// Proceedings of the 26th Annual International Conference on Machine Learning. New York: ACM, 2009: 41-48. |
| 27 | SACHAN M, XING E. Easy questions first? A case study on curriculum learning for question answering[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2016: 453-463. |
| 28 | TAY Y, WANG S, TUAN L A, et al. Simple and effective curriculum pointer-generator networks for reading comprehension over long narratives[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 4922-4931. |
| 29 | PLATANIOS E A, STRETCU O, NEUBIG G, et al. Competence-based curriculum learning for neural machine translation[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 1162-1172. |
| 30 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| 31 | ZHOU D, BOUSQUET O, LAL T N, et al. Learning with local and global consistency[C]// Proceedings of the 16th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2003: 321-328. |
| 32 | MUKHERJEE S, AWADALLAH A H. Uncertainty-aware self-training for few-shot text classification[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 21199-21212. |
| 33 | KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. (2017-02-22) [2023-05-18].. |
| [1] | Yingjun ZHANG, Niuniu LI, Binhong XIE, Rui ZHANG, Wangdong LU. Semi-supervised object detection framework guided by curriculum learning [J]. Journal of Computer Applications, 2024, 44(8): 2326-2333. |
| [2] | Yan ZHOU, Yang LI. Rectified cross pseudo supervision method with attention mechanism for stroke lesion segmentation [J]. Journal of Computer Applications, 2024, 44(6): 1942-1948. |
| [3] | Shuaihua ZHANG, Shufen ZHANG, Mingchuan ZHOU, Chao XU, Xuebin CHEN. Malicious traffic detection model based on semi-supervised federated learning [J]. Journal of Computer Applications, 2024, 44(11): 3487-3494. |
| [4] | Xinrong HU, Jingxue CHEN, Zijian HUANG, Bangchao WANG, Xun YAO, Junping LIU, Qiang ZHU, Jie YANG. Graph convolution network-based masked data augmentation [J]. Journal of Computer Applications, 2024, 44(11): 3335-3344. |
| [5] | Ruiqi WANG, Shujuan JI, Ning CAO, Yajie GUO. Semi-supervised fake job advertisement detection model based on consistency training [J]. Journal of Computer Applications, 2023, 43(9): 2932-2939. |
| [6] | Lifeng SHI, Zhengwei NI. Dialogue state tracking model based on slot correlation information extraction [J]. Journal of Computer Applications, 2023, 43(5): 1430-1437. |
| [7] | Chunmao JIANG, Peng WU, Zhicong LI. Semi-supervised three-way clustering ensemble based on Seeds set and pairwise constraints [J]. Journal of Computer Applications, 2023, 43(5): 1481-1488. |
| [8] | Boyi FU, Yuncong PENG, Xin LAN, Xiaolin QIN. Survey of label noise learning algorithms based on deep learning [J]. Journal of Computer Applications, 2023, 43(3): 674-684. |
| [9] | Jinye LI, Ruizhang HUANG, Yongbin QIN, Yanping CHEN, Xiaoyu TIAN. Recognition of sentencing circumstances in adjudication documents based on abductive learning [J]. Journal of Computer Applications, 2022, 42(6): 1802-1807. |
| [10] | Yongru QIU, Guangle YAO, Jie FENG, Haoyu CUI. Single image de-raining algorithm based on semi-supervised learning [J]. Journal of Computer Applications, 2022, 42(5): 1577-1582. |
| [11] | Yuchang YIN, Hongyuan WANG, Li CHEN, Zundeng FENG, Yu XIAO. One-shot video-based person re-identification with multi-loss learning and joint metric [J]. Journal of Computer Applications, 2022, 42(3): 764-769. |
| [12] | Yu LU, Lingyun ZHAO, Binwen BAI, Zhen JIANG. Imbalanced classification algorithm based on improved semi-supervised clustering [J]. Journal of Computer Applications, 2022, 42(12): 3750-3755. |
| [13] | Jie WU, Shitian ZHANG, Haibin XIE, Guang YANG. Semi-supervised knee abnormality classification based on multi-imaging center MRI data [J]. Journal of Computer Applications, 2022, 42(1): 316-324. |
| [14] | MAO Mingze, CAO Ruihao, YAN Chungang. Semi-supervised classification algorithm based on weight diversity [J]. Journal of Computer Applications, 2021, 41(9): 2473-2480. |
| [15] | ZHANG Shipeng, LI Yongzhong, DU Xiangtong. Intrusion detection model based on semi-supervised learning and three-way decision [J]. Journal of Computer Applications, 2021, 41(9): 2602-2608. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||