


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (12): 3759-3765.DOI: 10.11772/j.issn.1001-9081.2023121740
• Artificial intelligence • Previous Articles Next Articles
Zucuan ZHANG1,2,3, Xuebin CHEN1,2,3( ), Rui GAO1,2,3, Yuanhuai ZOU1,2,3
), Rui GAO1,2,3, Yuanhuai ZOU1,2,3
Received:2023-12-18
Revised:2024-04-13
Accepted:2024-04-17
Online:2024-05-07
Published:2024-12-10
Contact:
Xuebin CHEN
About author:ZHANG Zucuan, born in 1998, M. S. candidate. His research interests include data security, federated learning.Supported by:
张祖篡1,2,3, 陈学斌1,2,3(), 高瑞1,2,3, 邹元怀1,2,3
通讯作者:
陈学斌
作者简介:张祖篡(1998—),男,江苏徐州人,硕士研究生,CCF会员,主要研究方向:数据安全、联邦学习基金资助:CLC Number:
Zucuan ZHANG, Xuebin CHEN, Rui GAO, Yuanhuai ZOU. Federated learning client selection method based on label classification[J]. Journal of Computer Applications, 2024, 44(12): 3759-3765.
张祖篡, 陈学斌, 高瑞, 邹元怀. 基于标签分类的联邦学习客户端选择方法[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3759-3765.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023121740
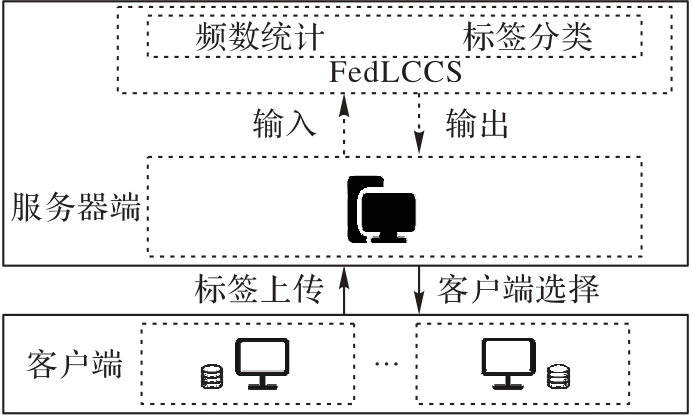
Fig. 1 Architecture of FedLCCS

Fig. 2 Examples of experimental datasets
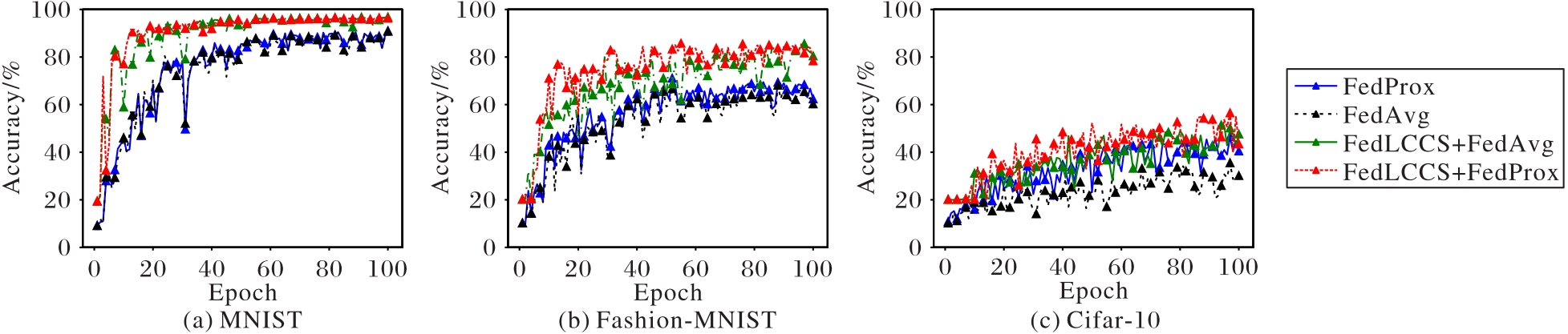
Fig. 3 Model accuracy on different datasets
| 方法 | MNIST | Fashion-MNIST | Cifar-10 |
|---|---|---|---|
| FedAvg | 86.347 500 09 | 62.822 813 03 | 28.779 374 96 |
| FedProx | 89.433 438 31 | 65.895 312 19 | 40.324 999 93 |
| FedLCCS+FedAvg | 95.477 172 61 | 79.727 617 09 | 44.428 515 32 |
| FedLCCS+FedProx | 95.965 331 79 | 81.777 076 48 | 48.135 447 50 |
Tab. 1 Comparison of accuracy of different methods
| 方法 | MNIST | Fashion-MNIST | Cifar-10 |
|---|---|---|---|
| FedAvg | 86.347 500 09 | 62.822 813 03 | 28.779 374 96 |
| FedProx | 89.433 438 31 | 65.895 312 19 | 40.324 999 93 |
| FedLCCS+FedAvg | 95.477 172 61 | 79.727 617 09 | 44.428 515 32 |
| FedLCCS+FedProx | 95.965 331 79 | 81.777 076 48 | 48.135 447 50 |
| 方法 | 第1次达到阈值的轮次 | 第10次达到阈值的轮次 | ||||
|---|---|---|---|---|---|---|
| MNIST | Fashion- MNIST | Cifar- 10 | MNIST | Fashion- MNIST | Cifar- 10 | |
| FedAvg | 39 | 21 | 21 | 53 | 46 | 54 |
| FedProx | 23 | 17 | 13 | 39 | 43 | 27 |
| FedLCCS+FedAvg | 8 | 9 | 11 | 22 | 18 | 23 |
| FedLCCS+FedProx | 8 | 6 | 10 | 19 | 17 | 22 |
Tab. 2 Comparison of convergence speed of different methods
| 方法 | 第1次达到阈值的轮次 | 第10次达到阈值的轮次 | ||||
|---|---|---|---|---|---|---|
| MNIST | Fashion- MNIST | Cifar- 10 | MNIST | Fashion- MNIST | Cifar- 10 | |
| FedAvg | 39 | 21 | 21 | 53 | 46 | 54 |
| FedProx | 23 | 17 | 13 | 39 | 43 | 27 |
| FedLCCS+FedAvg | 8 | 9 | 11 | 22 | 18 | 23 |
| FedLCCS+FedProx | 8 | 6 | 10 | 19 | 17 | 22 |
| 方法 | MNIST | Fashion-MNIST | Cifar-10 |
|---|---|---|---|
| FedAvg | 209.197 206 73 | 204.497 248 88 | 216.265 940 18 |
| FedProx | 263.390 083 55 | 259.871 740 10 | 296.034 562 34 |
| FedLCCS+FedAvg | 176.869 442 22 | 132.991 822 95 | 199.825 600 86 |
| FedLCCS+FedProx | 216.986 409 66 | 212.674 599 40 | 231.530 412 67 |
Tab. 3 Comparison of running time of different methods
| 方法 | MNIST | Fashion-MNIST | Cifar-10 |
|---|---|---|---|
| FedAvg | 209.197 206 73 | 204.497 248 88 | 216.265 940 18 |
| FedProx | 263.390 083 55 | 259.871 740 10 | 296.034 562 34 |
| FedLCCS+FedAvg | 176.869 442 22 | 132.991 822 95 | 199.825 600 86 |
| FedLCCS+FedProx | 216.986 409 66 | 212.674 599 40 | 231.530 412 67 |
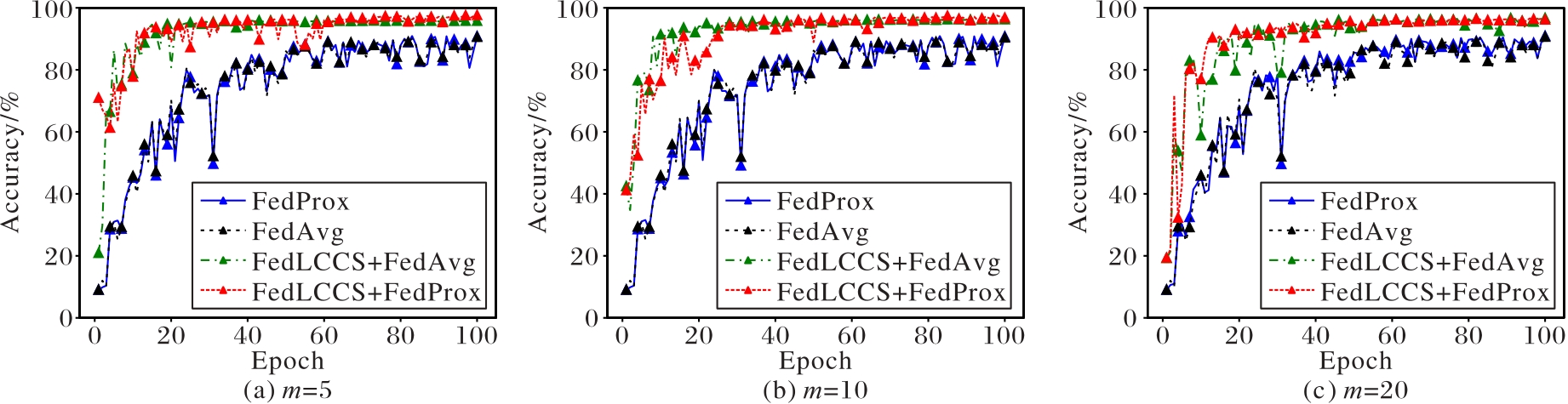
Fig. 4 Model accuracy under different slice numbers
| 方法 | m | 准确率/% | 方法 | m | 准确率/% |
|---|---|---|---|---|---|
| FedAvg | 5 | 91.077 500 34 | FedLCCS+FedAvg | 5 | 95.636 867 05 |
| 10 | 90.654 687 41 | 10 | 95.505 434 32 | ||
| 20 | 86.347 500 09 | 20 | 95.477 172 61 | ||
| FedProx | 5 | 93.635 625 12 | FedLCCS+FedProx | 5 | 96.686 664 82 |
| 10 | 90.929 062 84 | 10 | 96.655 052 19 | ||
| 20 | 89.433 438 31 | 20 | 95.965 331 79 |
Tab. 4 Comparison of method accuracy under different slice numbers
| 方法 | m | 准确率/% | 方法 | m | 准确率/% |
|---|---|---|---|---|---|
| FedAvg | 5 | 91.077 500 34 | FedLCCS+FedAvg | 5 | 95.636 867 05 |
| 10 | 90.654 687 41 | 10 | 95.505 434 32 | ||
| 20 | 86.347 500 09 | 20 | 95.477 172 61 | ||
| FedProx | 5 | 93.635 625 12 | FedLCCS+FedProx | 5 | 96.686 664 82 |
| 10 | 90.929 062 84 | 10 | 96.655 052 19 | ||
| 20 | 89.433 438 31 | 20 | 95.965 331 79 |
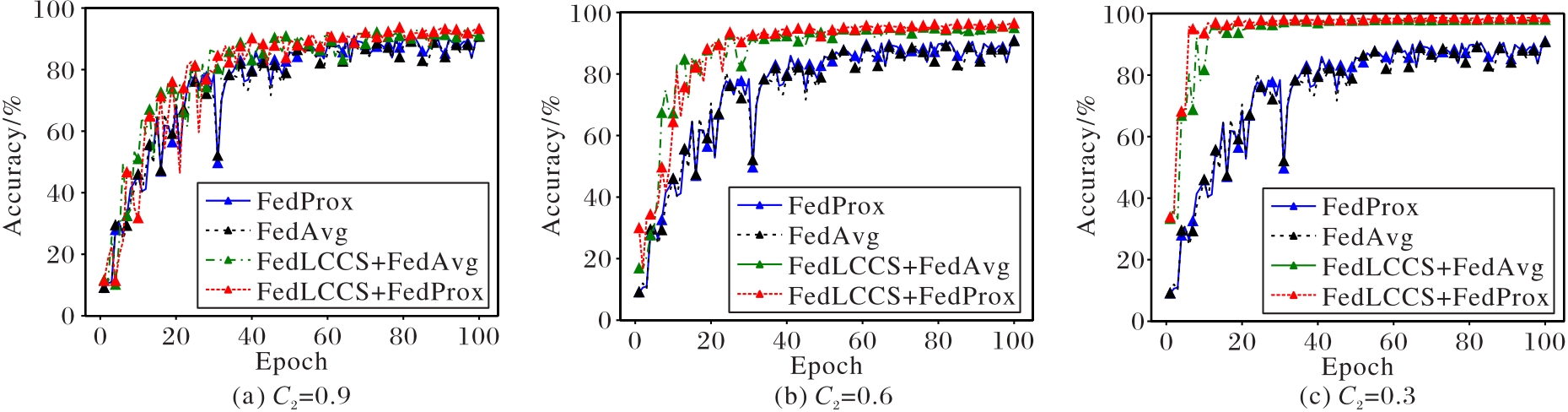
Fig. 5 Model accuracy under different target label array selection ratios
| 方法 | 准确率/% | 方法 | 准确率/% | ||
|---|---|---|---|---|---|
| FedAvg | 0.9 | 86.347 500 09 | FedLCCS+FedAvg | 0.9 | 90.962 725 16 |
| 0.6 | 86.347 500 09 | 0.6 | 94.317 240 24 | ||
| 0.3 | 86.347 500 09 | 0.3 | 97.744 347 12 | ||
| FedProx | 0.9 | 89.433 438 31 | FedLCCS+FedProx | 0.9 | 91.759 270 67 |
| 0.6 | 89.433 438 31 | 0.6 | 95.490 865 23 | ||
| 0.3 | 89.433 438 31 | 0.3 | 98.487 850 91 |
Tab. 5 Comparison of methods accuracy under different target label array selection ratios
| 方法 | 准确率/% | 方法 | 准确率/% | ||
|---|---|---|---|---|---|
| FedAvg | 0.9 | 86.347 500 09 | FedLCCS+FedAvg | 0.9 | 90.962 725 16 |
| 0.6 | 86.347 500 09 | 0.6 | 94.317 240 24 | ||
| 0.3 | 86.347 500 09 | 0.3 | 97.744 347 12 | ||
| FedProx | 0.9 | 89.433 438 31 | FedLCCS+FedProx | 0.9 | 91.759 270 67 |
| 0.6 | 89.433 438 31 | 0.6 | 95.490 865 23 | ||
| 0.3 | 89.433 438 31 | 0.3 | 98.487 850 91 |
| 1 | LIN B Y, HE C, ZENG Z, et al. FedNLP: benchmarking federated learning methods for natural language processing tasks[C]// Findings of the Association for Computational Linguistics: NAACL 2022. Stroudsburg, PA: ACL, 2022: 157-175. |
| 2 | 刘晶,董志红,张喆语,等. 基于联邦增量学习的工业物联网数据共享方法[J]. 计算机应用, 2022,42(4):1235-1243. |
| LIU J, DONG Z H, ZHANG Z Y, et al. Data sharing method of industrial internet of things based on federal incremental learning [J]. Journal of Computer Applications, 2022, 42(4): 1235-1243. | |
| 3 | 罗长银,陈学斌,马春地,等. 面向区块链的在线联邦增量学习算法[J]. 计算机应用, 2021, 41(2):363-371. |
| LUO C Y, CHEN X B, MA C D, et al. Online federated incremental learning algorithm for blockchain[J]. Journal of Computer Applications, 2021, 41(2): 363-371. | |
| 4 | 王腾,霍峥,黄亚鑫,等.联邦学习中的隐私保护技术研究综述[J]. 计算机应用, 2023, 43(2):437-449. |
| WANG T, HUO Z, HUANG Y X, et al. Review on privacy-preserving technologies in federated learning [J]. Journal of Computer Applications, 2023, 43(2): 437-449. | |
| 5 | 尹春勇,屈锐. 基于个性化差分隐私的联邦学习算法[J]. 计算机应用, 2023, 43(4):1160-1168. |
| YIN C Y, QU R. Federated learning algorithm based on personalized differential privacy [J]. Journal of Computer Applications, 2023, 43(4): 1160-1168. | |
| 6 | MA X, ZHU J, LIN Z, et al. A state-of-the-art survey on solving non-IID data in federated learning [J]. Future Generation Computer Systems, 2022, 135: 244-258. |
| 7 | LU W, HU X, WANG J, et al. FedCLIP: fast generalization and personalization for clip in federated learning [EB/OL]. [2024-04-11].. |
| 8 | WANG Y, GAN W, YANG J, et al. Dynamic curriculum learning for imbalanced data classification[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 5016-5025. |
| 9 | PENG B, CHI M, LIU C. Non-IID federated learning via random exchange of local feature maps for textile IIoT secure computing [J]. SCIENCE CHINA Information Sciences, 2022, 65(7): No.170302. |
| 10 | 梁天恺,曾碧,陈光. 联邦学习综述:概念、技术、应用与挑战[J]. 计算机应用, 2022, 42(12):3651-3662. |
| LIANG T K, ZENG B, CHEN G. Federated learning survey: concepts, technologies, applications and challenges[J]. Journal of Computer Applications, 2022, 42(12): 3651-3662. | |
| 11 | McMAHAN H B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[C]// Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2017: 1273-1282. |
| 12 | KAIROUZ P, McMAHAN H B, AVENT B, et al. Advances and open problems in federated learning[J]. Foundations and Trends® in Machine Learning, 2021, 14(1/2): 1-210. |
| 13 | 汤凌韬,王迪,刘盛云. 面向非独立同分布数据的联邦学习数据增强方案[J]. 通信学报, 2023, 44(1):164-176. |
| TANG L T, WANG D, LIU S Y. Data augmentation scheme for federated learning with non-IID data[J]. Journal on Communications, 2023, 44(1): 164-176. | |
| 14 | ZHAO Y, LI M, LAI L, et al. Federated learning with non-IID data [EB/OL].[2024-04-08].. |
| 15 | 蓝梦婕,蔡剑平,孙岚. 非独立同分布数据下的自正则化联邦学习优化方法[J]. 计算机应用, 2023, 43(7):2073-2081. |
| LAN M J, CAI J P, SUN L. Self-regularization optimization methods for Non-IID data in federated learning [J]. Journal of Computer Applications, 2023, 43(7):2073-2081. | |
| 16 | 张泽辉,李庆丹,富瑶,等. 面向非独立同分布数据的自适应联邦深度学习算法[J]. 自动化学报, 2023, 49(12):2493-2506. |
| ZHANG Z H, LI Q D, FU Y, et al. Adaptive federated deep learning with non-IID data [J]. Acta Automatica Sinica, 2023, 49(12): 2493-2506. | |
| 17 | ZENG D, HU X, LIU S, et al. Stochastic clustered federated learning[EB/OL]. [2024-04-08].. |
| 18 | LIU T, DING J, WANG T, et al. Towards fast and accurate federated learning with non-IID data for cloud-based IoT applications[J]. Journal of Circuits, Systems and Computers, 2022, 31(13): No.2250235. |
| 19 | 陈学斌,任志强,张宏扬. 联邦学习中的安全威胁与防御措施综述[J]. 计算机应用, 2024, 44(6):1663-1672. |
| CHEN X B, REN Z Q, ZHANG H Y. Review on security threats and defense measures in federated learning[J]. Journal of Computer Applications, 2024, 44(6):1663-1672. | |
| 20 | ZHANG L, SHEN B, BARNAWI A, et al. FedDPGAN: federated differentially private generative adversarial networks framework for the detection of COVID-19 pneumonia[J]. Information Systems Frontiers, 2021, 23(6): 1403-1415. |
| 21 | YUAN L, SU L, WANG Z. Federated transfer-ordered-personalized learning for driver monitoring application [J]. IEEE Internet of Things Journal, 2023, 10(20): 18292-18301. |
| 22 | WANG H, KAPLAN Z, NIU D, et al. Optimizing federated learning on non-IID data with reinforcement learning[C]// Proceedings of the 2020 IEEE Conference on Computer Communications. Piscataway: IEEE, 2020: 1698-1707. |
| 23 | LI T, SAHU A K, ZAHEER M, et al. Federated optimization in heterogeneous networks[EB/OL]. [2024-04-13].. |
| [1] | Tingwei CHEN, Jiacheng ZHANG, Junlu WANG. Random validation blockchain construction for federated learning [J]. Journal of Computer Applications, 2024, 44(9): 2770-2776. |
| [2] | Zheyuan SHEN, Keke YANG, Jing LI. Personalized federated learning method based on dual stream neural network [J]. Journal of Computer Applications, 2024, 44(8): 2319-2325. |
| [3] | Wei LUO, Jinquan LIU, Zheng ZHANG. Dual vertical federated learning framework incorporating secret sharing technology [J]. Journal of Computer Applications, 2024, 44(6): 1872-1879. |
| [4] | Xuebin CHEN, Zhiqiang REN, Hongyang ZHANG. Review on security threats and defense measures in federated learning [J]. Journal of Computer Applications, 2024, 44(6): 1663-1672. |
| [5] | Sunjie YU, Hui ZENG, Shiyu XIONG, Hongzhou SHI. Incentive mechanism for federated learning based on generative adversarial network [J]. Journal of Computer Applications, 2024, 44(2): 344-352. |
| [6] | Jie WU, Xuezhong QIAN, Wei SONG. Personalized federated learning based on similarity clustering and regularization [J]. Journal of Computer Applications, 2024, 44(11): 3345-3353. |
| [7] | Xuebin CHEN, Changsheng QU. Overview of backdoor attacks and defense in federated learning [J]. Journal of Computer Applications, 2024, 44(11): 3459-3469. |
| [8] | Shuaihua ZHANG, Shufen ZHANG, Mingchuan ZHOU, Chao XU, Xuebin CHEN. Malicious traffic detection model based on semi-supervised federated learning [J]. Journal of Computer Applications, 2024, 44(11): 3487-3494. |
| [9] | Chunyong YIN, Yongcheng ZHOU. Automatically adjusted clustered federated learning for double-ended clustering [J]. Journal of Computer Applications, 2024, 44(10): 3011-3020. |
| [10] | Hui ZHOU, Yuling CHEN, Xuewei WANG, Yangwen ZHANG, Jianjiang HE. Deep shadow defense scheme of federated learning based on generative adversarial network [J]. Journal of Computer Applications, 2024, 44(1): 223-232. |
| [11] | Mengjie LAN, Jianping CAI, Lan SUN. Self-regularization optimization methods for Non-IID data in federated learning [J]. Journal of Computer Applications, 2023, 43(7): 2073-2081. |
| [12] | Wanzhen CHEN, En ZHANG, Leiyong QIN, Shuangxi HONG. Privacy-preserving federated learning algorithm based on blockchain in edge computing [J]. Journal of Computer Applications, 2023, 43(7): 2209-2216. |
| [13] | Shangjing LIN, Ji MA, Bei ZHUANG, Yueying LI, Ziyi LI, Tie LI, Jin TIAN. Wireless traffic prediction based on federated learning [J]. Journal of Computer Applications, 2023, 43(6): 1900-1909. |
| [14] | Chunyong YIN, Rui QU. Federated learning algorithm based on personalized differential privacy [J]. Journal of Computer Applications, 2023, 43(4): 1160-1168. |
| [15] | Shaochen HAO, Zizuan WEI, Yao MA, Dan YU, Yongle CHEN. Network intrusion detection model based on efficient federated learning algorithm [J]. Journal of Computer Applications, 2023, 43(4): 1169-1175. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||