


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (12): 3847-3854.DOI: 10.11772/j.issn.1001-9081.2024121747
• Artificial intelligence • Previous Articles Next Articles
Jing ZHOU( ), Zhenyang TANG, Hui DONG, Xin LIU
), Zhenyang TANG, Hui DONG, Xin LIU
Received:2024-12-12
Revised:2025-04-12
Accepted:2025-04-15
Online:2025-04-25
Published:2025-12-10
Contact:
Jing ZHOU
About author:TANG Zhenyang, born in 2002, M. S. candidate. His research interests include natural language processing.Supported by:
周景(), 唐振洋, 董晖, 刘心
通讯作者:
周景
作者简介:唐振洋(2002—),男,河南南阳人,硕士研究生,主要研究方向:自然语言处理基金资助:CLC Number:
Jing ZHOU, Zhenyang TANG, Hui DONG, Xin LIU. Multi-label text classification method of power customer service work orders integrating feature enhancement and contrastive learning[J]. Journal of Computer Applications, 2025, 45(12): 3847-3854.
周景, 唐振洋, 董晖, 刘心. 融合特征增强和对比学习的电力客服工单多标签文本分类方法[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 3847-3854.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024121747
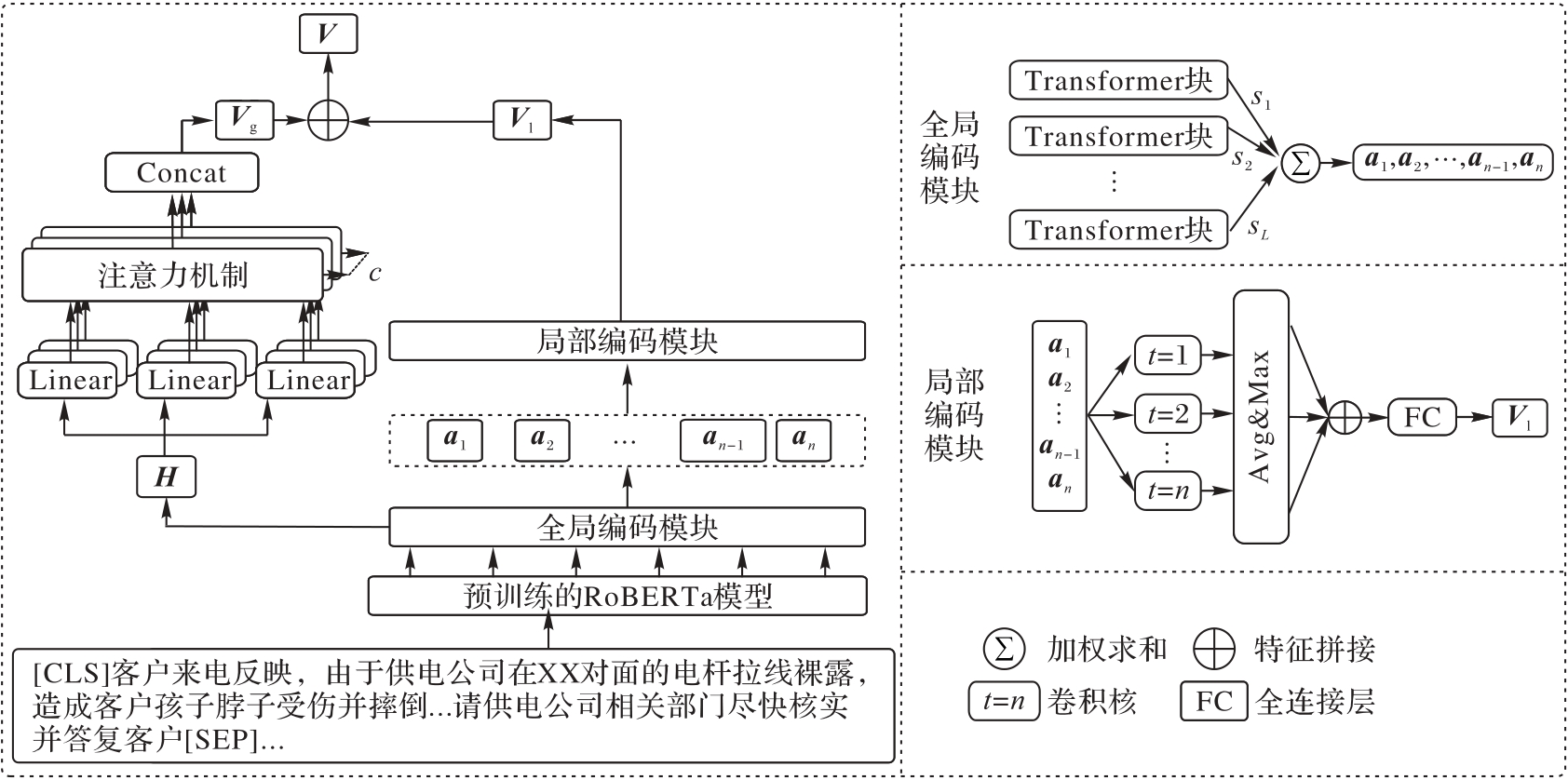
Fig. 1 Schematic diagram of feature enhancement module
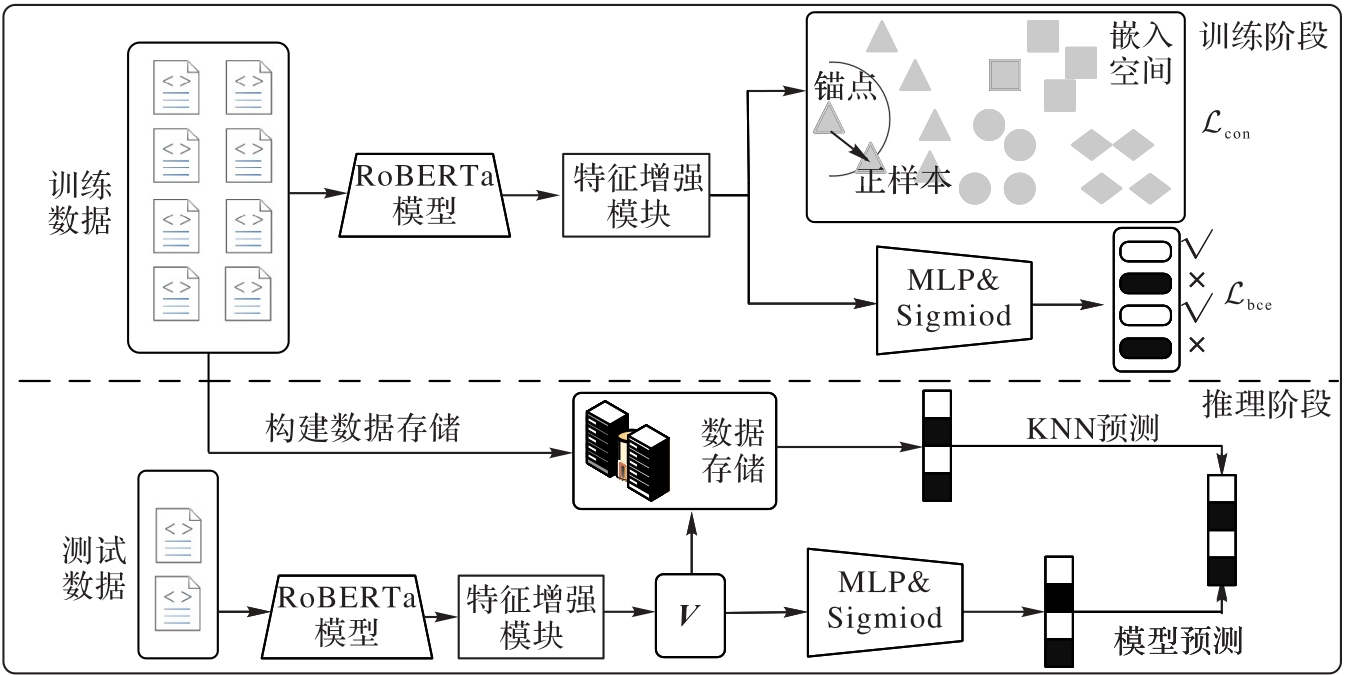
Fig. 2 Processes of model training and inference
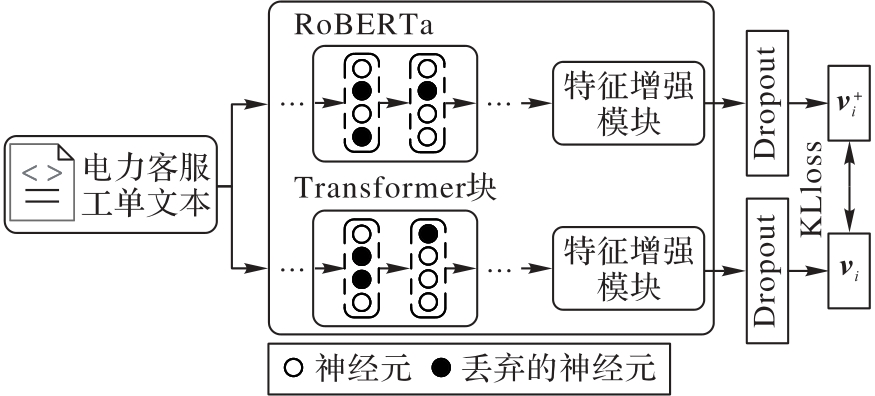
Fig. 3 R-Drop positive sample generation method
| 电力客服工单文本 | 文本标签 |
|---|---|
客户来电反映,由于供电公司在XX对面的电杆拉线裸露,造成客户孩子脖子受伤并摔倒,客户要求赔偿, 并对拉线安装位置不认可存在安全隐患。 | 安全隐患;故障报修 |
客户来电反映,其为居民用电性质用电,对于阶梯电价扣款不认可,今日客户缴费60元,被扣款24.45元, 认为表中有钱不应该扣除,已解释,但客户仍然不解。请供电公司相关部门尽快核实并答复客户。 | 电价电费;回电处理 |
Tab. 1 Examples of power customer service work order texts and corresponding labels
| 电力客服工单文本 | 文本标签 |
|---|---|
客户来电反映,由于供电公司在XX对面的电杆拉线裸露,造成客户孩子脖子受伤并摔倒,客户要求赔偿, 并对拉线安装位置不认可存在安全隐患。 | 安全隐患;故障报修 |
客户来电反映,其为居民用电性质用电,对于阶梯电价扣款不认可,今日客户缴费60元,被扣款24.45元, 认为表中有钱不应该扣除,已解释,但客户仍然不解。请供电公司相关部门尽快核实并答复客户。 | 电价电费;回电处理 |
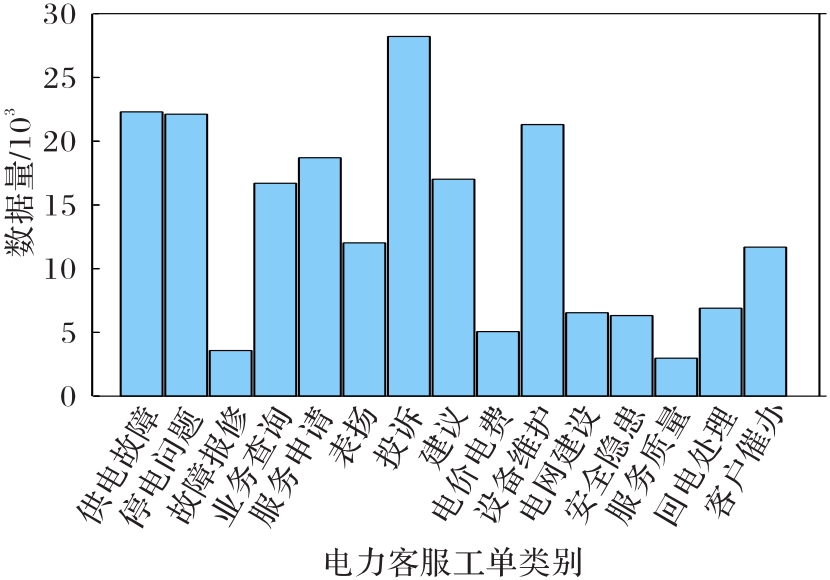
Fig. 4 Category distribution of power customer service work order dataset
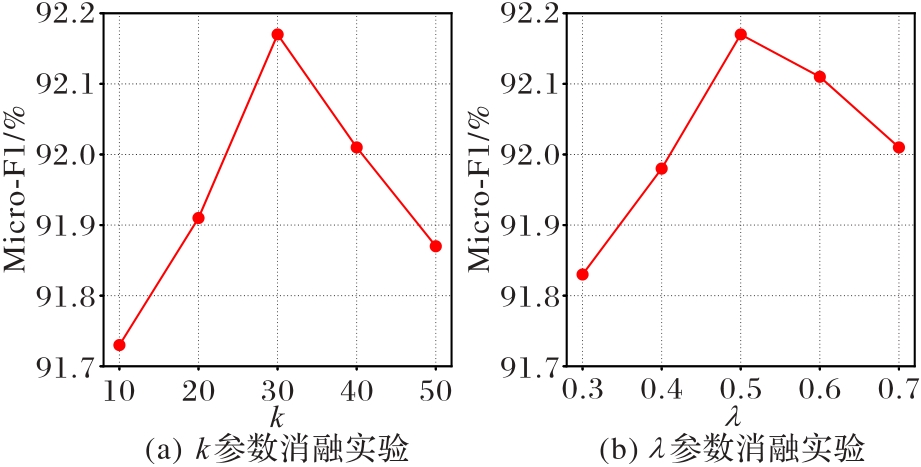
Fig. 5 Hyperparameter analysis of power customer service work order dataset
| 方法 | Micro-P | Micro-R | Micro-F1 |
|---|---|---|---|
| LSAN | 94.71 | 85.70 | 89.98 |
| SGM | 94.19 | 87.41 | 90.67 |
| Seq2Set | 95.71 | 86.65 | 90.95 |
| BERT | 94.25 | 87.12 | 90.55 |
| RoBERTa | 94.49 | 87.38 | 90.80 |
| LACO | 95.77 | 88.04 | 91.75 |
| SCL | 94.54 | 87.50 | 90.88 |
| 本文方法 | 95.36 | 89.18 | 92.17 |
Tab. 2 Comparison experimental results
| 方法 | Micro-P | Micro-R | Micro-F1 |
|---|---|---|---|
| LSAN | 94.71 | 85.70 | 89.98 |
| SGM | 94.19 | 87.41 | 90.67 |
| Seq2Set | 95.71 | 86.65 | 90.95 |
| BERT | 94.25 | 87.12 | 90.55 |
| RoBERTa | 94.49 | 87.38 | 90.80 |
| LACO | 95.77 | 88.04 | 91.75 |
| SCL | 94.54 | 87.50 | 90.88 |
| 本文方法 | 95.36 | 89.18 | 92.17 |
| 方法 | Micro-F1/% | Hamming Loss |
|---|---|---|
| RoBERTa | 91.20 | 0.014 7 |
| +全局编码 | 91.71 | 0.013 8 |
| +局部编码( | 91.94 | 0.013 3 |
| +局部编码( | 92.17 | 0.013 0 |
Tab. 3 Ablation experimental results of feature enhancement module
| 方法 | Micro-F1/% | Hamming Loss |
|---|---|---|
| RoBERTa | 91.20 | 0.014 7 |
| +全局编码 | 91.71 | 0.013 8 |
| +局部编码( | 91.94 | 0.013 3 |
| +局部编码( | 92.17 | 0.013 0 |
| 方法 | Micro-F1/% | Hamming Loss |
|---|---|---|
| 无监督 | 91.47 | 0.014 3 |
| 有监督 | 91.02 | 0.015 1 |
| 本文方法 | 92.17 | 0.013 0 |
Tab. 4 Comparison of results of different contrastive learning losses
| 方法 | Micro-F1/% | Hamming Loss |
|---|---|---|
| 无监督 | 91.47 | 0.014 3 |
| 有监督 | 91.02 | 0.015 1 |
| 本文方法 | 92.17 | 0.013 0 |
| 方法 | Micro-F1/% | Hamming Loss |
|---|---|---|
| 随机掩码 | 91.47 | 0.014 1 |
| 连续掩码 | 91.31 | 0.014 4 |
| Dropout | 91.90 | 0.013 6 |
| R-Drop | 92.17 | 0.013 0 |
Tab. 5 Comparison of positive sample generation methods
| 方法 | Micro-F1/% | Hamming Loss |
|---|---|---|
| 随机掩码 | 91.47 | 0.014 1 |
| 连续掩码 | 91.31 | 0.014 4 |
| Dropout | 91.90 | 0.013 6 |
| R-Drop | 92.17 | 0.013 0 |

Fig. 6 Loss function variation curve
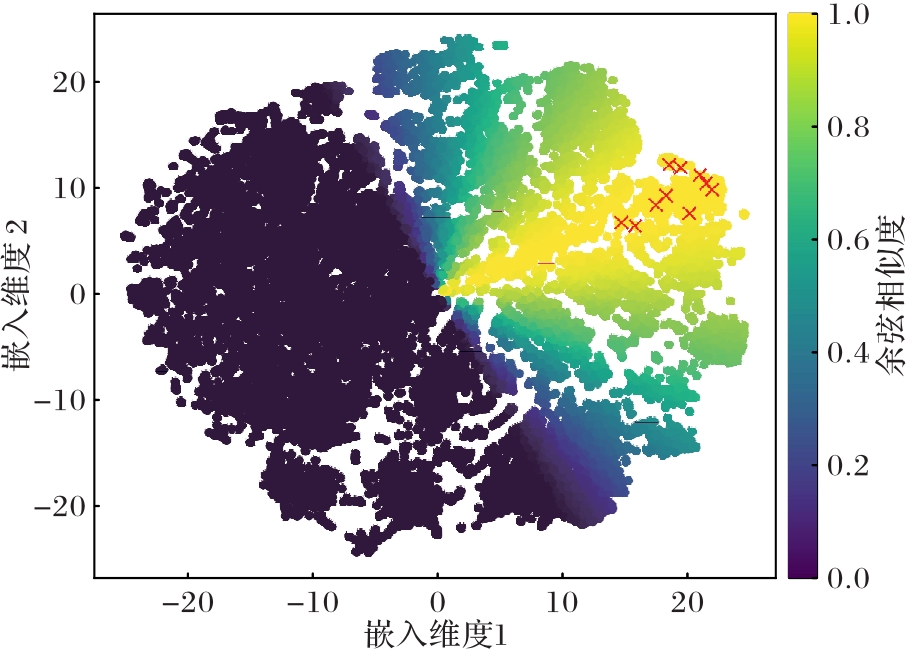
Fig. 7 Embedding visualization of power work order dataset
| 方法 | AAPD | RCV1-V2 | ||||
|---|---|---|---|---|---|---|
| Micro-P | Micro-R | Micro-F1 | Micro-P | Micro-R | Micro-F1 | |
| LSAN | 77.7 | 64.6 | 70.6 | 91.3 | 84.1 | 87.5 |
| SGM | 74.8 | 67.5 | 71.0 | 89.7 | 86.0 | 87.8 |
| Seq2Set | 73.9 | 67.4 | 70.5 | 90.0 | 85.8 | 87.9 |
| BERT | 78.6 | 68.7 | 73.4 | 92.7 | 83.2 | 87.7 |
| RoBERTta | 80.2 | 67.8 | 73.5 | 89.0 | 84.6 | 86.8 |
| LACO | 78.9 | 70.8 | 74.7 | 90.8 | 85.6 | 88.1 |
| SCL | 74.9 | 73.2 | 74.0 | 88.1 | 87.1 | 87.6 |
| 本文方法 | 75.9 | 74.4 | 75.2 | 89.4 | 87.6 | 88.5 |
Tab.6 Results of different methods on AAPD and RCV1-V2 datasets
| 方法 | AAPD | RCV1-V2 | ||||
|---|---|---|---|---|---|---|
| Micro-P | Micro-R | Micro-F1 | Micro-P | Micro-R | Micro-F1 | |
| LSAN | 77.7 | 64.6 | 70.6 | 91.3 | 84.1 | 87.5 |
| SGM | 74.8 | 67.5 | 71.0 | 89.7 | 86.0 | 87.8 |
| Seq2Set | 73.9 | 67.4 | 70.5 | 90.0 | 85.8 | 87.9 |
| BERT | 78.6 | 68.7 | 73.4 | 92.7 | 83.2 | 87.7 |
| RoBERTta | 80.2 | 67.8 | 73.5 | 89.0 | 84.6 | 86.8 |
| LACO | 78.9 | 70.8 | 74.7 | 90.8 | 85.6 | 88.1 |
| SCL | 74.9 | 73.2 | 74.0 | 88.1 | 87.1 | 87.6 |
| 本文方法 | 75.9 | 74.4 | 75.2 | 89.4 | 87.6 | 88.5 |
| [1] | 任莹. 基于预训练BERT模型的客服工单自动分类研究[J]. 云南电力技术, 2020, 48(1): 2-7, 11. |
| REN Y. Power grid a classification model of power work orders texts based on pre-trained BERT model[J]. Yunnan Electric Power, 2020, 48(1): 2-7, 11. | |
| [2] | 蔡颖凯,曹世龙,张冶,等. 应用BERT和BiGRU-AT的电力营销客服工单分类模型[J]. 微型电脑应用, 2023, 39(4): 6-9. |
| CAI Y K, CAO S L, ZHANG Z, et al. Work order classification model of power marketing customer service by BERT and BiGRU-AT[J]. Microcomputer Applications, 2023, 39(4): 6-9. | |
| [3] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [4] | 黄秀彬,许世辉,赵阳,等. 基于ResNet-BiLSTM模型的电力客服工单分类研究[J]. 电子设计工程, 2022, 30(22): 179-183. |
| HUANG X B, XU S H, ZHAO Y, et al. Research on power system customer service tickets classification based on ResNet-BiLSTM model[J]. Electronic Design Engineering, 2022, 30(22): 179-183. | |
| [5] | 李嘉欣,莫思特. 基于MiniRBT-LSTM-GAT与标签平滑的台区电力工单分类[J]. 计算机应用, 2025, 45(4): 1356-1362. |
| LI J X, MO S T. Power work orders classification in substation areas based on MiniRBT-LSTM-GAT and label smoothing[J]. Journal of Computer Applications, 2025, 45(4): 1356-1362. | |
| [6] | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. [2024-06-19].. |
| [7] | LIANG X, WU L, LI J, et al. R-Drop: regularized dropout for neural networks[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 10890-10905. |
| [8] | ZHANG M L, ZHOU Z H. ML-KNN: a lazy learning approach to multi-label learning[J]. Pattern Recognition, 2007, 40(7): 2038-2048. |
| [9] | CHEN G, YE D, XING Z, et al. Ensemble application of convolutional and recurrent neural networks for multi-label text categorization[C]// Proceedings of the 2017 International Joint Conference on Neural Networks. Piscataway: IEEE, 2017: 2377-2383. |
| [10] | YANG P, SUN X, LI W, et al. SGM: sequence generation model for multi-label classification[C]// Proceedings of the 27th International Conference on Computational Linguistics. Stroudsburg: ACL, 2018: 3915-3926. |
| [11] | YOU R, ZHANG Z, WANG Z, et al. AttentionXML: label tree-based attention-aware deep model for high-performance extreme multi-label text classification[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 5820-5830. |
| [12] | LIU N, WANG Q, REN J. Label-embedding bi-directional attentive model for multi-label text classification[J]. Neural Processing Letters, 2021, 53(1): 375-389. |
| [13] | LIU W, PANG J, LI N, et al. Research on multi-label text classification method based on tALBERT-CNN[J]. International Journal of Computational Intelligence Systems, 2021, 14: No.201. |
| [14] | JIANG T, WANG D, SUN L, et al. LightXML: Transformer with dynamic negative sampling for high-performance extreme multi-label text classification[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 7987-7994. |
| [15] | ZHANG Q W, ZHANG X, YAN Z, et al. Correlation-guided representation for multi-label text classification[C]// Proceedings of the 30th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2021: 3363-3369. |
| [16] | ALHUZALI H, ANANIADOU S. SpanEmo: casting multi-label emotion classification as span-prediction[C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Stroudsburg: ACL, 2021: 1573-1584. |
| [17] | 黄靖,陶竹林,杜晓宇,等. 基于特征融合动态图网络的多标签文本分类算法[J]. 软件学报, 2025, 36(7): 3239-3252. |
| HUANG J, TAO Z L, DU X Y, et al. Multi-label text classification method based on feature-fused dynamic graph network[J]. Journal of Software, 2025, 36(7): 3239-3252. | |
| [18] | 王旭阳,卢世红. 基于标签构建与特征融合的多标签文本分类研究方法[J]. 贵州师范大学学报(自然科学版), 2025, 43(1): 105-114. |
| WANG X Y, LU S H. Research methodology of multi-label text classification based on label construction and feature fusion[J]. Journal of Guizhou Normal University (Natural Sciences), 2025, 43(1): 105-114. | |
| [19] | CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 1597-1607. |
| [20] | KHOSLA P, TETERWAK P, WANG C, et al. Supervised contrastive learning[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 18661-18673. |
| [21] | LIN N, QIN G, WANG G, et al. An effective deployment of contrastive learning in multi-label text classification [C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 8730-8744. |
| [22] | ZHANG S, XU R, XIONG C, et al. Use all the labels: a hierarchical multi-label contrastive learning framework[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 16639-16648. |
| [23] | SU X, WANG R, DAI X. Contrastive learning-enhanced nearest neighbor mechanism for multi-label text classification[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg: ACL, 2022: 672-679. |
| [24] | ZHANG P, WU M. Multi-label supervised contrastive learning[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 16786-16793. |
| [25] | VAN DEN OORD A, LI Y, VINYALS O. Representation learning with contrastive predictive coding[EB/OL]. [2024-06-19].. |
| [26] | LEWIS D D, YANG Y, ROSE T G, et al. RCV1: a new benchmark collection for text categorization research[J]. Journal of Machine Learning Research, 2004, 5: 361-397. |
| [27] | XIAO L, HUANG X, CHEN B, et al. Label-specific document representation for multi-label text classification[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 466-475. |
| [28] | YANG P, LUO F, MA S, et al. A deep reinforced sequence-to-set model for multi-label classification[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 5252-5258. |
| [1] | Ziyang CHENG, Ruizhang HUANG, Jingjing XUE. Deep evolutionary topic clustering model [J]. Journal of Computer Applications, 2026, 46(1): 85-94. |
| [2] | Wen LI, Kairong LI, Kai YANG. Subgraph-aware contrastive learning with data augmentation [J]. Journal of Computer Applications, 2026, 46(1): 1-9. |
| [3] | Xingyao YANG, Zheng QI, Jiong YU, Zulian ZHANG, Shuai MA, Hongtao SHEN. Session-based recommendation model based on time-aware and space-enhanced dual channel graph neural network [J]. Journal of Computer Applications, 2026, 46(1): 104-112. |
| [4] | Chao LIU, Yanhua YU. Knowledge-aware recommendation model combining denoising strategy and multi-view contrastive learning [J]. Journal of Computer Applications, 2025, 45(9): 2827-2837. |
| [5] | Zhixiong XU, Bo LI, Xiaoyong BIAN, Qiren HU. Adversarial sample embedded attention U-Net for 3D medical image segmentation [J]. Journal of Computer Applications, 2025, 45(9): 3011-3016. |
| [6] | Jiaxiang ZHANG, Xiaoming LI, Jiahui ZHANG. Few-shot object detection algorithm based on new category feature enhancement and metric mechanism [J]. Journal of Computer Applications, 2025, 45(9): 2984-2992. |
| [7] | Zhiyuan WANG, Tao PENG, Jie YANG. Integrating internal and external data for out-of-distribution detection training and testing [J]. Journal of Computer Applications, 2025, 45(8): 2497-2506. |
| [8] | Wei ZHANG, Jiaxiang NIU, Jichao MA, Qiongxia SHEN. Chinese spelling correction model ReLM enhanced with deep semantic features [J]. Journal of Computer Applications, 2025, 45(8): 2484-2490. |
| [9] | Jin XIE, Surong CHU, Yan QIANG, Juanjuan ZHAO, Hua ZHANG, Yong GAO. Dual-branch distribution consistency contrastive learning model for hard negative sample identification in chest X-rays [J]. Journal of Computer Applications, 2025, 45(7): 2369-2377. |
| [10] | Haoyu LIU, Pengwei KONG, Yaoli WANG, Qing CHANG. Pedestrian detection algorithm based on multi-view information [J]. Journal of Computer Applications, 2025, 45(7): 2325-2332. |
| [11] | Zhenzhou WANG, Fangfang GUO, Jingfang SU, He SU, Jianchao WANG. Robustness optimization method of visual model for intelligent inspection [J]. Journal of Computer Applications, 2025, 45(7): 2361-2368. |
| [12] | Wenjing YAN, Ruidong WANG, Min ZUO, Qingchuan ZHANG. Recipe recommendation model based on hierarchical learning of flavor embedding heterogeneous graph [J]. Journal of Computer Applications, 2025, 45(6): 1869-1878. |
| [13] | Mingfeng YU, Yongbin QIN, Ruizhang HUANG, Yanping CHEN, Chuan LIN. Multi-label text classification method based on contrastive learning enhanced dual-attention mechanism [J]. Journal of Computer Applications, 2025, 45(6): 1732-1740. |
| [14] | Chaoying JIANG, Qian LI, Ning LIU, Lei LIU, Lizhen CUI. Readmission prediction model based on graph contrastive learning [J]. Journal of Computer Applications, 2025, 45(6): 1784-1792. |
| [15] | Yufei LONG, Yuchen MOU, Ye LIU. Multi-source data representation learning model based on tensorized graph convolutional network and contrastive learning [J]. Journal of Computer Applications, 2025, 45(5): 1372-1378. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||