


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (7): 2055-2064.DOI: 10.11772/j.issn.1001-9081.2023060749
• Artificial intelligence • Previous Articles Next Articles
Tian MA1, Runtao XI1,2,3, Jiahao LYU1,4( ), Yijie ZENG1, Jiayi YANG1, Jiehui ZHANG1
), Yijie ZENG1, Jiayi YANG1, Jiehui ZHANG1
Received:2023-06-15
Revised:2023-08-19
Accepted:2023-08-24
Online:2023-09-11
Published:2024-07-10
Contact:
Jiahao LYU
About author:MA Tian, born in 1982, Ph. D., associate professor. His research interests include graphics and image processing, data visualization.Supported by:
马天1, 席润韬1,2,3, 吕佳豪1,4(), 曾奕杰1, 杨嘉怡1, 张杰慧1
通讯作者:
吕佳豪
作者简介:马天(1982—),男,河南商丘人,副教授,博士,CCF高级会员,主要研究方向:图形图像处理、数据可视化;基金资助:CLC Number:
Tian MA, Runtao XI, Jiahao LYU, Yijie ZENG, Jiayi YANG, Jiehui ZHANG. Mobile robot 3D space path planning method based on deep reinforcement learning[J]. Journal of Computer Applications, 2024, 44(7): 2055-2064.
马天, 席润韬, 吕佳豪, 曾奕杰, 杨嘉怡, 张杰慧. 基于深度强化学习的移动机器人三维路径规划方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2055-2064.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023060749
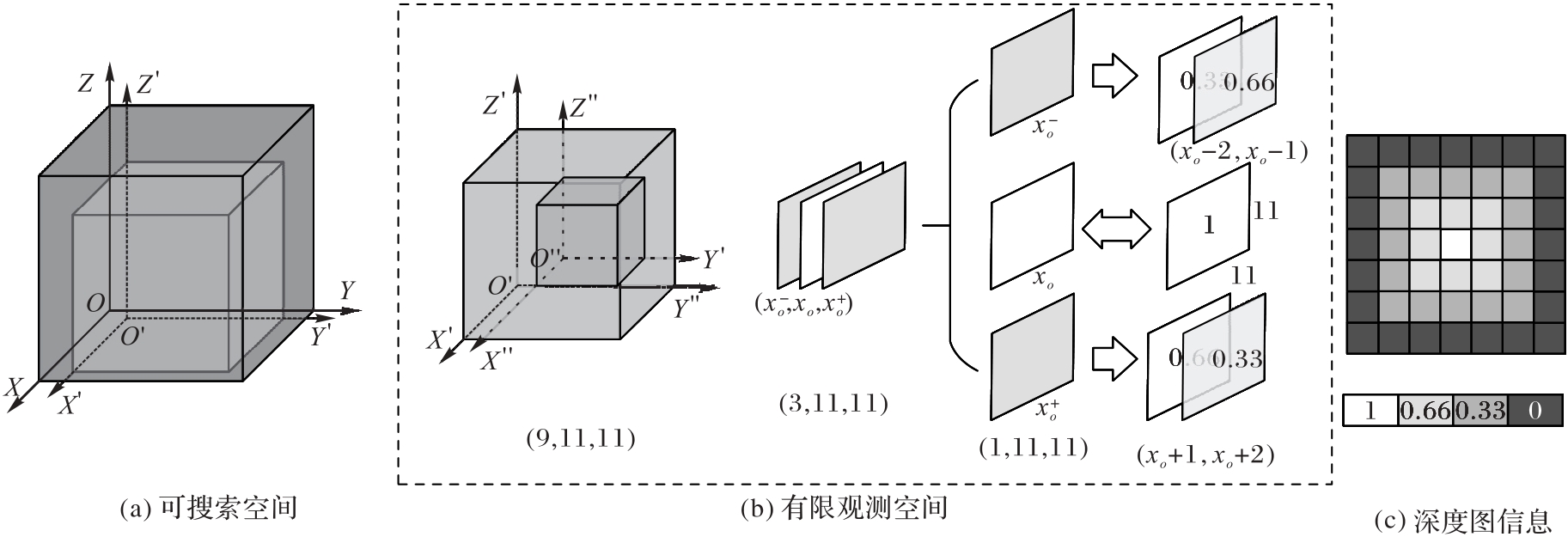
Fig. 1 Overview of 3D simulation environment modeling in different coordinate systems
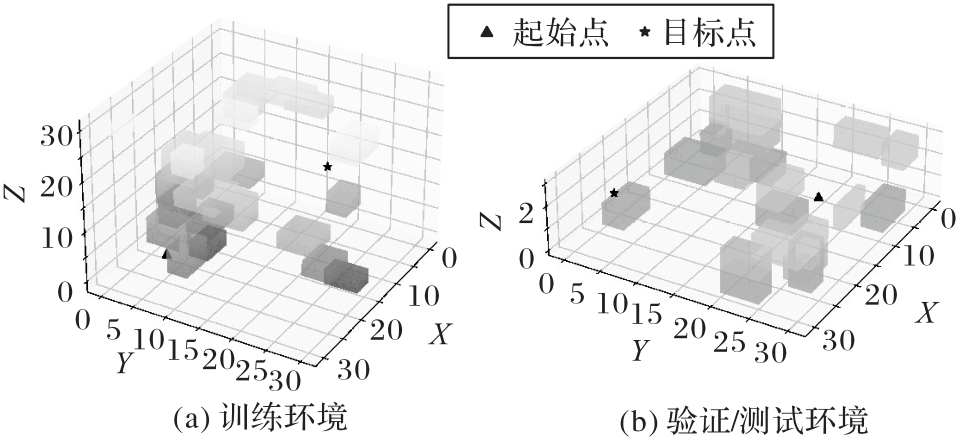
Fig. 2 Modeling diagrams of two simulation environments
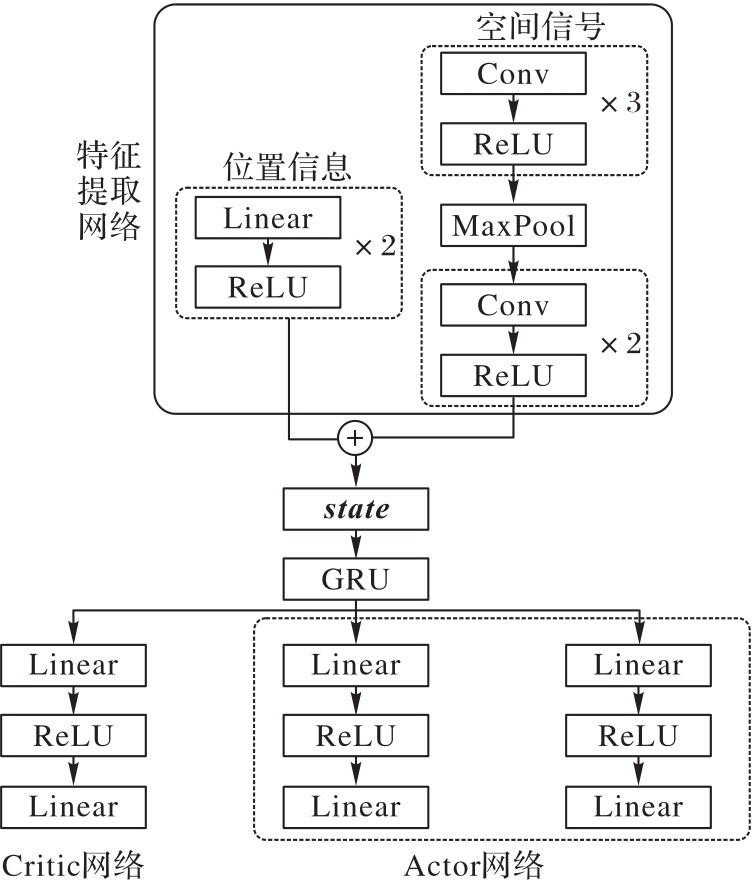
Fig. 3 Network model design
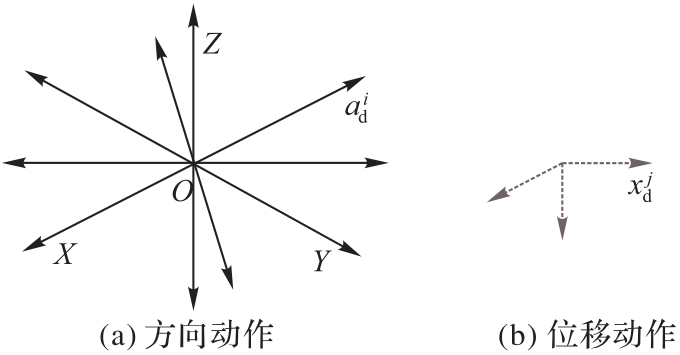
Fig. 4 Two-stage discrete action space
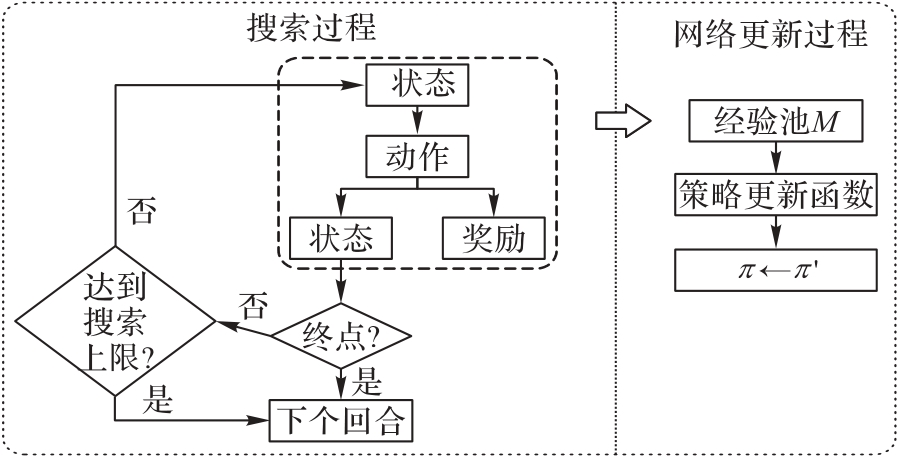
Fig. 5 Schematic diagram of training and testing processes
| 参数 | 值 | 含义 | 参数 | 值 | 含义 |
|---|---|---|---|---|---|
| 最大训练搜索步数 | 0.98 | 衰减因子 | |||
| 500 | 单回合搜索步数 | 0.25 | 优势函数裁剪因子 | ||
| 8 192 | 总批次大小 | 0.000 3 | 网络参数学习率 | ||
| 128 | 小批次大小 | 0.03 | 策略熵 | ||
| 2 | 数据复用次数 | 0.004 | 策略熵衰减因子 |
Tab. 1 Hyperparameter design of proposed method
| 参数 | 值 | 含义 | 参数 | 值 | 含义 |
|---|---|---|---|---|---|
| 最大训练搜索步数 | 0.98 | 衰减因子 | |||
| 500 | 单回合搜索步数 | 0.25 | 优势函数裁剪因子 | ||
| 8 192 | 总批次大小 | 0.000 3 | 网络参数学习率 | ||
| 128 | 小批次大小 | 0.03 | 策略熵 | ||
| 2 | 数据复用次数 | 0.004 | 策略熵衰减因子 |
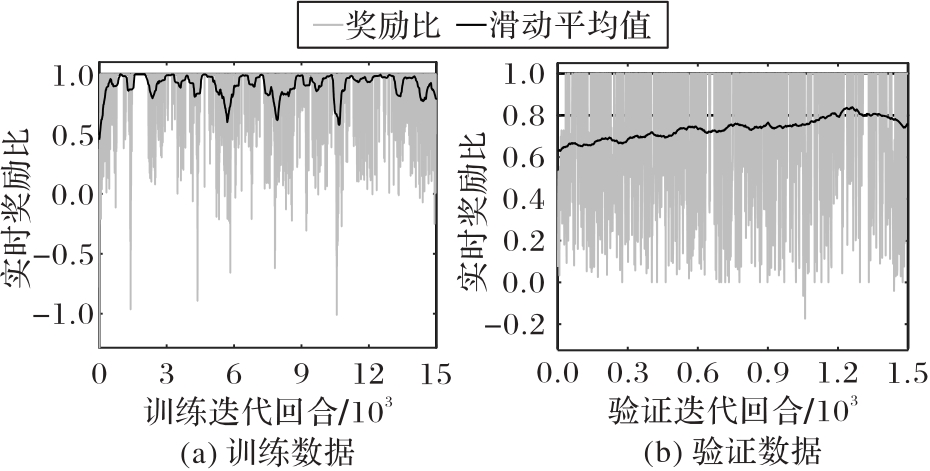
Fig. 6 Real-time reward ratio during training

Fig. 7 Path planning results in different environments
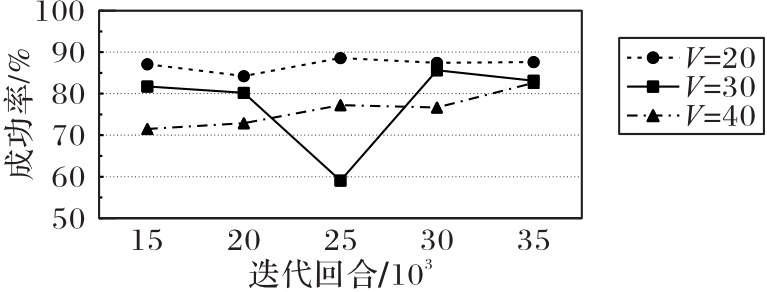
Fig. 8 Success rate of proposed method
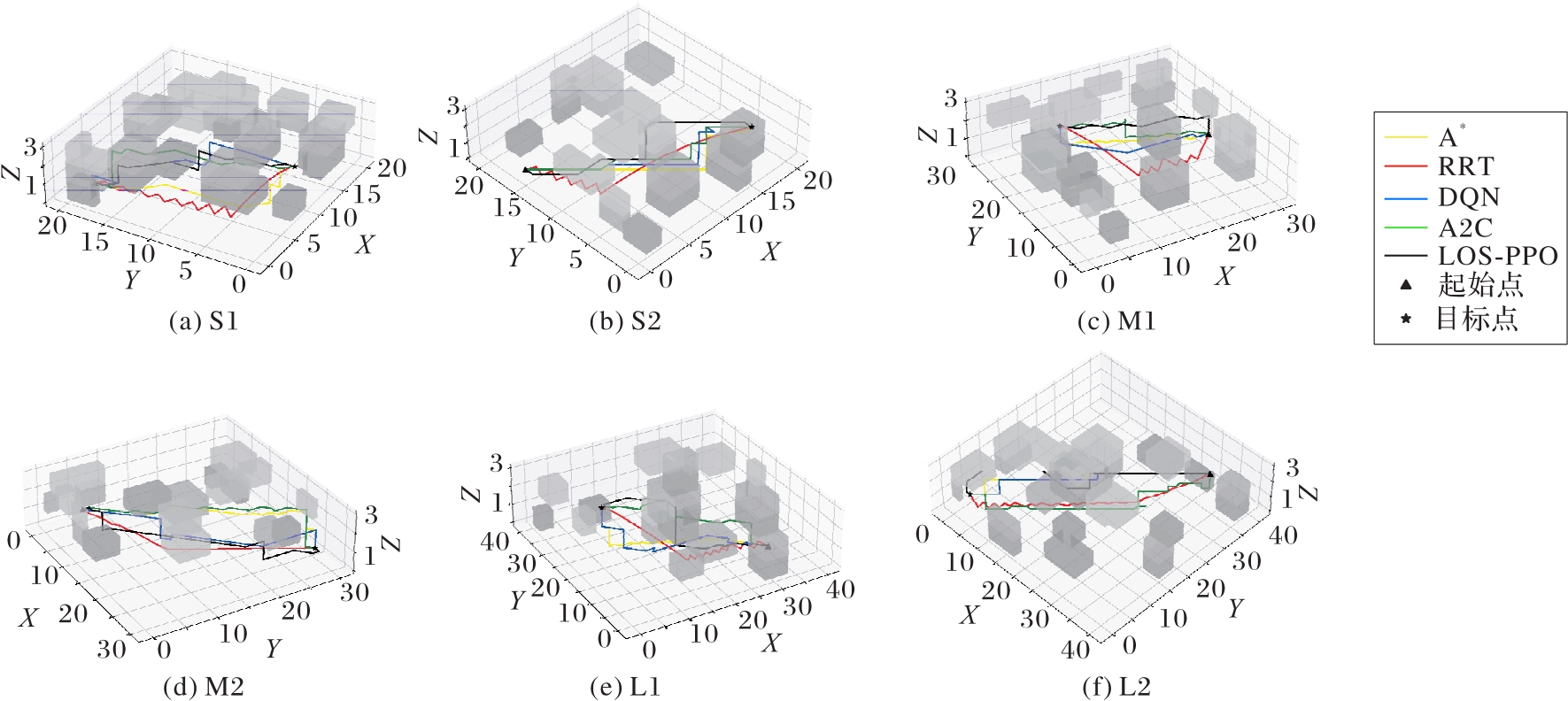
Fig. 9 Overall visualization results of different algorithms in different environments
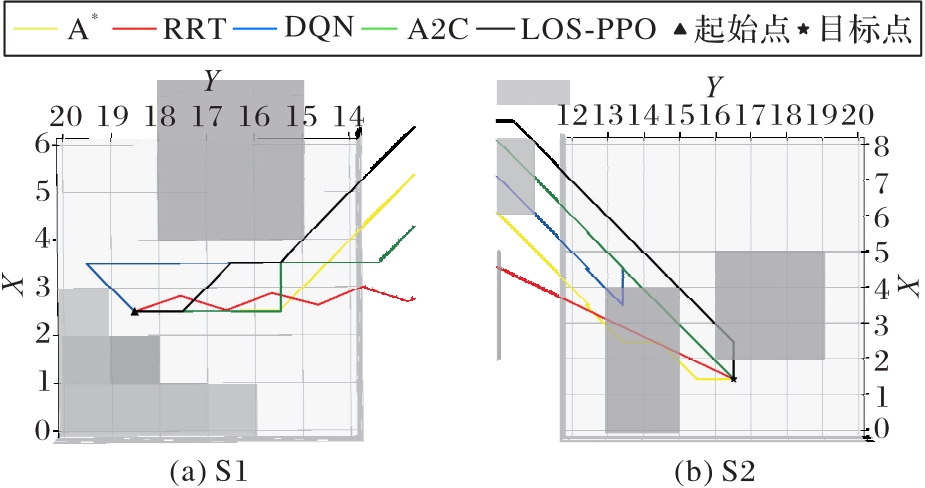
Fig. 10 Enlarged view of local environment
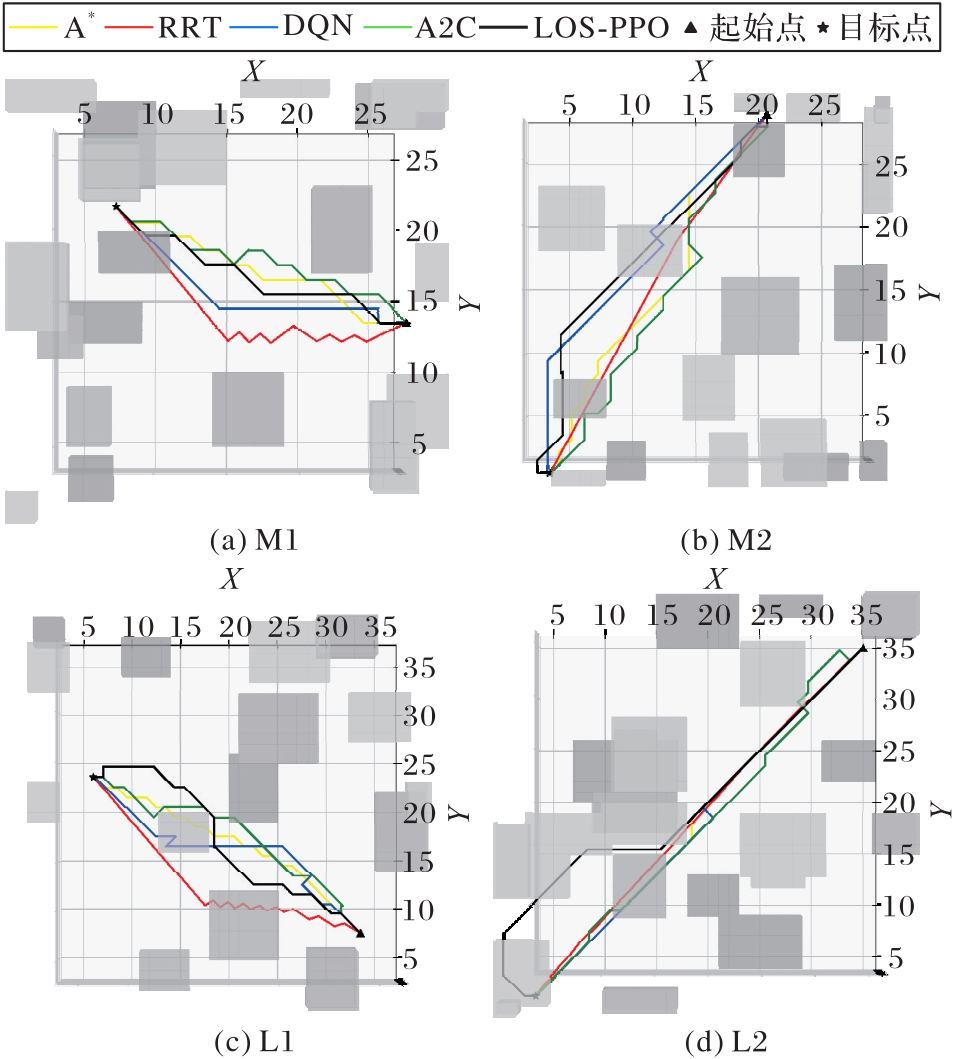
Fig. 11 Enlarged view of overlook environment
| 地图 | 搜索时间/s | 路径长度/unit | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 已知环境 | 未知环境 | 已知环境 | 未知环境 | |||||||
| A* | RRT | DQN | A2C | LOS-PPO | A* | RRT | DQN | A2C | LOS-PPO | |
| S1 | 0.031 | 0.428 | 0.183 | 0.670 | 0.543 | 22.48 | 23.09 | 25.07 | 23.07 | 22.48 |
| S2 | 0.024 | 2.387 | 0.186 | 0.742 | 0.283 | 23.79 | 25.33 | 25.21 | 23.79 | 24.97 |
| M1 | 0.027 | 1.122 | 0.143 | 0.880 | 0.312 | 24.31 | 27.40 | 24.89 | 25.14 | 24.31 |
| M2 | 0.106 | 1.313 | 0.311 | 1.512 | 0.573 | 37.04 | 33.01 | 37.87 | 38.45 | 39.04 |
| L1 | 0.097 | 2.403 | 0.377 | 1.062 | 0.621 | 35.62 | 37.00 | 39.62 | 39.87 | 38.79 |
| L2 | 0.023 | 3.520 | 0.263 | 1.239 | 0.676 | 46.84 | 46.61 | 47.66 | 55.91 | 53.59 |
Tab. 2 Performance analysis of different algorithms in static environment
| 地图 | 搜索时间/s | 路径长度/unit | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 已知环境 | 未知环境 | 已知环境 | 未知环境 | |||||||
| A* | RRT | DQN | A2C | LOS-PPO | A* | RRT | DQN | A2C | LOS-PPO | |
| S1 | 0.031 | 0.428 | 0.183 | 0.670 | 0.543 | 22.48 | 23.09 | 25.07 | 23.07 | 22.48 |
| S2 | 0.024 | 2.387 | 0.186 | 0.742 | 0.283 | 23.79 | 25.33 | 25.21 | 23.79 | 24.97 |
| M1 | 0.027 | 1.122 | 0.143 | 0.880 | 0.312 | 24.31 | 27.40 | 24.89 | 25.14 | 24.31 |
| M2 | 0.106 | 1.313 | 0.311 | 1.512 | 0.573 | 37.04 | 33.01 | 37.87 | 38.45 | 39.04 |
| L1 | 0.097 | 2.403 | 0.377 | 1.062 | 0.621 | 35.62 | 37.00 | 39.62 | 39.87 | 38.79 |
| L2 | 0.023 | 3.520 | 0.263 | 1.239 | 0.676 | 46.84 | 46.61 | 47.66 | 55.91 | 53.59 |
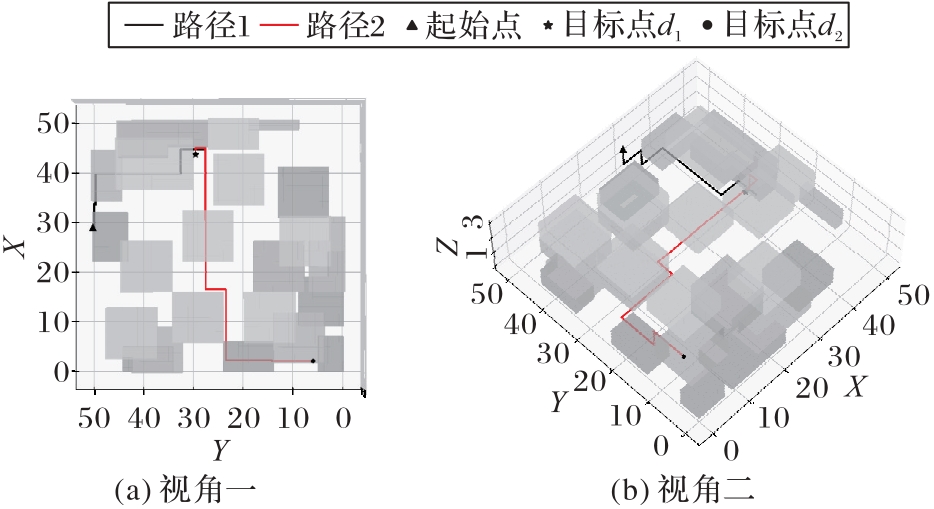
Fig. 12 Multi-target path visualization under logic ?1
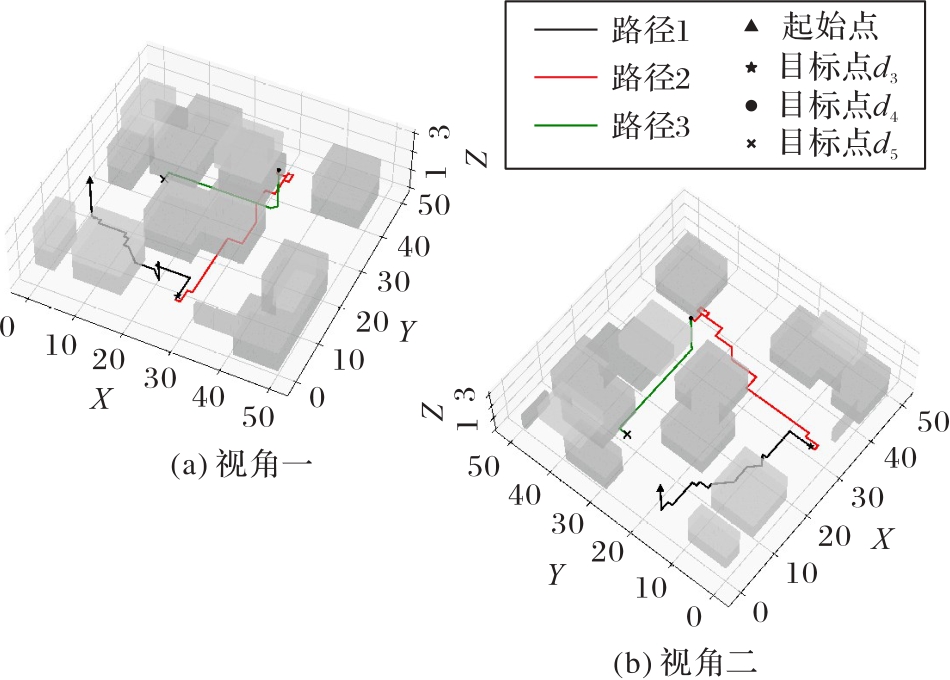
Fig. 13 Multi-target path visualization under logic ?2
| 1 | 申彦,邹猛,党兆龙,等.火星车通过性评估技术现状与展望[J].光学精密工程, 2023, 31(5): 729-745. |
| SHEN Y, ZOU M, DANG Z L, et al. Trafficability analysis for Mars rover: present and development [J]. Optics and Precision Engineering, 2023, 31(5): 729-745. | |
| 2 | 劳彩莲,李鹏,冯宇.基于改进A*与DWA算法融合的温室机器人路径规划[J].农业机械学报, 2021, 52(1): 14-22. |
| LAO C L, LI P, FENG Y. Path planning of greenhouse robot based on fusion of improved A* algorithm and dynamic window approach [J]. Transactions of the Chinese Society for Agricultural Machinery, 2021, 52(1): 14-22. | |
| 3 | 葛世荣,胡而已,裴文良.煤矿机器人体系及关键技术[J].煤炭学报, 2020, 45(1): 455-463. |
| GE S R, HU E Y, PEI W L. Classification system and key technology of coal mine robot [J]. Journal of China Coal Society, 2020, 45(1): 455-463. | |
| 4 | 王洪斌,尹鹏衡,郑维,等.基于改进的A*算法与动态窗口法的移动机器人路径规划[J].机器人, 2020, 42(3): 346-353. |
| WANG H B, YIN P H, ZHENG W, et al. Mobile robot path planning based on improved A* algorithm and dynamic window method [J]. Robot, 2020, 42(3): 346-353. | |
| 5 | MA T, LYU J, YANG J, et al. CLSQL: improved q-learning algorithm based on continuous local search policy for mobile robot path planning [J]. Sensors, 2022, 22(15): 5910. |
| 6 | HU J, HU Y, LU C, et al. Integrated path planning for unmanned differential steering vehicles in off-road environment with 3D terrains and obstacles [J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 23(6): 5562-5572. |
| 7 | JOSEF S, DEGANI A. Deep reinforcement learning for safe local planning of a ground vehicle in unknown rough terrain [J]. IEEE Robotics and Automation Letters, 2020, 5(4): 6748-6755. |
| 8 | WERMELINGER M, FANKHAUSER P, DIETHELM R, et al. Navigation planning for legged robots in challenging terrain [C]// Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots & Systems. Piscataway: IEEE, 2016: 1184-1189. |
| 9 | DELMERICO J, MUEGGLER E, NITSCH J, et al. Active autonomous aerial exploration for ground robot path planning [J]. IEEE Robotics and Automation Letters, 2017, 2(2): 664-671. |
| 10 | COLAS F, MAHESH S, POMERLEAU F, et al. 3D path planning and execution for search and rescue ground robots [C]// Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2013: 722-727. |
| 11 | 刘峰,曹文君,张建明,等.我国煤炭工业科技创新进展及“十四五”发展方向[J].煤炭学报, 2021, 46(1): 1-15. |
| LIU F, CAO W J, ZHANG J M, et al. Current technological innovation and development direction of the 14th Five Year Plan period in China coal industry [J]. Journal of China Coal Society, 2021, 46(1): 1-15. | |
| 12 | 张伟民,张月,张辉.基于改进A*算法的煤矿救援机器人路径规划[J].煤田地质与勘探, 2022, 50(12): 185-193. |
| ZHANG W M, ZHANG Y, ZHANG H. Path planning of coal mine rescue robot based on improved A* algorithm [J]. Coal Geology & Exploration, 2022, 50(12): 185-193. | |
| 13 | 辛鹏,王艳辉,刘晓立,等.优化改进RRT和人工势场法的路径规划算法[J/OL].计算机集成制造系统: 1-14[2023-05-26]. . |
| XIN P, WANG Y H, LIU X L, et al. Path planning algorithm based on optimize and improve RRT and artificial potential field [J/OL]. Computer Integrated Manufacturing Systems: 1-14[2023-05-26]. . | |
| 14 | FUNK N, MENZENBACH S, CHALVATZAKI G, et al. Graph-based reinforcement learning meets mixed integer programs: an application to 3D robot assembly discovery [EB/OL]. [2022-03-08]. . |
| 15 | JIANG J, ZENG X, GUZZETTI D, et al. Path planning for asteroid hopping rovers with pre-trained deep reinforcement learning architectures [J]. Acta Astronautica, 2020, 171: 265-279. |
| 16 | SEMNANI S H, LIU H, EVERETT M, et al. Multi-agent motion planning for dense and dynamic environments via deep reinforcement learning [EB/OL]. [2020-01-18]. . |
| 17 | ZENG Y, XU X, JIN S, et al. Simultaneous navigation and radio mapping for cellular-connected UAV with deep reinforcement learning [J]. IEEE Transactions on Wireless Communications, 2021, 20(7): 4205-4220. |
| 18 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning [EB/OL]. [2013-12-19]. . |
| 19 | ZHANG K, NIROUI F, FICOCELLI M, et al. Robot navigation of environments with unknown rough terrain using deep reinforcement learning [C]// Proceedings of the 2018 IEEE International Symposium on Safety, Security, and Rescue Robotics. Piscataway: IEEE, 2018: 1-7. |
| 20 | HU H, ZHANG K, TAN A H, et al. A sim-to-real pipeline for deep reinforcement learning for autonomous robot navigation in cluttered rough terrain [J]. IEEE Robotics and Automation Letters, 2021, 6(4): 6569-6576. |
| 21 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms [EB/OL]. (2017-08-28) [2023-05-01]. . |
| 22 | SCHULMAN J, LEVINE S, MORITZ P, et al. Trust region policy optimization [C]// Proceedings of the 32 nd International Conference on Machine Learning. New York: JMLR.org, 2015: 1889-1897. |
| 23 | 冯笑冰,朱登明,王兆其.基于深度图的水面重建[J].高技术通讯, 2020, 30(3): 223-232. |
| FENG X B, ZHU D M, WANG Z Q. Depth image based fluid reconstruction [J]. High Technology Letters, 2020, 30(3): 223-232. | |
| 24 | ZHANG S, LI Y, DONG Q. Autonomous navigation of UAV in multi-obstacle environments based on a deep reinforcement learning approach [J]. Applied Soft Computing, 2022, 115: 108194. |
| 25 | MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning [C]// Proceedings of the 33 rd International Conference on Machine Learning. New York: JMLR.org, 2016: 1928-1937. |
| 26 | ROZIER K Y. Linear temporal logic symbolic model checking [J]. Computer Science Review, 2011, 5(2): 163-203. |
| [1] | Yi ZHOU, Hua GAO, Yongshen TIAN. Proximal policy optimization algorithm based on clipping optimization and policy guidance [J]. Journal of Computer Applications, 2024, 44(8): 2334-2341. |
| [2] | Ying HU, Zhihuan CHEN. Trajectory tracking control of wheeled mobile robots under side-slip and slip [J]. Journal of Computer Applications, 2024, 44(7): 2294-2300. |
| [3] | Xiaoyan ZHAO, Wei HAN, Junna ZHANG, Peiyan YUAN. Collaborative offloading strategy in internet of vehicles based on asynchronous deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(5): 1501-1510. |
| [4] | Yanxin GE, Tao YAN, Jiangfeng ZHANG, Xiaoying GUO, Bin CHEN. 3D shape reconstruction with spatial correlation based on spatio-temporal attention [J]. Journal of Computer Applications, 2024, 44(5): 1570-1578. |
| [5] | Rui TANG, Chuanlin PANG, Ruizhi ZHANG, Chuan LIU, Shibo YUE. DDPG-based resource allocation in D2D communication-empowered cellular network [J]. Journal of Computer Applications, 2024, 44(5): 1562-1569. |
| [6] | Xintong QIN, Zhengyu SONG, Tianwei HOU, Feiyue WANG, Xin SUN, Wei LI. Channel access and resource allocation algorithm for adaptive p-persistent mobile ad hoc network [J]. Journal of Computer Applications, 2024, 44(3): 863-868. |
| [7] | Yuanchao LI, Chongben TAO, Chen WANG. Gait control method based on maximum entropy deep reinforcement learning for biped robot [J]. Journal of Computer Applications, 2024, 44(2): 445-451. |
| [8] | Fuqin DENG, Huifeng GUAN, Chaoen TAN, Lanhui FU, Hongmin WANG, Tinlun LAM, Jianmin ZHANG. Multi-robot reinforcement learning path planning method based on request-response communication mechanism and local attention mechanism [J]. Journal of Computer Applications, 2024, 44(2): 432-438. |
| [9] | Jiachen YU, Ye YANG. Irregular object grasping by soft robotic arm based on clipped proximal policy optimization algorithm [J]. Journal of Computer Applications, 2024, 44(11): 3629-3638. |
| [10] | Enbao QIAO, Xiangyang GAO, Jun CHENG. Self-recovery adaptive Monte Carlo localization algorithm based on support vector machine [J]. Journal of Computer Applications, 2024, 44(10): 3246-3251. |
| [11] | Jie LONG, Liang XIE, Haijiao XU. Integrated deep reinforcement learning portfolio model [J]. Journal of Computer Applications, 2024, 44(1): 300-310. |
| [12] | Dongying ZHU, Yong ZHONG, Guanci YANG, Yang LI. Research progress on motion segmentation of visual localization and mapping in dynamic environment [J]. Journal of Computer Applications, 2023, 43(8): 2537-2545. |
| [13] | Yu WANG, Tianjun REN, Zilin FAN. Air combat maneuver decision-making of unmanned aerial vehicle based on guided Minimax-DDQN [J]. Journal of Computer Applications, 2023, 43(8): 2636-2643. |
| [14] | Ziteng WANG, Yaxin YU, Zifang XIA, Jiaqi QIAO. Sparse reward exploration mechanism fusing curiosity and policy distillation [J]. Journal of Computer Applications, 2023, 43(7): 2082-2090. |
| [15] | Xiaolin LI, Yusang JIANG. Task offloading algorithm for UAV-assisted mobile edge computing [J]. Journal of Computer Applications, 2023, 43(6): 1893-1899. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||