


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (1): 234-239.DOI: 10.11772/j.issn.1001-9081.2024010004
• Multimedia computing and computer simulation • Previous Articles Next Articles
Lifang WANG1( ), Jingshuang WU1, Pengliang YIN2, Lihua HU1
), Jingshuang WU1, Pengliang YIN2, Lihua HU1
Received:2024-01-10
Revised:2024-03-15
Accepted:2024-03-21
Online:2024-05-09
Published:2025-01-10
Contact:
Lifang WANG
About author:WU Jingshuang, born in 1998, M. S. candidate. Her research interests include computer vision, action recognition.Supported by:
王丽芳1(), 吴荆双1, 尹鹏亮2, 胡立华1
通讯作者:
王丽芳
作者简介:王丽芳(1975—),女,山西和顺人,副教授,博士,CCF会员,主要研究方向:智能优化、图像处理;wanglifang@tyust.edu.cn基金资助:CLC Number:
Lifang WANG, Jingshuang WU, Pengliang YIN, Lihua HU. Action recognition algorithm based on attention mechanism and energy function[J]. Journal of Computer Applications, 2025, 45(1): 234-239.
王丽芳, 吴荆双, 尹鹏亮, 胡立华. 基于注意力机制和能量函数的动作识别算法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 234-239.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024010004
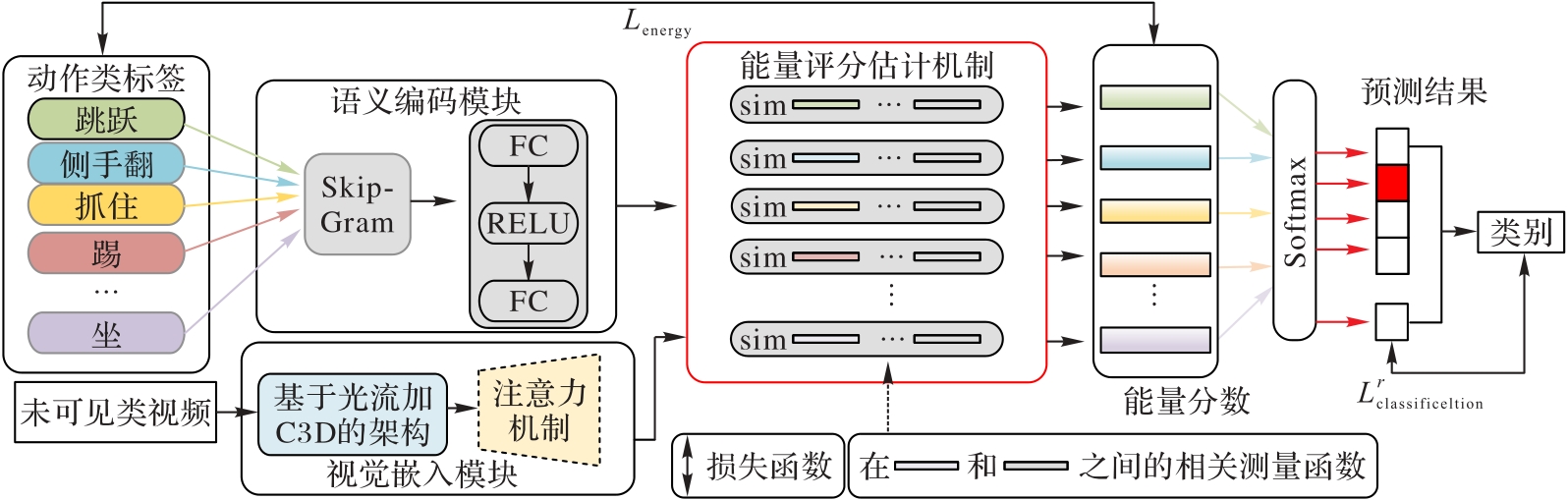
Fig. 1 Overall framework of ARAAE
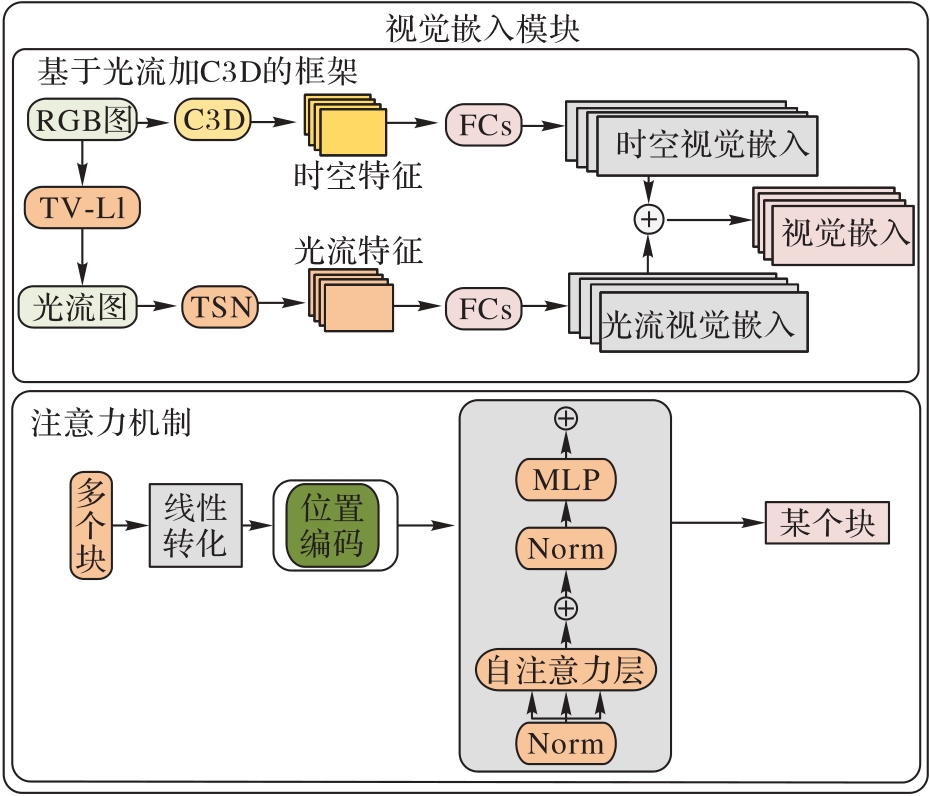
Fig. 2 Structure of visual embedding module of ARAAE
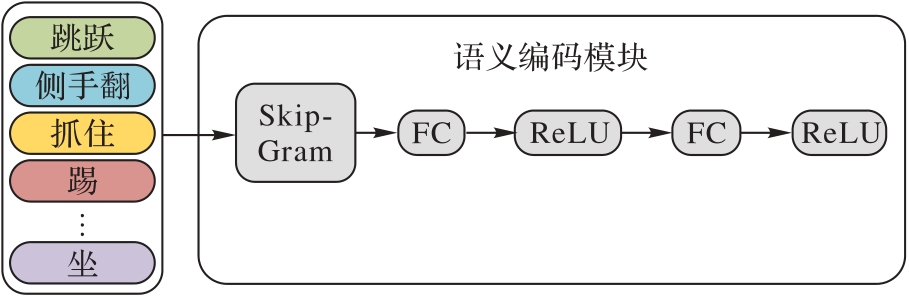
Fig. 3 Structure of semantic coding module of ARAAE
| 软件 | 说明 |
|---|---|
| PyTorch 1.9 | 计算深度学习的平台 |
| Python 3.6 | 进行数据预处理,搭建算法框架 |
| OpenCV | 进行视频的预处理 |
| Gensim | 语义编码器 |
Tab. 1 Software configuration
| 软件 | 说明 |
|---|---|
| PyTorch 1.9 | 计算深度学习的平台 |
| Python 3.6 | 进行数据预处理,搭建算法框架 |
| OpenCV | 进行视频的预处理 |
| Gensim | 语义编码器 |
| 算法 | 视觉特征 | 语义特征 | HMDB51 (26/25) | UCF101 (51/50) | UCF101 (81/20) |
|---|---|---|---|---|---|
| SJE | L | WV | 13.3±2.4 | 9.9±1.4 | |
| MTE | D | WV | 19.7±1.6 | 15.8±1.3 | |
| ZSECOC | L | A | 3.2±0.7 | ||
| ZSECOC | L | WV | 16.5±3.9 | 13.7±0.5 | |
| BiDiLEL | D | A | 20.5±0.5 | 39.2±1.0 | |
| BiDiLEL | D | WV | 18.6±0.7 | 18.9±0.4 | 38.3±1.2 |
| GMM | D | WV | 19.3±2.1 | 17.3±1.1 | |
| TARN | D | WV | 19.5±4.2 | 19.0±2.3 | 36.0±5.3 |
| CAGE | D | WV | 20.8±2.9 | 12.9±1.8 | |
| Bi-dir GAN | D | WV | 17.5±2.4 | 17.2±2.3 | |
| ETSAN | D | WV | 20.6±1.6 | 39.4±2.1 | |
| ARAAE(本文) | D | A | 13.4±1.8 | 24.9±2.6 | |
| ARAAE(本文) | D | WV | 22.1±1.8 | 22.4±1.6 | 40.2±2.6 |
Tab. 2 Comparison of action recognition accuracy among different ZSAR algorithms on two datasets
| 算法 | 视觉特征 | 语义特征 | HMDB51 (26/25) | UCF101 (51/50) | UCF101 (81/20) |
|---|---|---|---|---|---|
| SJE | L | WV | 13.3±2.4 | 9.9±1.4 | |
| MTE | D | WV | 19.7±1.6 | 15.8±1.3 | |
| ZSECOC | L | A | 3.2±0.7 | ||
| ZSECOC | L | WV | 16.5±3.9 | 13.7±0.5 | |
| BiDiLEL | D | A | 20.5±0.5 | 39.2±1.0 | |
| BiDiLEL | D | WV | 18.6±0.7 | 18.9±0.4 | 38.3±1.2 |
| GMM | D | WV | 19.3±2.1 | 17.3±1.1 | |
| TARN | D | WV | 19.5±4.2 | 19.0±2.3 | 36.0±5.3 |
| CAGE | D | WV | 20.8±2.9 | 12.9±1.8 | |
| Bi-dir GAN | D | WV | 17.5±2.4 | 17.2±2.3 | |
| ETSAN | D | WV | 20.6±1.6 | 39.4±2.1 | |
| ARAAE(本文) | D | A | 13.4±1.8 | 24.9±2.6 | |
| ARAAE(本文) | D | WV | 22.1±1.8 | 22.4±1.6 | 40.2±2.6 |
| 算法 | HMDB51(26/25) | UCF101(51/50) | UCF101(81/20) |
|---|---|---|---|
| TRAN | 19.5±4.2 | 19.0±2.3 | 36.0±5.3 |
| ARAAE(O) | 17.9±1.2 | 15.3±2.2 | 33.1±5.6 |
| ARAAE(C) | 19.9±3.2 | 20.0±2.9 | 35.2±4.9 |
| ARAAE(w/o ViT) | 20.2±0.8 | 20.6±1.2 | 36.8±3.4 |
| ARAAE(w/o E) | 21.8±3.4 | 21.6±2.5 | 38.4±5.8 |
| ARAAE(本文) | 22.1±1.8 | 22.4±1.6 | 40.2±2.6 |
Tab. 3 Results of ablation experiments
| 算法 | HMDB51(26/25) | UCF101(51/50) | UCF101(81/20) |
|---|---|---|---|
| TRAN | 19.5±4.2 | 19.0±2.3 | 36.0±5.3 |
| ARAAE(O) | 17.9±1.2 | 15.3±2.2 | 33.1±5.6 |
| ARAAE(C) | 19.9±3.2 | 20.0±2.9 | 35.2±4.9 |
| ARAAE(w/o ViT) | 20.2±0.8 | 20.6±1.2 | 36.8±3.4 |
| ARAAE(w/o E) | 21.8±3.4 | 21.6±2.5 | 38.4±5.8 |
| ARAAE(本文) | 22.1±1.8 | 22.4±1.6 | 40.2±2.6 |
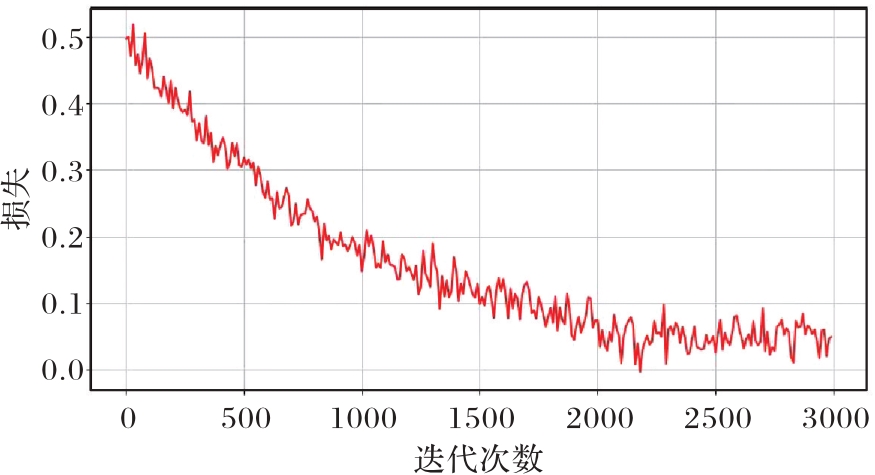
Fig. 4 Convergence analysis
| 1 | YANG L, PENG H, ZHANG D, et al. Revisiting anchor mechanisms for temporal action localization [J]. IEEE Transactions on Image Processing, 2020, 29: 8535-8548. |
| 2 | ZHAO T, HAN J, YANG L, et al. SODA: weakly supervised temporal action localization based on astute background response and self-distillation learning [J]. International Journal of Computer Vision, 2021, 129(8): 2474-2498. |
| 3 | WANG L, XIONG Y, WANG Z, et al. Temporal segment networks for action recognition in videos [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 41(11): 2740-2755. |
| 4 | 李永刚,王朝晖,万晓依,等.基于深度残差双单向DLSTM的时空一致视频事件识别[J].计算机学报, 2018, 41(12): 2852-2866. |
| LI Y G, WANG Z H, WAN X Y, et al. Deep residual dual unidirectional DLSTM for video event recognition with spatial-temporal consistency [J]. Chinese Journal of Computers, 2018, 41(12): 2852-2866. | |
| 5 | ESTEVAM V, PEDRINI H, MENOTTI D. Zero-shot action recognition in videos: a survey [J]. Neurocomputing, 2021, 439: 159-175. |
| 6 | HUYNH D, ELHAMIFAR E. A shared multi-attention framework for multi-label zero-shot learning [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 8773-8783. |
| 7 | PENG B, LEI J, FU H, et al. Deep video action clustering via spatio-temporal feature learning [J]. Neurocomputing, 2021, 456: 519-527. |
| 8 | LIU L, ZHOU T, LONG G, et al. Attribute propagation network for graph zero-shot learning [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 4868-4875. |
| 9 | KAMPFFMEYER M, CHEN Y, LIANG X, et al. Rethinking knowledge graph propagation for zero-shot learning [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 11479-11488. |
| 10 | HONG M, ZHANG X, LI G, et al. Multi-modal multi-grained embedding learning for generalized zero-shot video classification [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(10): 5959-5972. |
| 11 | LIN L, ZHANG J, LIU J. Actionlet-dependent contrastive learning for unsupervised skeleton-based action recognition [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 2363-2372. |
| 12 | GAO J, HOU Y, GUO Z, et al. Learning spatio-temporal semantics and cluster relation for zero-shot action recognition [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(11): 6519-6530. |
| 13 | YANG H, REN Z, YUAN H, et al. Contrastive self-supervised representation learning without negative samples for multimodal human action recognition [J]. Frontier in Neuroscience, 2023, 17: No.1225312. |
| 14 | XING M, FENG Z, SU Y, et al. Ventral & Dorsal Stream Theory based zero-shot action recognition [J]. Pattern Recognition, 2021, 116: No.107953. |
| 15 | QI C, FENG Z, XING M, et al. Energy-based temporal summarized attentive network for zero-shot action recognition [J]. IEEE Transactions on Multimedia, 2023, 25: 1940-1953. |
| 16 | LeCUN Y, CHOPRA S, HADSELL R, et al. A tutorial on energy-based learning [EB/OL]. [2023-10-05]. . |
| 17 | KAY W, CARREIRA J, SIMONYAN K, et al. The Kinetics human action video dataset [EB/OL]. [2023-09-10]. . |
| 18 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16 x16 words: Transformers for image recognition at scale [EB/OL]. [2023-10-02]. . |
| 19 | KUEHNE H, JHUANG H, GARROTE E, et al. HMDB: a large video database for human motion recognition [C]// Proceedings of the 2011 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2011: 2556-2563. |
| 20 | SOOMRO K, ZAMIR A R, SHAH M. UCF101: a dataset of 101 human actions classes from videos in the wild [EB/OL]. [2022-12-12]. . |
| 21 | MIKOLOV T, SUYSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality [C]// Proceedings of the 26th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2013: 3111-3119. |
| 22 | AKATA Z, REED S, WALTER D, et al. Evaluation of output embeddings for fine-grained image classification [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 2927-2936. |
| 23 | XU X, HOSPEDALES T M, GONG S. Multi-task zero-shot action recognition with prioritised data augmentation [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9906. Cham: Springer, 2016: 343-359. |
| 24 | QIN J, LIU L, SHAO L, et al. Zero-shot action recognition with error-correcting output codes [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1042-1051. |
| 25 | WANG Q, CHEN K. Zero-shot visual recognition via bidirectional latent embedding [J]. International Journal of Computer Vision, 2017, 124(3): 356-383. |
| 26 | MISHRA A, VERMA V K, REDDY M S K, et al. A generative approach to zero-shot and few-shot action recognition [C]// Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2018: 372-380. |
| 27 | BISHAY M, ZOUMPOURLIS G, PATRAS I. TARN: temporal attentive relation network for few-shot and zero-shot action recognition [C]// Proceedings of the 2019 British Machine Vision Conference. Durham: BMVA Press, 2019: 1-14. |
| 28 | TIAN Y, HUANG Y, XU W, et al. Coupling Adversarial Graph Embedding for transductive zero-shot action recognition [J]. Neurocomputing, 2021, 452: 239-252. |
| 29 | MISHRA A, PANDEY A, MURTHY H A. Zero-shot learning for action recognition using synthesized features [J]. Neurocomputing, 2020, 390: 117-130. |
| [1] | Jie XU, Yong ZHONG, Yang WANG, Changfu ZHANG, Guanci YANG. Facial attribute estimation and expression recognition based on contextual channel attention mechanism [J]. Journal of Computer Applications, 2025, 45(1): 253-260. |
| [2] | Junying CHEN, Shijie GUO, Lingling CHEN. Lightweight human pose estimation based on decoupled attention and ghost convolution [J]. Journal of Computer Applications, 2025, 45(1): 223-233. |
| [3] | Jialin ZHANG, Qinghua REN, Qirong MAO. Speaker verification system utilizing global-local feature dependency for anti-spoofing [J]. Journal of Computer Applications, 2025, 45(1): 308-317. |
| [4] | Ying HUANG, Changsheng LI, Hui PENG, Su LIU. Dual-branch network guided by local entropy for dynamic scene high dynamic range imaging [J]. Journal of Computer Applications, 2025, 45(1): 204-213. |
| [5] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [6] | Liting LI, Bei HUA, Ruozhou HE, Kuang XU. Multivariate time series prediction model based on decoupled attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2732-2738. |
| [7] | Zhiqiang ZHAO, Peihong MA, Xinhong HEI. Crowd counting method based on dual attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2886-2892. |
| [8] | Kaipeng XUE, Tao XU, Chunjie LIAO. Multimodal sentiment analysis network with self-supervision and multi-layer cross attention [J]. Journal of Computer Applications, 2024, 44(8): 2387-2392. |
| [9] | Pengqi GAO, Heming HUANG, Yonghong FAN. Fusion of coordinate and multi-head attention mechanisms for interactive speech emotion recognition [J]. Journal of Computer Applications, 2024, 44(8): 2400-2406. |
| [10] | Zhonghua LI, Yunqi BAI, Xuejin WANG, Leilei HUANG, Chujun LIN, Shiyu LIAO. Low illumination face detection based on image enhancement [J]. Journal of Computer Applications, 2024, 44(8): 2588-2594. |
| [11] | Shangbin MO, Wenjun WANG, Ling DONG, Shengxiang GAO, Zhengtao YU. Single-channel speech enhancement based on multi-channel information aggregation and collaborative decoding [J]. Journal of Computer Applications, 2024, 44(8): 2611-2617. |
| [12] | Li LIU, Haijin HOU, Anhong WANG, Tao ZHANG. Generative data hiding algorithm based on multi-scale attention [J]. Journal of Computer Applications, 2024, 44(7): 2102-2109. |
| [13] | Song XU, Wenbo ZHANG, Yifan WANG. Lightweight video salient object detection network based on spatiotemporal information [J]. Journal of Computer Applications, 2024, 44(7): 2192-2199. |
| [14] | Dahai LI, Zhonghua WANG, Zhendong WANG. Dual-branch low-light image enhancement network combining spatial and frequency domain information [J]. Journal of Computer Applications, 2024, 44(7): 2175-2182. |
| [15] | Wenliang WEI, Yangping WANG, Biao YUE, Anzheng WANG, Zhe ZHANG. Deep learning model for infrared and visible image fusion based on illumination weight allocation and attention [J]. Journal of Computer Applications, 2024, 44(7): 2183-2191. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||