


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (7): 2200-2208.DOI: 10.11772/j.issn.1001-9081.2022060907
所属专题: 数据科学与技术
蒋华, 李星( ), 王慧娇, 韦静海
), 王慧娇, 韦静海
收稿日期:2022-06-22
修回日期:2022-09-03
接受日期:2022-09-09
发布日期:2022-10-08
出版日期:2023-07-10
通讯作者:
李星
作者简介:蒋华(1963—),男,河南信阳人,教授,博士,主要研究方向:数据库系统、信息安全;基金资助:
Hua JIANG, Xing LI(), Huijiao WANG, Jinghai WEI
Received:2022-06-22
Revised:2022-09-03
Accepted:2022-09-09
Online:2022-10-08
Published:2023-07-10
Contact:
Xing LI
About author:JIANG Hua, born in 1963, Ph. D., professor. His research interests include database system, information security.Supported by:摘要:
针对现有的跨级高效用项集挖掘(HUIM)算法非常耗时且占用大量内存的问题,提出一种基于数据索引结构的跨级高效用项集挖掘算法(DISCH)。首先,为了高效存储和快速检索到搜索空间中的所有项集,拓展带有分类信息和索引信息的效用链表为数据索引结构(DIS);然后,为了提高内存利用率,对不满足条件的效用链表所占的内存进行回收再分配;最后,在构建效用链表时使用提前结束策略,以减少效用链表的产生。基于真实零售数据集和合成数据集进行的实验结果表明,与CLH-Miner (Cross-Level High utility itemsets Miner)算法相比,DISCH在运行时间上平均降低了77.6%,同时在内存消耗上平均降低了73.3%,可见该算法能高效完成跨级高效用项集的搜索,并且降低算法的内存消耗。
中图分类号:
蒋华, 李星, 王慧娇, 韦静海. 基于数据索引结构的跨级高效用项集挖掘算法[J]. 计算机应用, 2023, 43(7): 2200-2208.
Hua JIANG, Xing LI, Huijiao WANG, Jinghai WEI. Cross-level high utility itemsets mining algorithm based on data index structure[J]. Journal of Computer Applications, 2023, 43(7): 2200-2208.
| 事务编号 | 事务 | 事务编号 | 事务 |
|---|---|---|---|
| T0 | (1,1) (3,1) | T4 | (1,1) (3,1) (4,1) |
| T1 | (5,1) | T5 | (1,2) (3,6) (5,2) |
| T2 | (1,1) (2,5) (3,1) (4,3) (5,1) | T6 | (2,2) (3,2) (5,1) |
| T3 | (2,4) (3,3) (4,3) (5,1) |
表1 示例事务数据集
Tab. 1 Sample transaction dataset
| 事务编号 | 事务 | 事务编号 | 事务 |
|---|---|---|---|
| T0 | (1,1) (3,1) | T4 | (1,1) (3,1) (4,1) |
| T1 | (5,1) | T5 | (1,2) (3,6) (5,2) |
| T2 | (1,1) (2,5) (3,1) (4,3) (5,1) | T6 | (2,2) (3,2) (5,1) |
| T3 | (2,4) (3,3) (4,3) (5,1) |
| 项 | 外部效用 | 项 | 外部效用 |
|---|---|---|---|
| 1 | 5 | 4 | 2 |
| 2 | 2 | 5 | 3 |
| 3 | 1 |
表2 外部效用值
Tab. 2 External utility values
| 项 | 外部效用 | 项 | 外部效用 |
|---|---|---|---|
| 1 | 5 | 4 | 2 |
| 2 | 2 | 5 | 3 |
| 3 | 1 |
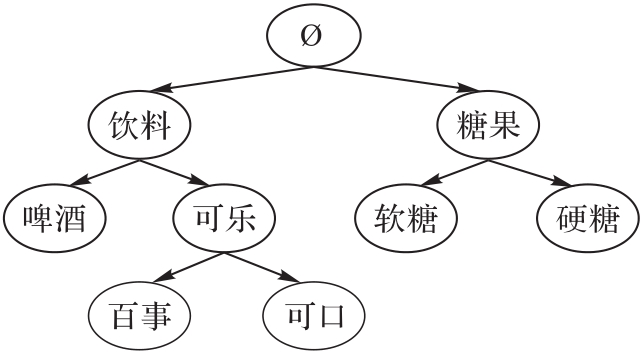
图1 现实生活中的分类关系示例
Fig. 1 Sample of taxonomy in real life
| 项 | 父项 | 项 | 父项 |
|---|---|---|---|
| 1 | 6 | 4 | 8 |
| 2 | 6 | 5 | 8 |
| 3 | 7 | 6 | 7 |
表3 示例事务数据集中项的分类关系
Tab. 3 Taxonomy of items in sample transaction dataset
| 项 | 父项 | 项 | 父项 |
|---|---|---|---|
| 1 | 6 | 4 | 8 |
| 2 | 6 | 5 | 8 |
| 3 | 7 | 6 | 7 |
| 项 | GWU | 项 | GWU |
|---|---|---|---|
| 1 | 61 | 5 | 79 |
| 2 | 54 | 6 | 90 |
| 3 | 90 | 7 | 90 |
| 4 | 53 | 8 | 87 |
表4 示例事务数据集中项的GWU值
Tab. 4 GWU values of items in sample transaction dataset
| 项 | GWU | 项 | GWU |
|---|---|---|---|
| 1 | 61 | 5 | 79 |
| 2 | 54 | 6 | 90 |
| 3 | 90 | 7 | 90 |
| 4 | 53 | 8 | 87 |
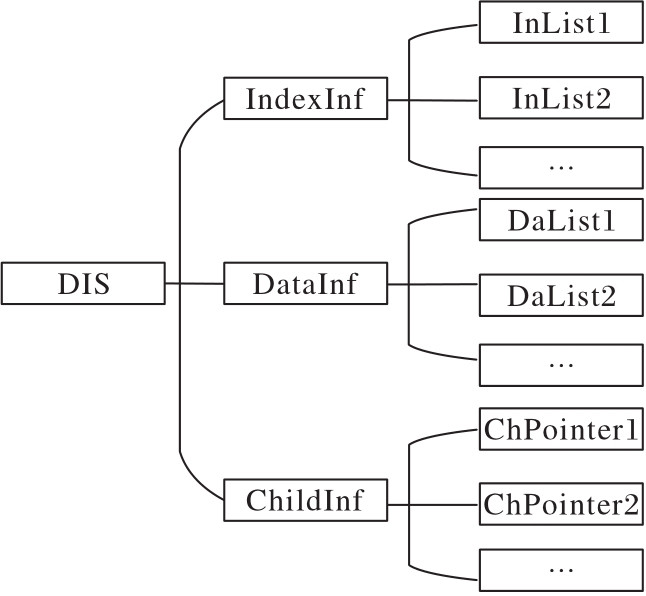
图2 DIS结构框架
Fig. 2 Framework of DIS structure
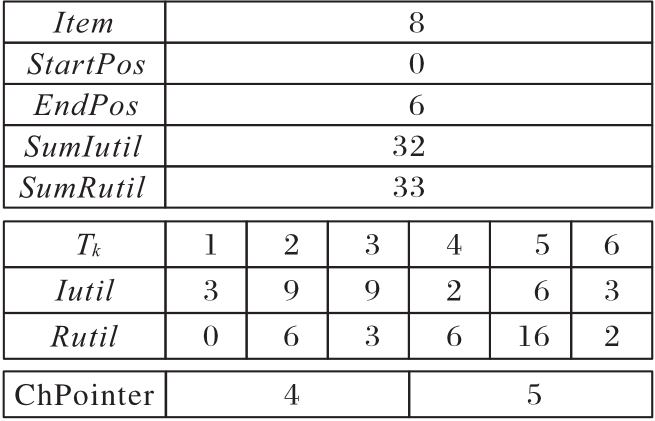
图3 插入广义项{8}后的DIS
Fig. 3 DIS after inserting generalized item {8}
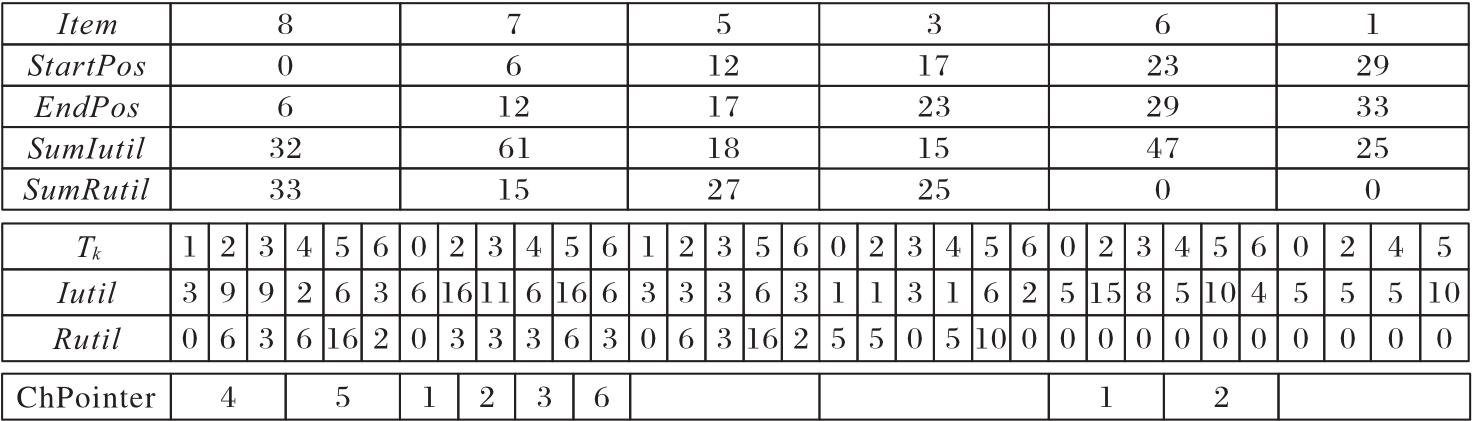
图4 插入所有单项后的DIS
Fig. 4 DIS after inserting all single items
| 数据集 | 事务数 | 一般项数 | 抽象项数 | 平均长度 | 最大长度 | 层数 |
|---|---|---|---|---|---|---|
| Fruithut | 181 970 | 1 265 | 43 | 3.58 | 36 | 4 |
| Liquor | 9 284 | 2 626 | 77 | 2.70 | 5 | 7 |
| Connect | 67 557 | 129 | 40 | 43.00 | 43 | 4 |
| Chainstore | 1 112 949 | 40 086 | 11 936 | 7.20 | 170 | 10 |
表5 数据集的基本特征
Tab. 5 Basic characteristics of datasets
| 数据集 | 事务数 | 一般项数 | 抽象项数 | 平均长度 | 最大长度 | 层数 |
|---|---|---|---|---|---|---|
| Fruithut | 181 970 | 1 265 | 43 | 3.58 | 36 | 4 |
| Liquor | 9 284 | 2 626 | 77 | 2.70 | 5 | 7 |
| Connect | 67 557 | 129 | 40 | 43.00 | 43 | 4 |
| Chainstore | 1 112 949 | 40 086 | 11 936 | 7.20 | 170 | 10 |
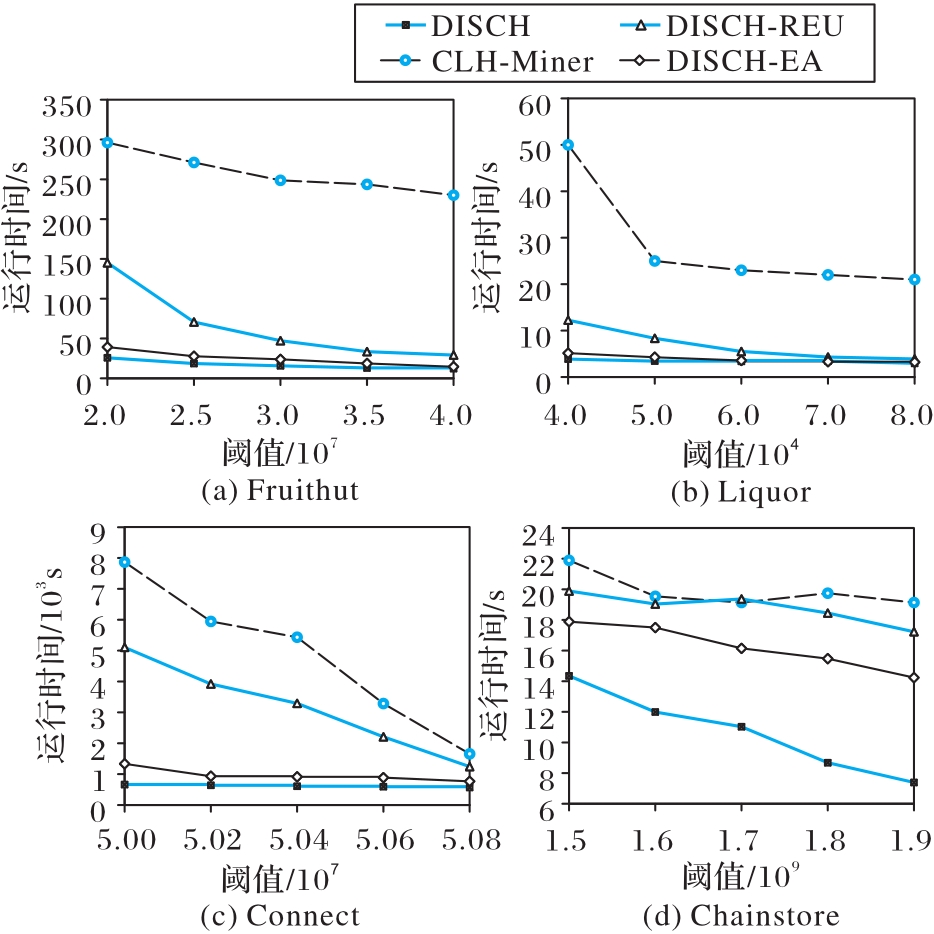
图5 DISCH算法和对比算法的运行时间
Fig. 5 Running time of DISCH algorithm and comparison algorithms
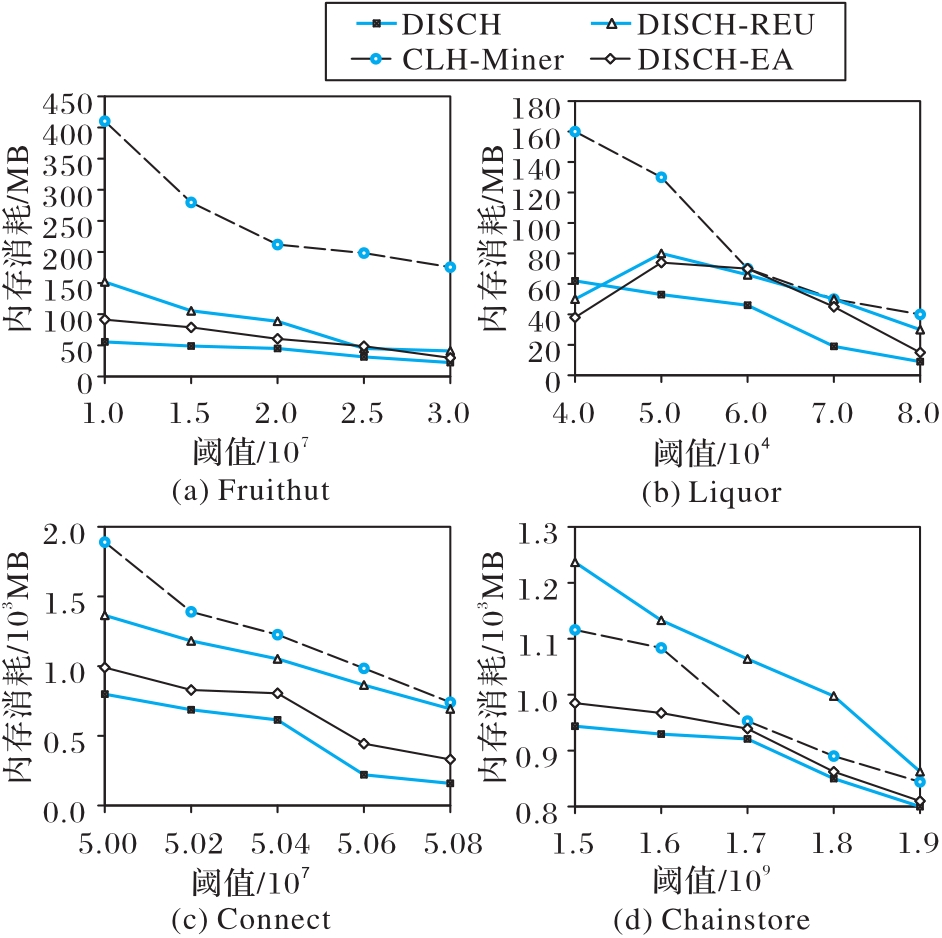
图6 DISCH算法和对比算法的内存消耗
Fig. 6 Memory consumption of DISCH algorithm and comparison algorithms
| minutil | 运行时间/s | 内存消耗/MB | ||||
|---|---|---|---|---|---|---|
| DISCH | ML-HUI Miner | HUI-Miner | DISCH | ML-HUI Miner | HUI-Miner | |
| 9 000 | 267.58 | 39.63 | 0.08 | 191.86 | 129.92 | 59.15 |
| 10 000 | 221.65 | 40.34 | 0.07 | 146.43 | 68.22 | 102.86 |
| 11 000 | 110.69 | 38.17 | 0.06 | 138.24 | 108.13 | 28.41 |
| 12 000 | 97.71 | 39.76 | 0.05 | 226.25 | 183.20 | 74.19 |
| 13 000 | 86.93 | 40.59 | 0.05 | 150.76 | 315.74 | 117.65 |
表6 DISCH、ML-HUI Miner和HUI-Miner算法在Liquor数据集上的性能对比
Tab. 6 Performance comparison of DISCH, ML-HUI Miner and HUI-Miner algorithms on Liquor dataset
| minutil | 运行时间/s | 内存消耗/MB | ||||
|---|---|---|---|---|---|---|
| DISCH | ML-HUI Miner | HUI-Miner | DISCH | ML-HUI Miner | HUI-Miner | |
| 9 000 | 267.58 | 39.63 | 0.08 | 191.86 | 129.92 | 59.15 |
| 10 000 | 221.65 | 40.34 | 0.07 | 146.43 | 68.22 | 102.86 |
| 11 000 | 110.69 | 38.17 | 0.06 | 138.24 | 108.13 | 28.41 |
| 12 000 | 97.71 | 39.76 | 0.05 | 226.25 | 183.20 | 74.19 |
| 13 000 | 86.93 | 40.59 | 0.05 | 150.76 | 315.74 | 117.65 |

图7 在Liquor数据集上的项集数量对比
Fig. 7 Comparison of number of itemsets on Liquor dataset
| 数据集大小占比/% | 运行时间/s | 项集数 |
|---|---|---|
| 20 | 54.9 | 24 |
| 40 | 77.3 | 53 |
| 60 | 116.5 | 95 |
| 80 | 178.7 | 150 |
| 100 | 258.2 | 224 |
表7 改变数据集大小时DISCH算法的可伸缩性
Tab. 7 Scalability of DISCH algorithm when changing dataset size
| 数据集大小占比/% | 运行时间/s | 项集数 |
|---|---|---|
| 20 | 54.9 | 24 |
| 40 | 77.3 | 53 |
| 60 | 116.5 | 95 |
| 80 | 178.7 | 150 |
| 100 | 258.2 | 224 |
| 1 | HAJIHOSEINI M, SOHRABI M K. Mining fuzzy high average-utility itemsets using fuzzy utility lists and efficient pruning approach[J]. Soft Computing, 2022, 26(13): 6063-6086. 10.1007/s00500-022-07123-7 |
| 2 | ASHRAF M, ABDELKADER T, RADY S, et al. TKN: an efficient approach for discovering top-k high utility itemsets with positive or negative profits[J]. Information Sciences, 2022, 587: 654-678. 10.1016/j.ins.2021.12.024 |
| 3 | 蒋华,路昕宇,王慧娇,等.基于DBP的Top-k高效用项集挖掘算法[J].计算机工程与设计, 2021, 42(6): 1631-1637. |
| JIANG H, LU X Y, WANG H J, et al. Top-k high utility itemsets mining based on DBP[J]. Computer Engineering and Design, 2021, 42(6): 1631-1637. | |
| 4 | 程浩东,韩萌,张妮,等.基于滑动窗口模型的数据流闭合高效用项集挖掘[J].计算机研究与发展, 2021, 58(11): 2500-2514. 10.7544/issn1000-1239.2021.20200554 |
| CHENG H D, HAN M, ZHANG N, et al. Closed high utility itemsets mining over data stream based on sliding window model[J]. Journal of Computer Research and Development, 2021, 58(11): 2500-2514. 10.7544/issn1000-1239.2021.20200554 | |
| 5 | TUNG N T, NGUYEN L T T, NGUYEN T D D, et al. An efficient method for mining multi-level high utility itemsets[J]. Applied Intelligence, 2022, 52(5): 5475-5496. 10.1007/s10489-021-02681-z |
| 6 | CAGLIERO L, CHIUSANO S, GARZA P, et al. Discovering high-utility itemsets at multiple abstraction levels [C]// Proceedings of the 2017 European Conference on Advances in Databases and Information Systems, CCIS 767. Cham: Springer, 2017: 224-234. 10.1007/978-3-319-67162-8_22 |
| 7 | FOURNIER-VIGER P, WANG Y, LIN J C W, et al. Mining cross-level high utility itemsets [C]// Proceedings of the 2020 International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, LNCS 12144. Cham: Springer, 2020: 858-871. |
| 8 | RAHMATI B, SOHRABI M K. A systematic survey on high utility itemset mining[J]. International Journal of Information Technology and Decision Making, 2019, 18(4): 1113-1185. 10.1142/s0219622019300027 |
| 9 | LIU M C, QU J F. Mining high utility itemsets without candidate generation [C]// Proceedings of the Proceedings of the 21st ACM International Conference on Information and Knowledge Management. New York: ACM, 2012: 55-64. 10.1145/2396761.2396773 |
| 10 | FOURNIER-VIGER P, WU C W, ZIDA S, et al. FHM: faster high-utility itemset mining using estimated utility co-occurrence pruning [C]// Proceedings of the 2014 International Symposium on Methodologies for Intelligent Systems, LNCS 8502. Cham: Springer, 2014: 83-92. |
| 11 | KRISHNAMOORTHY S. Pruning strategies for mining high utility itemsets[J]. Expert Systems with Applications, 2015, 42(5): 2371-2381. 10.1016/j.eswa.2014.11.001 |
| 12 | ZIDA S, FOURNIER-VIGER P, LIN J C W, et al. EFIM: a fast and memory efficient algorithm for high-utility itemset mining[J]. Knowledge and Information Systems, 2017, 51(2): 595-625. 10.1007/s10115-016-0986-0 |
| 13 | PENG A Y, KOH Y S, RIDDLE P. mHUIMiner: a fast high utility itemset mining algorithm for sparse datasets [C]// Proceedings of the 2017 Pacific-Asia Conference on Knowledge Discovery and Data Mining, LNCS 10235. Cham: Springer, 2017: 196-207. |
| 14 | DUONG Q H, FOURNIER-VIGER P, RAMAMPIARO H, et al. Efficient high utility itemset mining using buffered utility-lists[J]. Applied Intelligence, 2018, 48(7): 1859-1877. 10.1007/s10489-017-1057-2 |
| 15 | QU J F, FOURNIER-VIGER P, LIU M C, et al. Mining high utility itemsets using extended chain structure and utility machine[J]. Knowledge-Based Systems, 2020, 208: No.106457. 10.1016/j.knosys.2020.106457 |
| 16 | WU P, NIU X Z, FOURNIER-VIGER P, et al. UBP-Miner: an efficient bit based high utility itemset mining algorithm[J]. Knowledge-Based Systems, 2022, 248: No.108865. 10.1016/j.knosys.2022.108865 |
| 17 | 何登平,何宗浩.基于R-list的Top-K高效用项集挖掘算法[J].计算机工程与科学, 2019, 41(7): 1318-1324. 10.3969/j.issn.1007-130X.2019.07.025 |
| HE D P, HE Z H. A top-k high utility itemset mining algorithm based on R-list[J]. Computer Engineering and Science, 2019, 41(7): 1318-1324. 10.3969/j.issn.1007-130X.2019.07.025 | |
| 18 | 张妮,韩萌,王乐,等.基于索引列表的增量高效用模式挖掘算法[J].山东大学学报(工学版), 2022, 52(2): 107-117. |
| ZHANG N, HAN M, WANG L, et al. Incremental high utility pattern mining algorithm based on index list[J]. Journal of Shandong University (Engineering Science), 2022, 52(2): 107-117. | |
| 19 | 孙蕊,韩萌,张春砚,等.含负项top-k高效用项集挖掘算法[J].计算机应用, 2021, 41(8): 2386-2395. |
| SUN R, HAN M, ZHANG C Y, et al. Algorithm for mining top-k high utility itemsets with negative items[J]. Journal of Computer Applications, 2021, 41(8): 2386-2395. | |
| 20 | NOUIOUA M, WANG Y, FOURNIER-VIGER P, et al. TKC: mining top-k cross-level high utility itemsets [C]// Proceedings of the 2020 International Conference on Data Mining Workshops. Piscataway: IEEE, 2020: 673-682. 10.1109/icdmw51313.2020.00095 |
| 21 | TUNG N T, NGUYEN L T T, NGUYEN T D D, et al. Efficient mining of cross-level high-utility itemsets in taxonomy quantitative databases[J]. Information Sciences, 2022, 587: 41-62. 10.1016/j.ins.2021.12.017 |
| 22 | FOURNIER-VIGER P, GOMARIZ A, GUENICHE T, et al. SPMF: a Java open-source pattern mining library[J]. Journal of Machine Learning Research, 2014, 15: 3569-3573. |
| [1] | 李欢欢, 黄添强, 丁雪梅, 罗海峰, 黄丽清. 基于多尺度时空图卷积网络的交通出行需求预测[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2065-2072. |
| [2] | 董瑶, 付怡雪, 董永峰, 史进, 陈晨. 不完整多视图聚类综述[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1673-1682. |
| [3] | 杨克帅, 武优西, 耿萌, 刘靖宇, 李艳. 一次性条件下top-k高平均效用序列模式挖掘算法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 477-484. |
| [4] | 郑浩东, 马华, 谢颖超, 唐文胜. 融合遗忘因素与记忆门的图神经网络知识追踪模型[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2747-2752. |
| [5] | 黄硕, 李艳辉, 曹建秋. 本地化差分隐私下的频繁序列模式挖掘算法PrivSPM[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2057-2064. |
| [6] | 高智慧, 韩萌, 刘淑娟, 李昂, 穆栋梁. 基于智能优化算法的高效用项集挖掘方法综述[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1676-1686. |
| [7] | 祁超帅, 何文思, 焦毅, 马英红, 蔡伟, 任素萍. 无人机飞行数据异常检测算法综述[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1833-1841. |
| [8] | 袁泉, 唐成亮, 徐雲鹏. 基于长度约束的蝙蝠高效用项集挖掘算法[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1473-1480. |
| [9] | 李元江, 权金升, 谭阳奕, 杨田. 基于相似和差异双视角的高维数据属性约简[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1467-1472. |
| [10] | 邵小萌, 张猛. 融合注意力机制的时间卷积知识追踪模型[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 343-348. |
| [11] | 钟新成, 刘昶, 赵秀梅. 基于马尔可夫优化的高效用项集挖掘算法[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3764-3771. |
| [12] | 李文全, 毛伊敏, 彭新东. 基于犹豫模糊集的凝聚式层次聚类算法[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3755-3763. |
| [13] | 吴军, 欧阳艾嘉, 张琳. 基于影响度的统计显著序列模式挖掘算法[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2713-2721. |
| [14] | 余顺坤, 闫泓序. 基于确定性因子的启发式属性值约简模型[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 469-474. |
| [15] | 刘世泽, 秦艳君, 王晨星, 苏琳, 柯其学, 罗海勇, 孙艺, 王宝会. 基于深度残差长短记忆网络交通流量预测算法[J]. 计算机应用, 2021, 41(6): 1566-1572. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||