


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (3): 715-724.DOI: 10.11772/j.issn.1001-9081.2024030322
曾辉1,2, 熊诗雨1,2, 狄永正1,2, 史红周1( )
)
收稿日期:2024-03-13
修回日期:2024-05-26
接受日期:2024-05-29
发布日期:2024-07-24
出版日期:2025-03-10
通讯作者:
史红周
作者简介:曾辉(1998—),男,江西于都人,硕士研究生,主要研究方向:联邦学习、大模型微调基金资助:
Hui ZENG1,2, Shiyu XIONG1,2, Yongzheng DI1,2, Hongzhou SHI1()
Received:2024-03-13
Revised:2024-05-26
Accepted:2024-05-29
Online:2024-07-24
Published:2025-03-10
Contact:
Hongzhou SHI
About author:ZENG Hui, born in 1998, M. S. candidate. His research interests include federated learning, foundation model fine-tuning.Supported by:摘要:
随着数据隐私重要性的不断提升,用于下游任务的预训练基础模型(PFM)的微调变得愈发困难,这推动了基于PFM的联邦学习研究。然而,PFM给联邦学习系统带来了显著的挑战,特别是在本地计算和通信方面。因此,针对联邦学习的本地计算和聚合通信这两个主要阶段,分别提出对应的解决方案,即本地高效微调模式和环形本地聚合模式。本地高效微调模式采用基于参数高效微调(PEFT)的模型剪枝算法以减轻本地计算和通信开销;环形本地聚合模式采用分布式的本地聚合方法取代中心化的聚合方法以提升聚合阶段的通信效率。实验结果表明,所提大模型联邦参数高效微调框架在最终性能和效率方面均表现良好。
中图分类号:
曾辉, 熊诗雨, 狄永正, 史红周. 基于剪枝的大模型联邦参数高效微调技术[J]. 计算机应用, 2025, 45(3): 715-724.
Hui ZENG, Shiyu XIONG, Yongzheng DI, Hongzhou SHI. Federated parameter-efficient fine-tuning technology for large model based on pruning[J]. Journal of Computer Applications, 2025, 45(3): 715-724.
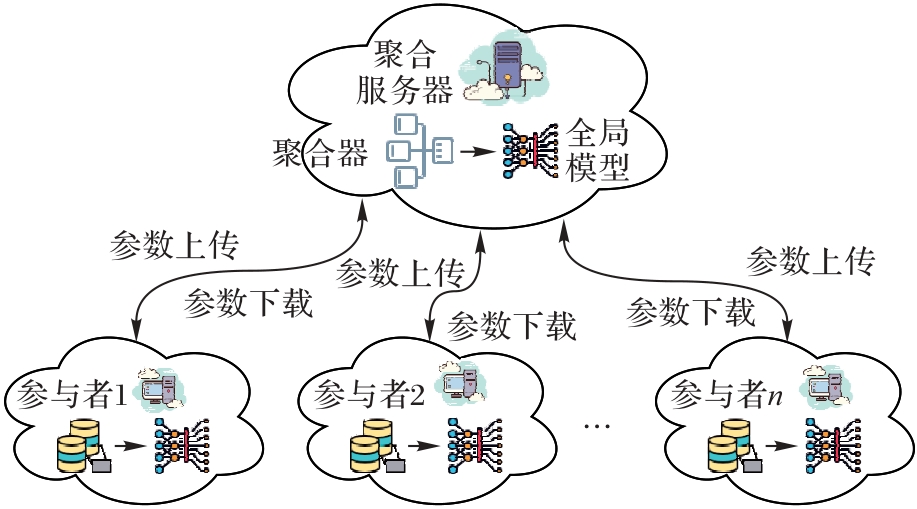
图1 联邦学习框架
Fig. 1 Framework of federated learning
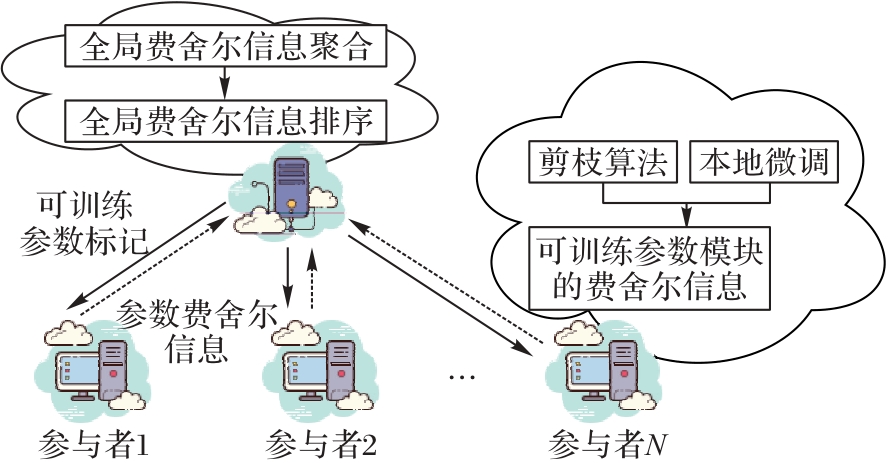
图2 本地高效微调模式
Fig. 2 Local efficient fine-tuning mode
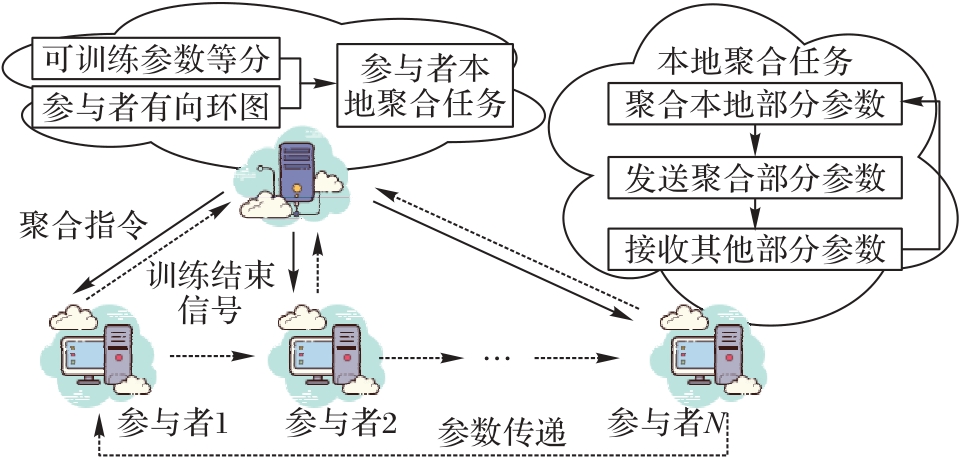
图3 环形本地聚合模式
Fig. 3 Ring-shaped local aggregation mode
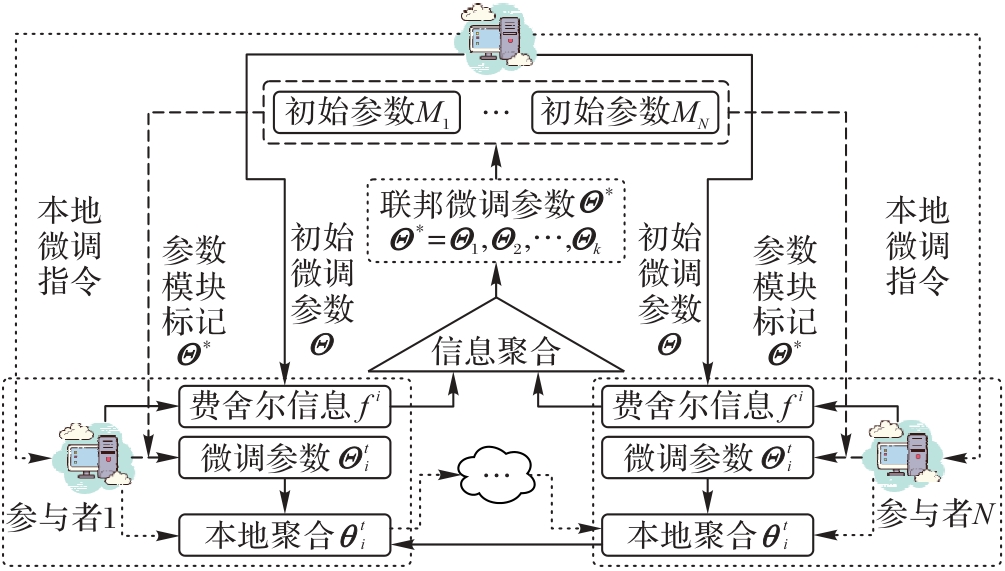
图4 联邦微调框架的总体架构
Fig. 4 Overall architecture of federal fine-tuning framework
| 算法 | BLEU/% | NIST | MET/% | R-L/% | CIDEr |
|---|---|---|---|---|---|
| LoRA | 72.71 | 8.914 | 47.12 | 72.84 | 2.434 |
| LLaMA-1.3B | 53.32 | 2.336 | 33.20 | 64.27 | 1.233 |
| LLaMA-2.7B | 56.87 | 2.752 | 34.28 | 65.51 | 1.342 |
| AdaLoRA | 68.43 | 8.340 | 46.00 | 71.59 | 2.166 |
| ChildTuning | 68.73 | 8.535 | 42.83 | 69.45 | 1.963 |
| LLMPruner | 73.87 | 8.953 | 47.46 | 74.75 | 2.456 |
| 本文算法 | 74.49 | 9.107 | 47.82 | 74.86 | 2.563 |
表1 不同剪枝算法的性能对比实验结果
Tab.1 Experimental results of performance comparison of different pruning algorithms
| 算法 | BLEU/% | NIST | MET/% | R-L/% | CIDEr |
|---|---|---|---|---|---|
| LoRA | 72.71 | 8.914 | 47.12 | 72.84 | 2.434 |
| LLaMA-1.3B | 53.32 | 2.336 | 33.20 | 64.27 | 1.233 |
| LLaMA-2.7B | 56.87 | 2.752 | 34.28 | 65.51 | 1.342 |
| AdaLoRA | 68.43 | 8.340 | 46.00 | 71.59 | 2.166 |
| ChildTuning | 68.73 | 8.535 | 42.83 | 69.45 | 1.963 |
| LLMPruner | 73.87 | 8.953 | 47.46 | 74.75 | 2.456 |
| 本文算法 | 74.49 | 9.107 | 47.82 | 74.86 | 2.563 |
| 微调方法 | 选择率 | CoLA | MRPC | RTE | SST-2 | STS-B |
|---|---|---|---|---|---|---|
| MCC/% | ACC/% | ACC/% | ACC/% | PS/% | ||
BERT (LoRA) | 1.0 | 57.26 | 83.82 | 59.57 | 92.20 | 86.78 |
| 0.6 | 57.67 | 85.05 | 62.09 | 92.43 | 86.42 | |
RoBERTa (LoRA) | 1.0 | 59.31 | 87.99 | 72.92 | 93.92 | 90.64 |
| 0.6 | 61.36 | 88.24 | 75.81 | 94.72 | 90.40 | |
BERT (Adapter) | 1.0 | 61.35 | 87.50 | 70.76 | 92.89 | 89.23 |
| 0.6 | 60.66 | 86.03 | 73.64 | 91.51 | 89.25 | |
RoBERTa (Adapter) | 1.0 | 59.36 | 89.46 | 77.98 | 94.15 | 90.99 |
| 0.6 | 61.84 | 89.22 | 76.90 | 94.50 | 91.01 | |
BERT (IA3) | 0.0 | 43.89 | 70.83 | 58.84 | 91.63 | 78.34 |
| 0.6 | 43.09 | 71.32 | 61.37 | 91.43 | 76.76 | |
RoBERTa (IA3) | 1.0 | 51.00 | 77.94 | 66.06 | 93.81 | 86.24 |
| 0.6 | 48.57 | 80.15 | 66.06 | 94.15 | 86.21 |
表2 基于不同PEFT技术的剪枝算法在NLU任务上的微调性能比较
Tab. 2 Comparison of fine-tuning performance of pruning algorithms based on different PEFT technologies in NLU tasks
| 微调方法 | 选择率 | CoLA | MRPC | RTE | SST-2 | STS-B |
|---|---|---|---|---|---|---|
| MCC/% | ACC/% | ACC/% | ACC/% | PS/% | ||
BERT (LoRA) | 1.0 | 57.26 | 83.82 | 59.57 | 92.20 | 86.78 |
| 0.6 | 57.67 | 85.05 | 62.09 | 92.43 | 86.42 | |
RoBERTa (LoRA) | 1.0 | 59.31 | 87.99 | 72.92 | 93.92 | 90.64 |
| 0.6 | 61.36 | 88.24 | 75.81 | 94.72 | 90.40 | |
BERT (Adapter) | 1.0 | 61.35 | 87.50 | 70.76 | 92.89 | 89.23 |
| 0.6 | 60.66 | 86.03 | 73.64 | 91.51 | 89.25 | |
RoBERTa (Adapter) | 1.0 | 59.36 | 89.46 | 77.98 | 94.15 | 90.99 |
| 0.6 | 61.84 | 89.22 | 76.90 | 94.50 | 91.01 | |
BERT (IA3) | 0.0 | 43.89 | 70.83 | 58.84 | 91.63 | 78.34 |
| 0.6 | 43.09 | 71.32 | 61.37 | 91.43 | 76.76 | |
RoBERTa (IA3) | 1.0 | 51.00 | 77.94 | 66.06 | 93.81 | 86.24 |
| 0.6 | 48.57 | 80.15 | 66.06 | 94.15 | 86.21 |
| 微调方法 | 选择率 | BLEU/% | NIST | MET/% | R-L/% | CIDEr |
|---|---|---|---|---|---|---|
GPT2-M (LoRA) | 1.0 | 68.84 | 7.189 | 39.71 | 70.51 | 2.039 |
| 0.7 | 71.28 | 7.836 | 40.10 | 70.43 | 2.143 | |
GPT2-L (LoRA) | 1.0 | 71.51 | 8.624 | 46.00 | 73.22 | 2.470 |
| 0.7 | 72.52 | 8.719 | 45.67 | 73.67 | 2.513 | |
GPT2-M (Adapter) | 1.0 | 65.22 | 6.289 | 36.75 | 67.64 | 1.816 |
| 0.7 | 64.88 | 6.498 | 36.31 | 66.87 | 1.752 | |
GPT2-L (Adapter) | 1.0 | 67.69 | 7.127 | 39.65 | 69.72 | 1.996 |
| 0.7 | 68.29 | 6.978 | 39.29 | 69.94 | 1.976 | |
GPT2-M (IA3) | 1.0 | 72.64 | 8.792 | 43.90 | 73.11 | 2.432 |
| 0.7 | 72.35 | 8.786 | 43.71 | 72.52 | 2.415 | |
GPT2-L (IA3) | 1.0 | 71.18 | 8.794 | 45.00 | 72.75 | 2.391 |
| 0.7 | 72.57 | 8.757 | 46.28 | 74.42 | 2.497 |
表3 基于不同PEFT技术的剪枝算法在E2E NLG任务上的微调性能比较
Tab. 3 Comparison of fine-tuning performance of pruning algorithms based on different PEFT technologies in E2E NLG tasks
| 微调方法 | 选择率 | BLEU/% | NIST | MET/% | R-L/% | CIDEr |
|---|---|---|---|---|---|---|
GPT2-M (LoRA) | 1.0 | 68.84 | 7.189 | 39.71 | 70.51 | 2.039 |
| 0.7 | 71.28 | 7.836 | 40.10 | 70.43 | 2.143 | |
GPT2-L (LoRA) | 1.0 | 71.51 | 8.624 | 46.00 | 73.22 | 2.470 |
| 0.7 | 72.52 | 8.719 | 45.67 | 73.67 | 2.513 | |
GPT2-M (Adapter) | 1.0 | 65.22 | 6.289 | 36.75 | 67.64 | 1.816 |
| 0.7 | 64.88 | 6.498 | 36.31 | 66.87 | 1.752 | |
GPT2-L (Adapter) | 1.0 | 67.69 | 7.127 | 39.65 | 69.72 | 1.996 |
| 0.7 | 68.29 | 6.978 | 39.29 | 69.94 | 1.976 | |
GPT2-M (IA3) | 1.0 | 72.64 | 8.792 | 43.90 | 73.11 | 2.432 |
| 0.7 | 72.35 | 8.786 | 43.71 | 72.52 | 2.415 | |
GPT2-L (IA3) | 1.0 | 71.18 | 8.794 | 45.00 | 72.75 | 2.391 |
| 0.7 | 72.57 | 8.757 | 46.28 | 74.42 | 2.497 |
| 微调方法 | 选择率 | CoLA | MRPC | RTE | SST-2 | STS-B | 通信时间/s |
|---|---|---|---|---|---|---|---|
| MCC/% | ACC/% | ACC/% | ACC/% | PS/% | |||
| BERT(Cen) | — | 57.27 | 83.82 | 59.57 | 92.20 | 86.61 | — |
| BERT(Fed) | — | 44.69 | 70.83 | 55.23 | 91.28 | 82.69 | 6.88 |
| 0.6 | 48.49 | 71.32 | 60.29 | 91.97 | 82.87 | 2.02 | |
| RoBERTa(Cen) | — | 59.31 | 87.99 | 72.92 | 93.92 | 90.64 | — |
| RoBERTa(Fed) | — | 48.58 | 81.13 | 53.79 | 93.12 | 86.78 | 20.50 |
| 0.6 | 47.80 | 78.92 | 59.21 | 93.69 | 87.19 | 8.84 |
表4 联邦微调框架在NLU任务上的性能比较
Tab. 4 Performance comparison of federated fine-tuning frameworks in NLU tasks
| 微调方法 | 选择率 | CoLA | MRPC | RTE | SST-2 | STS-B | 通信时间/s |
|---|---|---|---|---|---|---|---|
| MCC/% | ACC/% | ACC/% | ACC/% | PS/% | |||
| BERT(Cen) | — | 57.27 | 83.82 | 59.57 | 92.20 | 86.61 | — |
| BERT(Fed) | — | 44.69 | 70.83 | 55.23 | 91.28 | 82.69 | 6.88 |
| 0.6 | 48.49 | 71.32 | 60.29 | 91.97 | 82.87 | 2.02 | |
| RoBERTa(Cen) | — | 59.31 | 87.99 | 72.92 | 93.92 | 90.64 | — |
| RoBERTa(Fed) | — | 48.58 | 81.13 | 53.79 | 93.12 | 86.78 | 20.50 |
| 0.6 | 47.80 | 78.92 | 59.21 | 93.69 | 87.19 | 8.84 |
| 微调方法 | 选择率 | BLEU/% | NIST | MET/% | R-L/% | CIDEr | 通信时间/s |
|---|---|---|---|---|---|---|---|
| GPT2-M(Cen) | — | 68.84 | 7.189 | 39.71 | 70.51 | 2.039 | — |
| GPT2-M(Fed) | — | 63.07 | 5.400 | 36.61 | 67.91 | 1.718 | 9.14 |
| 0.7 | 65.84 | 6.853 | 37.66 | 68.19 | 1.913 | 3.03 | |
| GPT2-L(Cen) | — | 71.51 | 8.624 | 46.00 | 73.22 | 2.470 | — |
| GPT2-L(Fed) | — | 69.82 | 7.928 | 41.58 | 71.73 | 2.197 | 17.14 |
| 0.7 | 72.34 | 8.601 | 42.98 | 72.61 | 2.380 | 5.88 | |
| LLaMA2-7B(Cen) | — | 74.23 | 76.770 | 48.31 | 2.57 | 8.972 | — |
| LLaMA2-7B(Fed) | — | 72.00 | 8.881 | 45.76 | 73.51 | 2.438 | 193.08 |
| 0.7 | 73.50 | 8.289 | 46.57 | 80.32 | 2.594 | 65.76 |
表5 联邦微调框架在NLG任务上的性能比较
Tab. 5 Performance comparison of federated fine-tuning frameworks in NLG tasks
| 微调方法 | 选择率 | BLEU/% | NIST | MET/% | R-L/% | CIDEr | 通信时间/s |
|---|---|---|---|---|---|---|---|
| GPT2-M(Cen) | — | 68.84 | 7.189 | 39.71 | 70.51 | 2.039 | — |
| GPT2-M(Fed) | — | 63.07 | 5.400 | 36.61 | 67.91 | 1.718 | 9.14 |
| 0.7 | 65.84 | 6.853 | 37.66 | 68.19 | 1.913 | 3.03 | |
| GPT2-L(Cen) | — | 71.51 | 8.624 | 46.00 | 73.22 | 2.470 | — |
| GPT2-L(Fed) | — | 69.82 | 7.928 | 41.58 | 71.73 | 2.197 | 17.14 |
| 0.7 | 72.34 | 8.601 | 42.98 | 72.61 | 2.380 | 5.88 | |
| LLaMA2-7B(Cen) | — | 74.23 | 76.770 | 48.31 | 2.57 | 8.972 | — |
| LLaMA2-7B(Fed) | — | 72.00 | 8.881 | 45.76 | 73.51 | 2.438 | 193.08 |
| 0.7 | 73.50 | 8.289 | 46.57 | 80.32 | 2.594 | 65.76 |
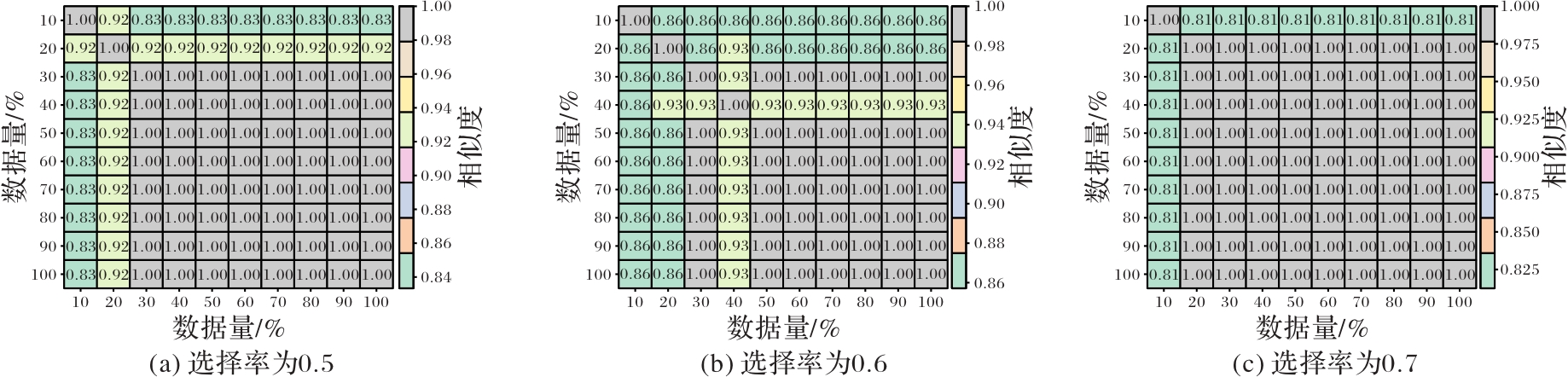
图5 不同数据量对参数模块选择的影响
Fig. 5 Influence of different data sizes on parameter module selection

图6 不同选择率下的推理时间对比
Fig. 6 Comparison of inference time under different selection rates
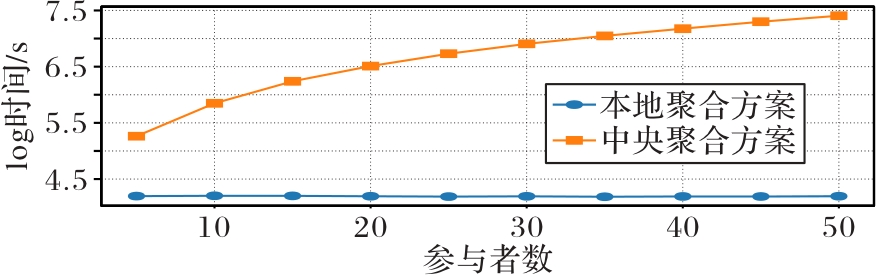
图7 不同聚合方案的平均通信时间对比
Fig. 7 Comparison of average communication time of different aggregation schemes
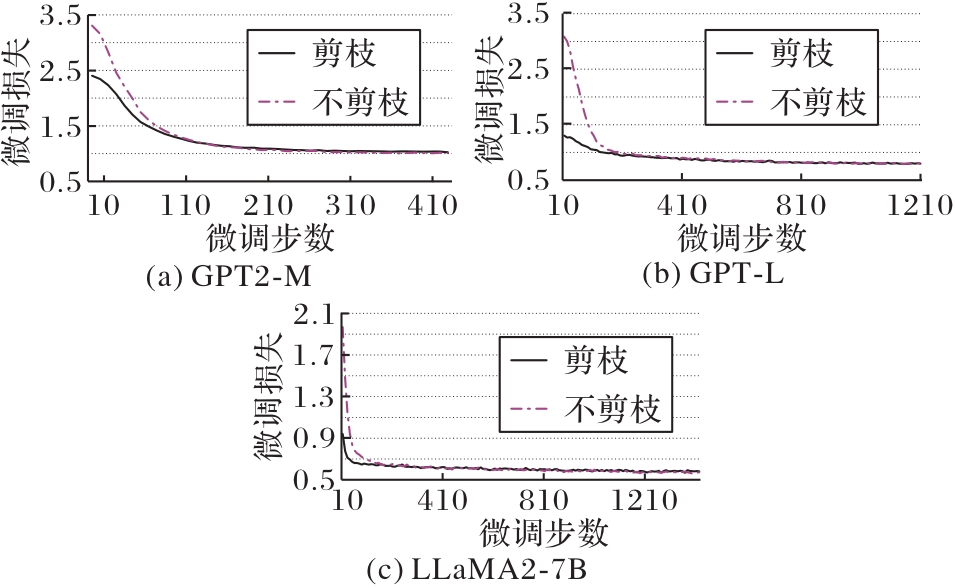
图8 剪枝算法在参数高效微调中的损失变化趋势
Fig. 8 Loss variation trend of pruning algorithms in parameter efficient fine-tuning
| 1 | BOMMASANI R, HUDSON D A, ADELI E, et al. On the opportunities and risks of foundation models [EB/OL]. [2024-07-12]. . |
| 2 | RADFORD A. Improving language understanding by generative pre-training [EB/OL]. [2023-06-11]. . |
| 3 | RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL]. [2023-10-11]. . |
| 4 | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1877-1901. |
| 5 | OpenAI. GPT-4 technical report[R/OL]. [2023-03-27]. . |
| 6 | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| 7 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| 8 | CHOWDHERY A, NARANG S, DEVLIN J, et al. PaLM: scaling language modeling with pathways [J]. Journal of Machine Learning Research, 2023, 24: 1-113. |
| 9 | Google. PaLM 2 technical report [R/OL]. [2024-03-13]. . |
| 10 | TOUVRON H, LAVRIL T, IZACARD G, et al. LLaMA: open and efficient foundation language models [EB/OL]. [2024-02-27]. . |
| 11 | TOUVRON H, MARTIN L, STONE K, et al. LLaMA 2: open foundation and fine-tuned chat models [EB/OL]. [2023-07-19].. |
| 12 | ZHOU C, LI Q, LI C, et al. A comprehensive survey on pretrained foundation models: a history from BERT to ChatGPT[EB/OL]. [2024-05-01]. . |
| 13 | ZHUANG W, CHEN C, LYU L. When foundation model meets federated learning: motivations, challenges, and future directions[EB/OL]. [2024-01-27]. . |
| 14 | DU Z, QIAN Y, LIU X, et al. GLM: general language model pretraining with autoregressive blank infilling [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 320-335. |
| 15 | ZENG A, LIU X, DU Z, et al. GLM-130B: an open bilingual pre-trained model [EB/OL]. [2023-12-10]. . |
| 16 | TAORI R, GULRAJANI I, ZHANG T, et al. Stanford Alpaca: an instruction-following LLaMA model [EB/OL]. [2023-12-14].. |
| 17 | COLINS E, GHAHRAMANI Z. LaMDA: our breakthrough conversation technology [EB/OL]. [2024-01-18]. . |
| 18 | VILLALOBOS P, SEVILLA J, HEIM L, et al. Will we run out of data? Limits of LLM scaling based on human-generated data [EB/OL]. [2024-10-25]. . |
| 19 | 王利明. 敏感个人信息保护的基本问题——以《民法典》和《个人信息保护法》的解释为背景[J]. 当代法学, 2022, 36(1): 3-14. |
| WANG L M. Basic issues in the protection of sensitive personal information — based on the interpretation of the “Civil Code” and the “Personal Information Protection Law” [J]. Contemporary Law Review, 2022, 36(1): 3-14. | |
| 20 | 张利娟. “数据二十条”出炉,如何挖掘数据“石油”?[J]. 中国报道, 2023(1): 66-68. |
| ZHANG L J. “Data Twenty” released, how to mine data “oil”? [J]. China Report, 2023(1): 66-68. | |
| 21 | McMAHAN H B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data [C]// Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2017: 1273-1282. |
| 22 | AGHAJANYAN A, GUPTA S, ZETTLEMOYER L. Intrinsic dimensionality explains the effectiveness of language model fine-tuning [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 7319-7328. |
| 23 | HOULSBY N, GIURGIU A, JASTRZEBSKI S, et al. Parameter-efficient transfer learning for NLP [C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 2790-2799. |
| 24 | PFEIFFER J, KAMATH A, RÜCKLÉ A, et al. AdapterFusion: non-destructive task composition for transfer learning [C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Stroudsburg: ACL, 2021: 487-503. |
| 25 | HU E J, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models [EB/OL]. [2024-01-29]. . |
| 26 | LIU H, TAM D, MUQEETH M, et al. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 1950-1965. |
| 27 | XU R, LUO F, ZHANG Z, et al. Raise a child in large language model: towards effective and generalizable fine-tuning [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 9514-9528. |
| 28 | WANG W, CHEN W, LUO Y, et al. Model compression and efficient inference for large language models: a survey [EB/OL]. [2024-04-15]. . |
| 29 | MA X, FANG G, WANG X. LLM-pruner: on the structural pruning of large language models [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 21702-21720. |
| 30 | ZHANG Q, CHEN M, BUKHARIN A, et al. Adaptive budget allocation for parameter-efficient fine-tuning [EB/OL]. [2024-01-24]. . |
| 31 | TU M, BERISHA V, WOOLF M, et al. Ranking the parameters of deep neural networks using the fisher information [C]// Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2016: 2647-2651. |
| 32 | ZHANG H, LI G, LI J, et al. Fine-tuning pre-trained language models effectively by optimizing subnetworks adaptively [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 21442-21454. |
| 33 | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. [2023-07-26].. |
| 34 | WANG A, SINGH A, MICHAEL J, et al. GLUE: a multi-task benchmark and analysis platform for natural language understanding [C]// Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. Stroudsburg: ACL, 2018: 353-355. |
| 35 | NOVIKOVA J, DUŠEK O, RIESER V. The E2E dataset: new challenges for end-to-end generation [C]// Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue. Stroudsburg: ACL, 2017: 201-206. |
| 36 | XIA M, GAO T, ZENG Z, et al. Sheared LLaMA: accelerating language model pre-training via structured pruning [EB/OL]. [2024-03-22]. . |
| [1] | 王泉, 曹心雨, 陈祺东. 面向车路协同的路侧交通目标检测模型及部署[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 1016-1024. |
| [2] | 徐超, 张淑芬, 陈海田, 彭璐璐, 张帅华. 基于自适应差分隐私与客户选择优化的联邦学习方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 482-489. |
| [3] | 王心妍, 杜嘉程, 钟李红, 徐旺旺, 刘伯宇, 佘维. 融合电力数据的纵向联邦学习企业排污预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 518-525. |
| [4] | 陈海田, 陈学斌, 马锐奎, 张帅华. 面向遥感数据的基于本地差分隐私的联邦学习隐私保护方案[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 506-517. |
| [5] | 刘弘业, 陈锡爱, 曾涛. 基于选择状态空间的三模态适配器[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 411-420. |
| [6] | 任志强, 陈学斌. 基于历史模型更新的自适应防御机制FedAud[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 490-496. |
| [7] | 朱亮, 慕京哲, 左洪强, 谷晶中, 朱付保. 基于联邦图神经网络的位置隐私保护推荐方案[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 136-143. |
| [8] | 晏燕, 钱星颖, 闫鹏斌, 杨杰. 位置大数据的联邦学习统计预测与差分隐私保护方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 127-135. |
| [9] | 张淑芬, 张宏扬, 任志强, 陈学斌. 联邦学习的公平性综述[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 1-14. |
| [10] | 陈廷伟, 张嘉诚, 王俊陆. 面向联邦学习的随机验证区块链构建[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2770-2776. |
| [11] | 孙焕良, 王思懿, 刘俊岭, 许景科. 社交媒体数据中水灾事件求助信息提取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2437-2445. |
| [12] | 沈哲远, 杨珂珂, 李京. 基于双流神经网络的个性化联邦学习方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2319-2325. |
| [13] | 陈学斌, 任志强, 张宏扬. 联邦学习中的安全威胁与防御措施综述[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1663-1672. |
| [14] | 罗玮, 刘金全, 张铮. 融合秘密分享技术的双重纵向联邦学习框架[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1872-1879. |
| [15] | 李雪, 姚光乐, 王洪辉, 李军, 周皓然, 叶绍泽. 基于样本增量学习的遥感影像分类[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 732-736. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||