


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (5): 1379-1386.DOI: 10.11772/j.issn.1001-9081.2024060802
• 第十届中国数据挖掘会议 • 上一篇
陈鹏宇1, 聂秀山1,2, 李南君2,3, 李拓2,3
收稿日期:2024-06-21
修回日期:2024-07-19
接受日期:2024-07-23
发布日期:2024-08-19
出版日期:2025-05-10
通讯作者:
聂秀山
作者简介:陈鹏宇(2000—),男,山东德州人,硕士研究生,CCF会员,主要研究方向:计算机视觉基金资助:Pengyu CHEN1, Xiushan NIE1,2, Nanjun LI2,3, Tuo LI2,3
Received:2024-06-21
Revised:2024-07-19
Accepted:2024-07-23
Online:2024-08-19
Published:2025-05-10
Contact:
Xiushan NIE
About author:CHEN Pengyu, born in 2000, M. S. candidate. His research interests include computer vision.Supported by:摘要:
针对半监督视频目标分割(VOS)领域中基于记忆的方法存在由于目标交互造成的物体遮挡以及背景中类似对象或噪声的干扰等问题,提出一种基于时空解耦和区域鲁棒性增强的半监督VOS方法。首先,构建一个结构化Transformer架构去除所有像素共有的特征信息,突出每个像素之间的差异,深入挖掘视频帧中目标的关键特征;其次,解耦当前帧与长期记忆帧之间的相似性,区分为时空相关性和目标重要性2个关键维度,使得对像素级时空特征和目标特征的分析更精确,从而解决由目标交互造成的物体遮挡问题;最后,设计一个区域条形注意力(RSA)模块,利用长期记忆中的目标位置信息增强对前景区域的关注度并抑制背景噪声。实验结果表明,所提方法在DAVIS 2017验证集上比重新训练的AOT(Associating Objects with Transformers)模型的J&F指标高1.7个百分点,在YouTube-VOS 2019验证集上比重新训练的AOT模型的总分高1.6个百分点。可见所提方法可有效解决半监督VOS存在的问题。
中图分类号:
陈鹏宇, 聂秀山, 李南君, 李拓. 基于时空解耦和区域鲁棒性增强的半监督视频目标分割方法[J]. 计算机应用, 2025, 45(5): 1379-1386.
Pengyu CHEN, Xiushan NIE, Nanjun LI, Tuo LI. Semi-supervised video object segmentation method based on spatio-temporal decoupling and regional robustness enhancement[J]. Journal of Computer Applications, 2025, 45(5): 1379-1386.
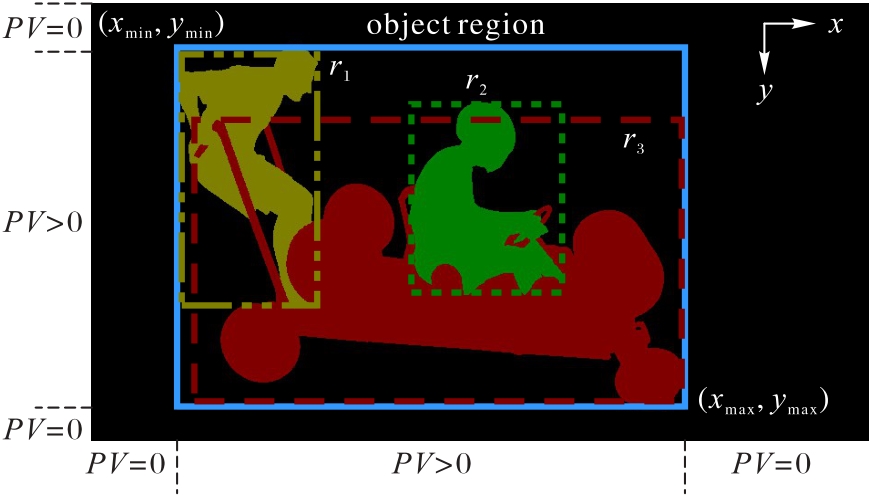
图1 目标区域计算说明
Fig. 1 Illustration of object region computation
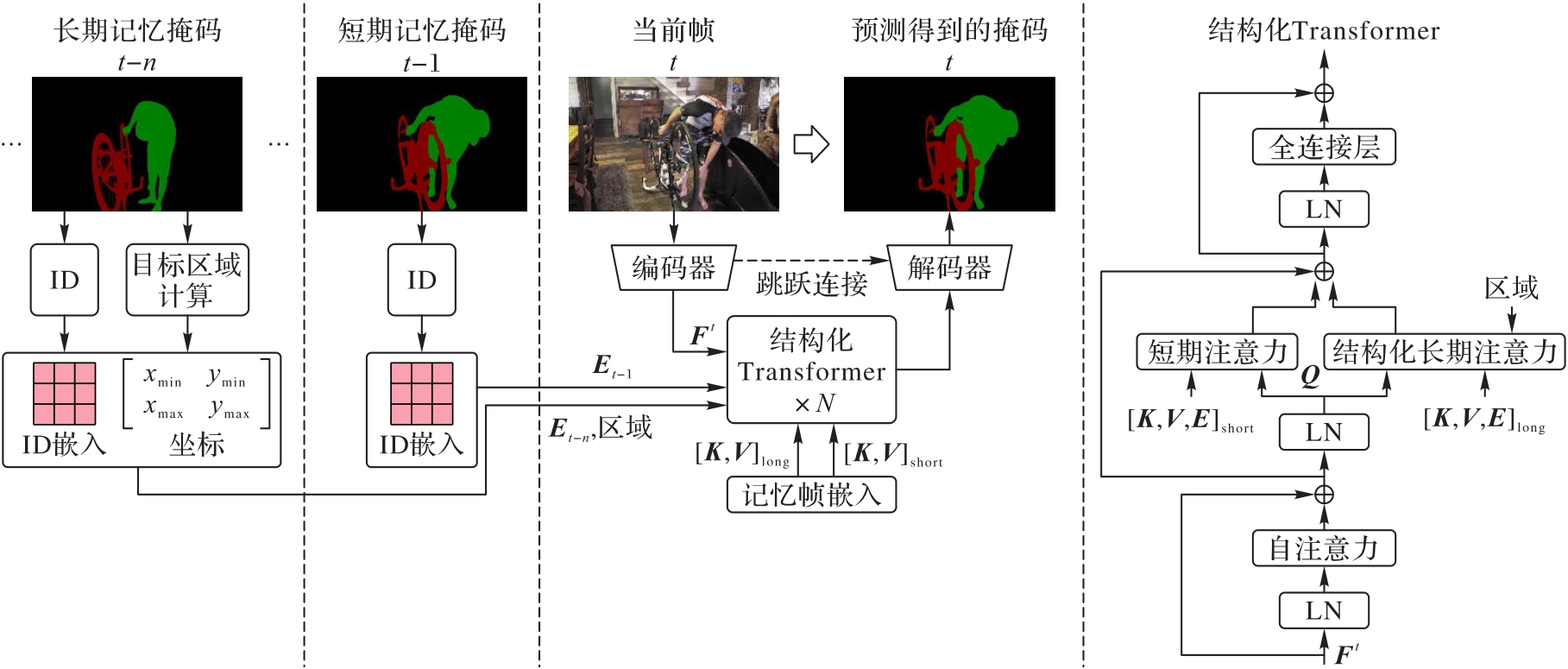
图2 本文方法的模型结构
Fig. 2 Model structure of proposed method
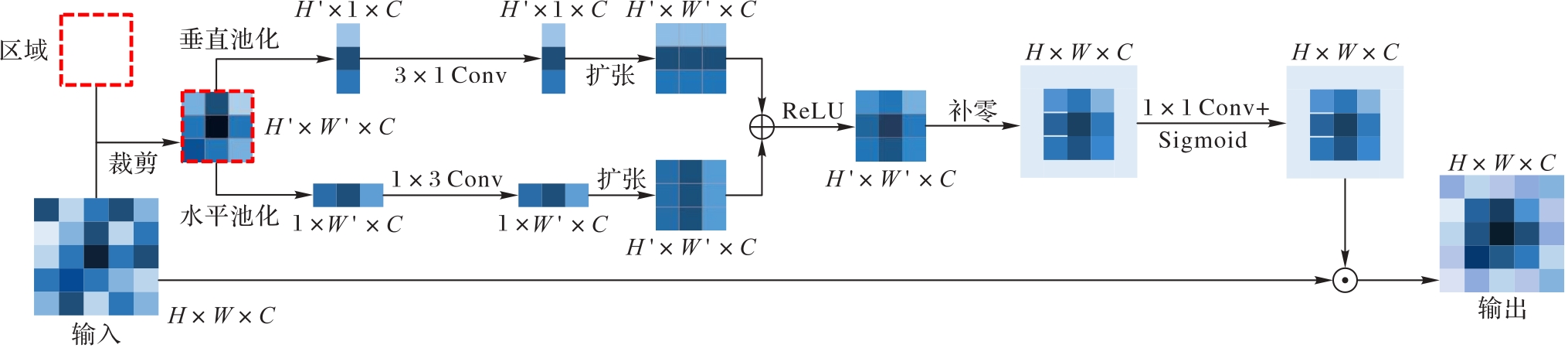
图3 RSA模块实现细节
Fig. 3 Implementation details of RSA
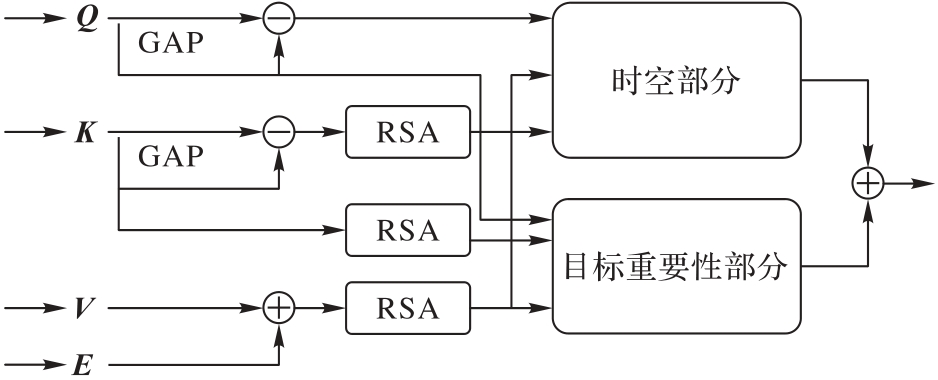
图4 结构化长期注意力的细节
Fig. 4 Details of structural long-term attention
| 模型 | +S | J&F | J度量 | F度量 | FPS |
|---|---|---|---|---|---|
| LWL[ | 81.6 | 79.1 | 84.1 | 14.0 | |
| STM[ | √ | 81.8 | 79.2 | 84.3 | 6.3 |
| CFBI[ | 81.9 | 79.1 | 84.6 | 5.0 | |
| KMN[ | √ | 82.8 | 80.0 | 85.6 | |
| LCM[ | √ | 83.5 | 80.5 | 86.5 | 8.0 |
| MiVOS[ | √ | 84.5 | 81.7 | 87.4 | 11.2 |
| HMMN[ | √ | 84.7 | 81.9 | 87.5 | 9.6 |
| AOT[ | √ | 85.2 | 82.5 | 87.9 | 18.7 |
| AOT*[ | 79.9 | 77.1 | 82.8 | 15.3 | |
| STRSA | 81.6 | 78.6 | 84.5 | 6.6 |
表1 不同模型在DAVIS 2017验证集上的性能对比
Tab. 1 Performance comparison of different models on DAVIS 2017 validation set
| 模型 | +S | J&F | J度量 | F度量 | FPS |
|---|---|---|---|---|---|
| LWL[ | 81.6 | 79.1 | 84.1 | 14.0 | |
| STM[ | √ | 81.8 | 79.2 | 84.3 | 6.3 |
| CFBI[ | 81.9 | 79.1 | 84.6 | 5.0 | |
| KMN[ | √ | 82.8 | 80.0 | 85.6 | |
| LCM[ | √ | 83.5 | 80.5 | 86.5 | 8.0 |
| MiVOS[ | √ | 84.5 | 81.7 | 87.4 | 11.2 |
| HMMN[ | √ | 84.7 | 81.9 | 87.5 | 9.6 |
| AOT[ | √ | 85.2 | 82.5 | 87.9 | 18.7 |
| AOT*[ | 79.9 | 77.1 | 82.8 | 15.3 | |
| STRSA | 81.6 | 78.6 | 84.5 | 6.6 |
| 方法 | +S | 总分 | 已知类 | 未知类 | ||
|---|---|---|---|---|---|---|
| J | F | J | F | |||
| STM[ | √ | 79.2 | 79.6 | 83.6 | 73.0 | 80.6 |
| KMN[ | √ | 80.0 | 80.4 | 84.5 | 73.8 | 81.4 |
| MiVOS[ | √ | 80.3 | 79.3 | 83.7 | 75.3 | 82.8 |
| LWL[ | √ | 81.0 | 79.6 | 83.8 | 76.4 | 84.2 |
| CFBI[ | 81.0 | 80.6 | 85.1 | 75.2 | 83.0 | |
| HMMN[ | √ | 82.5 | 81.7 | 86.1 | 77.3 | 85.0 |
| JITL[ | 82.8 | 80.8 | 84.8 | 79.0 | 86.6 | |
| AOT[ | √ | 85.3 | 83.9 | 88.8 | 79.9 | 88.5 |
| AOT*[ | 80.5 | 79.8 | 84.2 | 74.7 | 83.2 | |
| STRSA | 82.1 | 81.4 | 86.0 | 76.4 | 84.8 | |
表2 不同方法在YouTube-VOS 2019验证集上的性能对比
Tab. 2 Performance comparison of different methods on YouTube-VOS 2019 validation set
| 方法 | +S | 总分 | 已知类 | 未知类 | ||
|---|---|---|---|---|---|---|
| J | F | J | F | |||
| STM[ | √ | 79.2 | 79.6 | 83.6 | 73.0 | 80.6 |
| KMN[ | √ | 80.0 | 80.4 | 84.5 | 73.8 | 81.4 |
| MiVOS[ | √ | 80.3 | 79.3 | 83.7 | 75.3 | 82.8 |
| LWL[ | √ | 81.0 | 79.6 | 83.8 | 76.4 | 84.2 |
| CFBI[ | 81.0 | 80.6 | 85.1 | 75.2 | 83.0 | |
| HMMN[ | √ | 82.5 | 81.7 | 86.1 | 77.3 | 85.0 |
| JITL[ | 82.8 | 80.8 | 84.8 | 79.0 | 86.6 | |
| AOT[ | √ | 85.3 | 83.9 | 88.8 | 79.9 | 88.5 |
| AOT*[ | 80.5 | 79.8 | 84.2 | 74.7 | 83.2 | |
| STRSA | 82.1 | 81.4 | 86.0 | 76.4 | 84.8 | |

图5 DAVIS 2017验证集的可视化结果
Fig. 5 Visualization results on DAVIS 2017validation set
| 方法 | ST | RSA | 总分 | 已知类F度量 | 未知类F度量 |
|---|---|---|---|---|---|
| 基线 | 80.5 | 84.2 | 83.2 | ||
| V1 | √ | 81.3 | 84.7 | 84.1 | |
| STRSA | √ | √ | 82.1 | 86.0 | 84.8 |
表3 YouTube-VOS 2019验证集上的消融实验结果
Tab. 3 Ablation experimental results on YouTube-VOS 2019 validation set
| 方法 | ST | RSA | 总分 | 已知类F度量 | 未知类F度量 |
|---|---|---|---|---|---|
| 基线 | 80.5 | 84.2 | 83.2 | ||
| V1 | √ | 81.3 | 84.7 | 84.1 | |
| STRSA | √ | √ | 82.1 | 86.0 | 84.8 |
| 变体 | 目标区域 | SAP | J&F | J度量 | F度量 |
|---|---|---|---|---|---|
| V1 | √ | 76.5 | 73.8 | 79.1 | |
| V2 | √ | 78.8 | 76.4 | 81.1 | |
| RSA | √ | √ | 79.3 | 76.9 | 81.7 |
表4 DAVIS 2017验证集上RSA模块不同设置的消融实验结果
Tab. 4 Ablation experimental results of different settings in RSA module on DAVIS 2017 validation set
| 变体 | 目标区域 | SAP | J&F | J度量 | F度量 |
|---|---|---|---|---|---|
| V1 | √ | 76.5 | 73.8 | 79.1 | |
| V2 | √ | 78.8 | 76.4 | 81.1 | |
| RSA | √ | √ | 79.3 | 76.9 | 81.7 |
| 1 | COHEN I, MEDIONI G. Detecting and tracking moving objects for video surveillance[C]// Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition — Volume 2. Piscataway: IEEE, 1999, 2: 319-325. |
| 2 | 胡学敏,童秀迟,郭琳,等.基于深度视觉注意神经网络的端到端自动驾驶模型[J].计算机应用, 2020,40(7):1926-1931. |
| HU X M, TONG X C, GUO L, et al. End-to-end autonomous driving model based on deep visual attention neural network[J]. Journal of Computer Applications, 2020, 40(7): 1926-1931. | |
| 3 | CHAKRABORTY B, SARMA D, BHUYAN M K, et al. Review of constraints on vision‐based gesture recognition for human-computer interaction[J]. IET Computer Vision, 2018, 12(1): 3-15. |
| 4 | HU L, ZHANG P, ZHANG B, et al. Learning position and target consistency for memory-based video object segmentation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 4142-4152. |
| 5 | LIANG Y, LI X, JAFARI N, et al. Video object segmentation with adaptive feature bank and uncertain-region refinement[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 3430-3441. |
| 6 | HU Y T, HUANG J B, SCHWING A G. VideoMatch: matching based video object segmentation[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11212. Cham: Springer, 2018: 56-73. |
| 7 | YANG Z, WEI Y, YANG Y. Collaborative video object segmentation by foreground-background integration[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12350. Cham: Springer, 2020: 332-348. |
| 8 | PORTALÉS C, GIMENO J, SALVADOR A, et al. Mixed reality annotation of robotic-assisted surgery videos with real-time tracking and stereo matching[J]. Computers and Graphics, 2023, 110: 125-140. |
| 9 | CHENG H K, TAI Y-W, TANG C-K. Rethinking space-time networks with improved memory coverage for efficient video object segmentation[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 11781-11794. |
| 10 | OH S W, LEE J Y, XU N, et al. Video object segmentation using space-time memory networks[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9225-9234. |
| 11 | WU Q, YANG T, WU W, et al. Scalable video object segmentation with simplified framework[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 13833-13843. |
| 12 | YANG Z, WEI Y, YANG Y. Associating objects with transformers for video object segmentation[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 2491-2502. |
| 13 | YIN M, YAO Z, CAO Y, et al. Disentangled non-local neural networks[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12360. Cham: Springer, 2020: 191-207. |
| 14 | CHENG H K, Y-W TAIO, TANG C-K. Modular interactive video object segmentation: interaction-to-mask, propagation and difference-aware fusion[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 5555-5564. |
| 15 | PONT-TUSET J, PERAZZI F, CAELLES S, et al. The 2017 DAVIS challenge on video object segmentation[EB/OL]. [2024-01-11]. . |
| 16 | XU N, YANG L, FAN Y, et al. YouTube-VOS: a large-scale video object segmentation benchmark[EB/OL]. [2024-01-15]. . |
| 17 | K-K MAMINIS, CCELLES S, CHEN Y H, et al. Video object segmentation without temporal information[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(6): 1515-1530. |
| 18 | VENTURA C, BELLVER M, GIRBAU A, et al. RVOS: end-to-end recurrent network for video object segmentation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 5272-5281. |
| 19 | LIN H, QI X, JIA J. AGSS-VOS: attention guided single-shot video object segmentation[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 3948-3956. |
| 20 | CAELLES S, K-K MANINIS, PONT-TUSET J, et al. One-shot video object segmentation[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5320-5329. |
| 21 | ZHANG Y, WU Z, PENG H, et al. A transductive approach for video object segmentation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 6947-6956. |
| 22 | KUMA A, IRSOY O, ONDRUSKA P, et al. Ask me anything: dynamic memory networks for natural language processing[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: ACM, 2016: 1378-1387. |
| 23 | BHAT G, LAWIN F J, DANELLJAN M, et al. Learning what to learn for video object segmentation[C]// Proceedings of the 16th European Conference on Computer Vision, LNCS 12347. Cham: Springer, 2020: 777-794. |
| 24 | SEONG H, HYUN J, KIM E. Kernelized memory network for video object segmentation[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12367. Cham: Springer, 2020: 629-645. |
| 25 | SEONG H, OH S W, LEE J-Y, et al. Hierarchical memory matching network for video object segmentation[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 12869-12878. |
| 26 | LIANG S, SHEN X, HUANG J, et al. Video object segmentation with dynamic memory networks and adaptive object alignment[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 8045-8054. |
| 27 | HOU W, QIN Z, XI X, et al. Learning disentangled representation for self-supervised video object segmentation[J]. Neurocomputing, 2022, 481: 270-280. |
| 28 | VASWANI A, SHAZEER N, PARAMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 29 | YANG Y, WEI H, SUN Z, et al. S2OSC: a holistic semi-supervised approach for open set classification[J]. ACM Transactions on Knowledge Discovery from Data, 2022, 16(2): No.34. |
| 30 | DUKE B, AHMED A, WOLF C, et al. SSTVOS: sparse spatiotemporal Transformers for video object segmentation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 5908-5917. |
| 31 | MAO Y, WANG N, ZHOU W, et al. Joint inductive and transductive learning for video object segmentation[C]//Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9650-9659. |
| 32 | LIN T-Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 936-944. |
| 33 | HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2980-2988. |
| [1] | 袁宝华, 陈佳璐, 王欢. 融合多尺度语义和双分支并行的医学图像分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 988-995. |
| [2] | 王雅伦, 张仰森, 朱思文. 面向知识推理的位置编码标题生成模型[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 345-353. |
| [3] | 梁杰涛, 罗兵, 付兰慧, 常青玲, 李楠楠, 易宁波, 冯其, 何鑫, 邓辅秦. 基于坐标几何采样的点云配准方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 214-222. |
| [4] | 黄云川, 江永全, 黄骏涛, 杨燕. 基于元图同构网络的分子毒性预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2964-2969. |
| [5] | 杨鑫, 陈雪妮, 吴春江, 周世杰. 结合变种残差模型和Transformer的城市公路短时交通流预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2947-2951. |
| [6] | 李金金, 桑国明, 张益嘉. APK-CNN和Transformer增强的多域虚假新闻检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2674-2682. |
| [7] | 方介泼, 陶重犇. 应对零日攻击的混合车联网入侵检测系统[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2763-2769. |
| [8] | 任烈弘, 黄铝文, 田旭, 段飞. 基于DFT的频率敏感双分支Transformer多变量长时间序列预测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2739-2746. |
| [9] | 贾洁茹, 杨建超, 张硕蕊, 闫涛, 陈斌. 基于自蒸馏视觉Transformer的无监督行人重识别[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2893-2902. |
| [10] | 丁宇伟, 石洪波, 李杰, 梁敏. 基于局部和全局特征解耦的图像去噪网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2571-2579. |
| [11] | 邓凯丽, 魏伟波, 潘振宽. 改进掩码自编码器的工业缺陷检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2595-2603. |
| [12] | 杨帆, 邹窈, 朱明志, 马振伟, 程大伟, 蒋昌俊. 基于图注意力Transformer神经网络的信用卡欺诈检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2634-2642. |
| [13] | 张英俊, 李牛牛, 谢斌红, 张睿, 陆望东. 课程学习指导下的半监督目标检测框架[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2326-2333. |
| [14] | 李大海, 王忠华, 王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2175-2182. |
| [15] | 黎施彬, 龚俊, 汤圣君. 基于Graph Transformer的半监督异配图表示学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1816-1823. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||