


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (9): 2737-2746.DOI: 10.11772/j.issn.1001-9081.2024091316
• 人工智能 • 上一篇
俞浩1,2,3, 范菁1,2,3( ), 孙伊航1,2,3, 董华1,2,3, 郗恩康1,2,3
), 孙伊航1,2,3, 董华1,2,3, 郗恩康1,2,3
收稿日期:2024-09-18
修回日期:2024-12-09
接受日期:2024-12-10
发布日期:2025-01-13
出版日期:2025-09-10
通讯作者:
范菁
作者简介:俞浩(2000—),男,湖北咸宁人,硕士研究生,CCF会员,主要研究方向:联邦学习、分布式优化、边缘计算基金资助:
Hao YU1,2,3, Jing FAN1,2,3(), Yihang SUN1,2,3, Hua DONG1,2,3, Enkang XI1,2,3
Received:2024-09-18
Revised:2024-12-09
Accepted:2024-12-10
Online:2025-01-13
Published:2025-09-10
Contact:
Jing FAN
About author:YU Hao, born in 2000, M. S. candidate. His research interests include federated learning, distributed optimization, edge computing.Supported by:摘要:
联邦学习是一种强调隐私保护的分布式机器学习框架。然而,它在应对统计异质性问题时面临显著挑战。统计异质性源于参与节点间的数据分布差异,可能导致模型更新偏差、全局模型性能下降以及收敛不稳定等问题。针对上述问题,首先,详细分析统计异质性带来的主要问题,包括特征分布不一致、标签分布不均衡、数据量不对称以及数据质量参差不齐等;其次,对现有的联邦学习统计异质性解决方案进行系统综述,包括局部校正、聚类方法、客户端选择优化、聚合策略调整、数据共享、知识蒸馏以及解耦优化等,并逐一评估它们的优缺点与适用场景;最后,探讨了未来的相关研究方向,如设备计算能力感知、模型异构适应、隐私安全机制的优化以及跨任务迁移能力的提升,为应对实际应用中的统计异质性提供参考。
中图分类号:
俞浩, 范菁, 孙伊航, 董华, 郗恩康. 联邦学习统计异质性综述[J]. 计算机应用, 2025, 45(9): 2737-2746.
Hao YU, Jing FAN, Yihang SUN, Hua DONG, Enkang XI. Survey of statistical heterogeneity in federated learning[J]. Journal of Computer Applications, 2025, 45(9): 2737-2746.
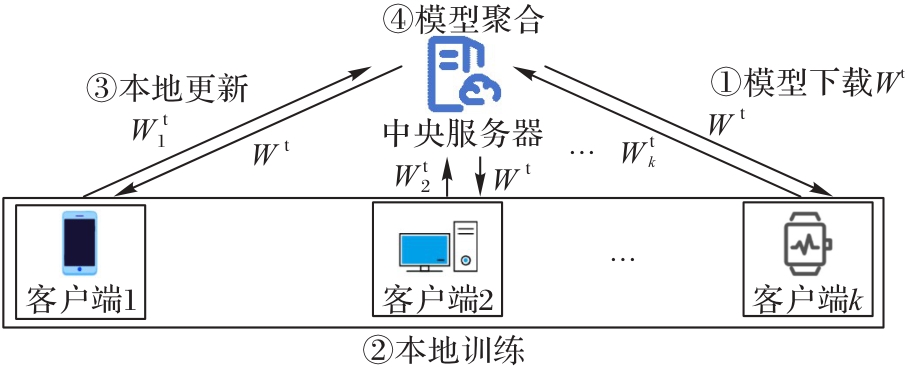
图1 联邦学习的过程
Fig. 1 Process of federated learning
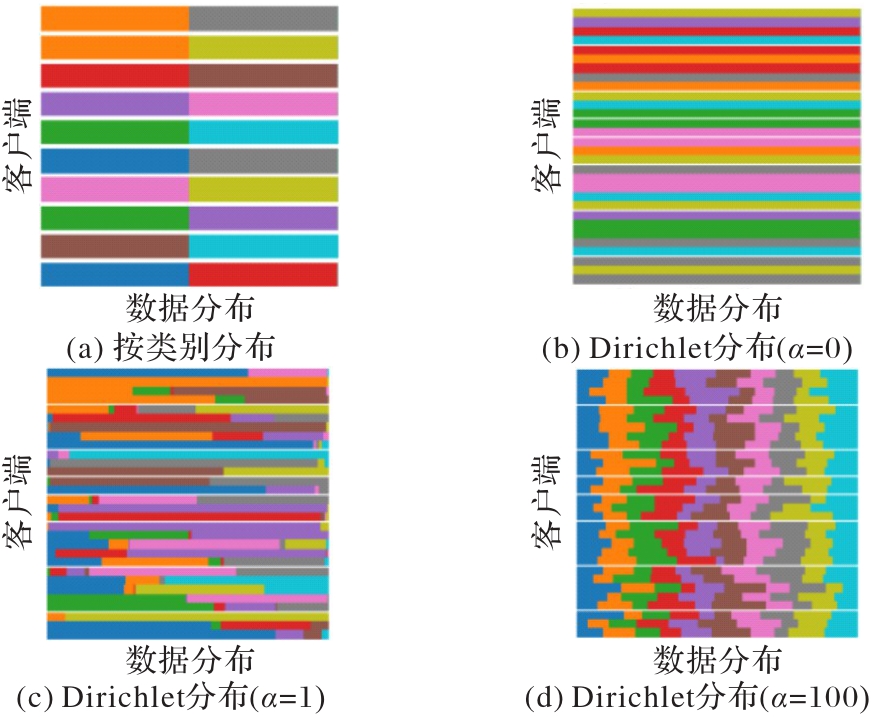
图2 统计异质性中的数据分布
Fig. 2 Data distribution with statistical heterogeneity
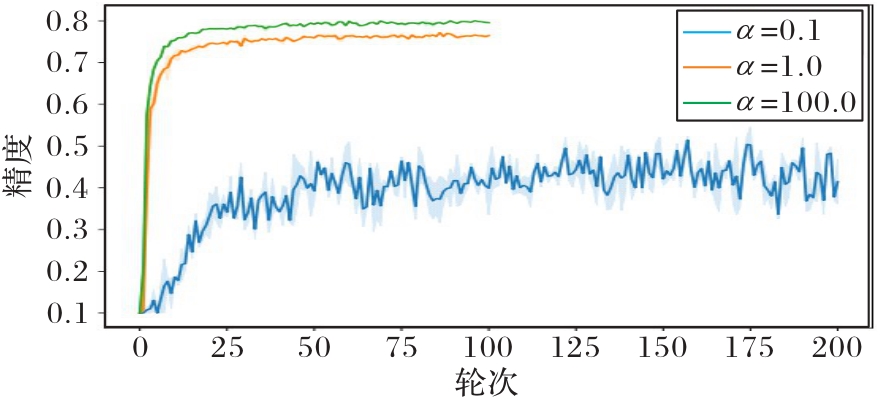
图3 数据分布对精度的影响
Fig. 3 Influence of data distribution on accuracy
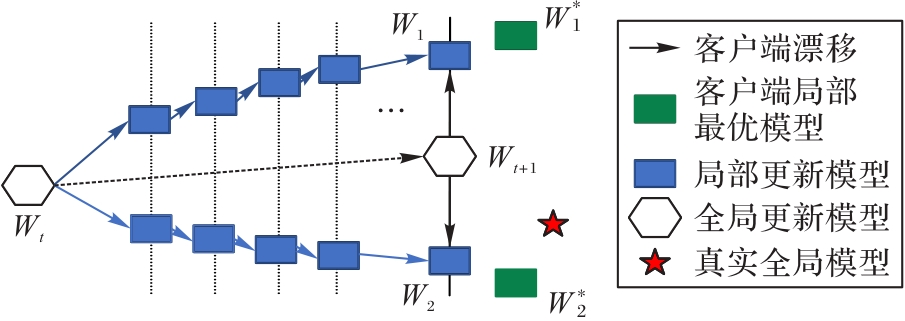
图4 客户端漂移现象
Fig. 4 Client drift phenomenon
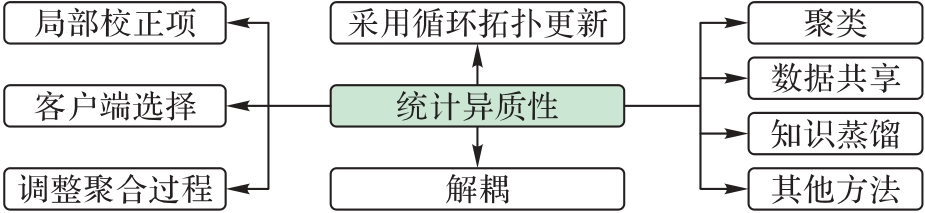
图5 现有解决方案的类型
Fig. 5 Types of existing solutions
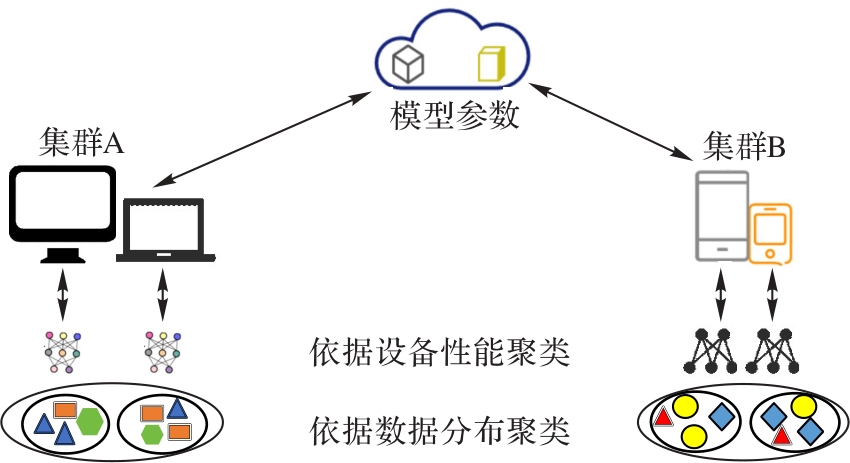
图6 聚类方法的基本原理
Fig. 6 Basic principle of clustering method
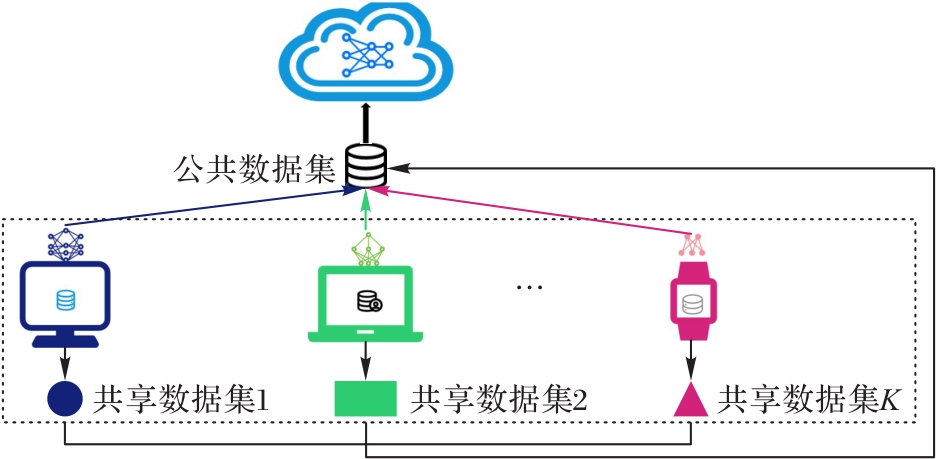
图7 引入共享数据的全局聚合方式
Fig. 7 Global aggregation approach introducing shared data
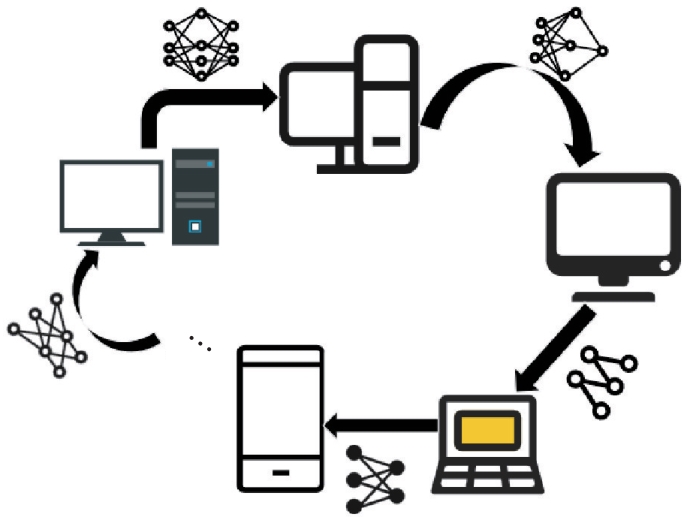
图8 循环拓扑结构中的客户端传递
Fig. 8 Client passing in cyclic topology structure
| [1] | NAAS S A, MOHAMMED T, SIGG S. A global brain fuelled by local intelligence: optimizing mobile services and networks with AI[C]// Proceedings of the 16th International Conference on Mobility, Sensing and Networking. Piscataway: IEEE, 2020: 23-32. |
| [2] | 梁天恺,曾碧,陈光. 联邦学习综述:概念、技术、应用与挑战[J]. 计算机应用, 2022, 42(12): 3651-3662. |
| LIANG T K, ZENG B, CHEN G. Federated learning survey: concepts, technologies, applications and challenges [J]. Journal of Computer Applications, 2022, 42(12): 3651-3662. | |
| [3] | DENG Y, YAN X. Federated learning on heterogeneous opportunistic networks [C]// Proceedings of the 5th International Seminar on Artificial Intelligence, Networking and Information Technology. Piscataway: IEEE, 2024: 447-451. |
| [4] | XU C, QU Y, XIANG Y, et al. Asynchronous federated learning on heterogeneous devices: a survey [J]. Computer Science Review, 2023, 50: No.100595. |
| [5] | LI D, WANG J. FedMD: heterogeneous federated learning via model distillation [EB/OL]. [2024-09-09].. |
| [6] | 张瑞麟,杜晋华,尹浩. 跨设备联邦学习中的客户端选择算法[J].软件学报, 2024, 35(12): 5725-5740. |
| ZHANG R L, DU J H, YIN H. Client selection algorithm in cross-device federated learning [J]. Journal of Software, 2024, 35(12): 5725-5740. | |
| [7] | MORA A, BUJARI A, BELLAVISTA P. Enhancing generalization in federated learning with heterogeneous data: a comparative literature review [J]. Future Generation Computer Systems, 2024, 157: 1-15. |
| [8] | ALSHARIF M H, KANNADASAN R, WEI W, et al. A contemporary survey of recent advances in federated learning: taxonomies, applications, and challenges [J]. Internet of Things, 2024, 27: No.101251. |
| [9] | GAO D, YAO X, YANG Q. A survey on heterogeneous federated learning [EB/OL]. [2024-05-11]. . |
| [10] | KONEČNÝ J, McMAHAN H B, RAMAGE D, et al. Federated optimization: distributed intelligence [EB/OL]. [2024-09-02].. |
| [11] | McMAHAN H B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data [C]// Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2017: 1273-1282. |
| [12] | LUO M, CHEN F, HU D, et al. No fear of heterogeneity: classifier calibration for federated learning with non-IID data [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 5972-5984. |
| [13] | YANG C, XU M, WANG Q, et al. FLASH: heterogeneity-aware federated learning at scale [J]. IEEE Transactions on Mobile Computing, 2024, 23(1): 483-500. |
| [14] | LI T, SAHU A K, ZAHEER M, et al. Federated optimization in heterogeneous networks [EB/OL]. [2024-05-19].. |
| [15] | KARIMIREDDY S P, KALE S, MOHRI M, et al. SCAFFOLD: stochastic controlled averaging for on-device federated learning[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 5132-5143. |
| [16] | HSU T H, QI H, BROWN M. Measuring the effects of non-identical data distribution for federated visual classification [EB/OL]. [2024-10-13].. |
| [17] | LI Q, HE B, SONG D. Model-contrastive federated learning [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10708-10717. |
| [18] | ACAR D A E, ZHAO Y, NAVARRO R M, et al. Federated learning based on dynamic regularization [EB/OL]. [2024-11-08]. . |
| [19] | ZHU Z, HONG J, ZHOU J. Data-free knowledge distillation for heterogeneous federated learning [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 12878-12889. |
| [20] | SATTLER F, MÜLLER K R, SAMEK W. Clustered federated learning: model-agnostic distributed multitask optimization under privacy constraints [J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(8): 3710-3722. |
| [21] | DUAN M, LIU D, JI X, et al. Flexible clustered federated learning for client-level data distribution shift [J]. IEEE Transactions on Parallel and Distributed Systems, 2022, 33(11): 2661-2674. |
| [22] | LI Z, GUAN Z, YUAN S, et al. ROCFL: a robust clustered federated learning framework towards heterogeneous data [C]// Proceedings of the 2023 International Conference on Intelligent Communication and Networking. Piscataway: IEEE, 2023: 259-264. |
| [23] | CALIŃSKI T, HARABASZ J. A dendrite method for cluster analysis [J]. Communications in Statistics-theory and Methods, 1974, 3(1): 1-27. |
| [24] | JIN B, HUANG D, CHEN N, et al. Federated learning with class-imbalanced heterogeneous [C]// Proceedings of the IEEE 14th International Symposium on Parallel Architectures, Algorithms and Programming. Piscataway: IEEE, 2023: 1-6. |
| [25] | GOETZ J, MALIK K, BUI D, et al. Active federated learning [EB/OL]. [2024-10-26]. . |
| [26] | CHO Y J, WANG J, JOSHI G. Client selection in federated learning: convergence analysis and power-of-choice selection strategies [EB/OL]. [2024-10-03].. |
| [27] | TANG M, NING X, WANG Y, et al. FedCor: correlation-based active client selection strategy for heterogeneous federated learning[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 10092-10101. |
| [28] | NAAS S A, SIGG S. Fast converging federated learning with non-IID data [C]// Proceedings of the IEEE 97th Vehicular Technology Conference. Piscataway: IEEE, 2023: 1-6. |
| [29] | PENE P, LIAO W, YU W. Incentive design for heterogeneous client selection: a robust federated learning approach [J]. IEEE Internet of Things Journal, 2024, 11(4): 5939-5950. |
| [30] | WANG J, LIU Q, LIANG H, et al. Tackling the objective inconsistency problem in heterogeneous federated optimization[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 7611-7623. |
| [31] | WANG Q, LI Q, GUO B, et al. Efficient federated learning with smooth aggregation for non-IID data from multiple edges [C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 9006-9010. |
| [32] | LI X C, ZHAN D C. FedRS: federated learning with restricted softmax for label distribution non-IID data [C]// Proceedings of the 27th ACM SGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2021: 995-1005. |
| [33] | LIU C, ALGHAZZAWI D M, CHENG L, et al. Disentangling client contributions: improving federated learning accuracy in the presence of heterogeneous data [C]// Proceedings of the 2023 IEEE International Conference on Parallel and Distributed Processing with Applications, Big Data and Cloud Computing, Sustainable Computing and Communications, Social Computing and Networking. Piscataway: IEEE, 2023: 381-387. |
| [34] | LI J, LIU X, MAHMOODI T. Federated learning in heterogeneous wireless networks with adaptive mixing aggregation and computation reduction [J]. IEEE Open Journal of the Communications Society, 2024, 5: 2164-2182. |
| [35] | ZHANG J, HUA Y, WANG H, et al. FedALA: adaptive local aggregation for personalized federated learning [C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023, 37(9): 11237-11244. |
| [36] | BHATTI D M S, NAM H. A robust aggregation approach for heterogeneous federated learning [C]// Proceedings of the 14th International Conference on Ubiquitous and Future Networks. Piscataway: IEEE, 2023: 300-304. |
| [37] | CHEN Y, SUN X, JIN Y. Communication-efficient federated deep learning with layerwise asynchronous model update and temporally weighted aggregation [J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(10): 4229-4238. |
| [38] | 张红艳,张玉,曹灿明. 一种解决数据异构问题的联邦学习方法[J]. 计算机应用研究, 2024, 41(3): 713-720. |
| ZHANG H Y, ZHANG Y, CAO C M. Effective method to solve problem of data heterogeneity in federated learning [J]. Application Research of Computers, 2024, 41(3): 713-720. | |
| [39] | 刘吉强,王雪微,梁梦晴,等. 基于共享数据集和梯度补偿的分层联邦学习框架[J]. 信息网络安全, 2023, 23(12): 10-20. |
| LIU J Q, WANG X W, LIANG M Q, et al. A hierarchical federated learning framework based on shared datasets and gradient compensation [J]. Netinfo Security, 2023, 23(12): 10-20. | |
| [40] | LIU L, ZHANG J, SONG S H, et al. Client-edge-cloud hierarchical federated learning [C]// Proceedings of the 2020 IEEE International Conference on Communications. Piscataway: IEEE, 2020: 1-6. |
| [41] | JIANG D, SHAN C, ZHANG Z. Federated learning algorithm based on knowledge distillation [C]// Proceedings of the 2020 International Conference on Artificial Intelligence and Computer Engineering. Piscataway: IEEE, 2020: 163-167. |
| [42] | CHAN Y H, NGAI E C H. FedHe: heterogeneous models and communication-efficient federated learning [C]// Proceedings of the 17th International Conference on Mobility, Sensing and Networking. Piscataway: IEEE, 2021: 207-214. |
| [43] | AHMAD S, ARAL A. FedCD: personalized federated learning via collaborative distillation [C]// Proceedings of the IEEE/ACM 15th International Conference on Utility and Cloud Computing. Piscataway: IEEE, 2022: 189-194. |
| [44] | LE H Q, NGUYEN L X, PARK S B, et al. Layer-wise knowledge distillation for cross-device federated learning [C]// Proceedings of the 2023 International Conference on Information Networking. Piscataway: IEEE, 2023: 526-529. |
| [45] | SUN C, JIANG T, ZONOUZ S, et al. Fed2KD: heterogeneous federated learning for pandemic risk assessment via two-way knowledge distillation [C]// Proceedings of the 17th Wireless On-Demand Network Systems and Services Conference. Piscataway: IEEE, 2022: 1-8. |
| [46] | GAO L, FU H, LI L, et al. FedDC: federated learning with non-IID data via local drift decoupling and correction [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 10102-10111. |
| [47] | ZHENG S, YE T, LI X, et al. Federated learning via consensus mechanism on heterogeneous data: a new perspective on convergence [C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 7595-7599. |
| [48] | CHANG K, BALACHANDAR N, LAM C, et al. Distributed deep learning networks among institutions for medical imaging [J]. Journal of the American Medical Informatics Association, 2018, 25(8): 945-954. |
| [49] | FEI L, LOO C K, SHIUNG L W, et al. FedLoop: a P2P personalized federated learning method on heterogeneous data[C]// Proceedings of the 2023 IEEE Symposium Series on Computational Intelligence. Piscataway: IEEE, 2023: 1603-1606. |
| [50] | HU F, ZHOU W, LIAO K, et al. FedLoop: heterogeneity mitigation in federated learning [C]// Proceedings of the 42nd Chinese Control Conference. Piscataway: IEEE, 2023: 6159-6164. |
| [51] | SHENG T, SHEN C, LIU Y, et al. Modeling global distribution for federated learning with label distribution skew [J]. Pattern Recognition, 2023, 143: No.109724. |
| [52] | TAN Y, CHEN C, ZHUANG W, et al. Is heterogeneity notorious? taming heterogeneity to handle test-time shift in federated learning [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 27167-27180. |
| [53] | REGUIEG H, HANJRI M E, KAMILI M E, et al. A comparative evaluation of FedAvg and Per-FedAvg algorithms for Dirichlet distributed heterogeneous data [C]// Proceedings of the 10th International Conference on Wireless Networks and Mobile Communications. Piscataway: IEEE, 2023: 1-6. |
| [54] | MISHRA R, GUPTA H P, BANGA G, et al. Fed-RAC: resource- aware clustering for tackling heterogeneity of participants in federated learning [J]. IEEE Transactions on Parallel and Distributed Systems, 2024, 35(7): 1207-1220. |
| [55] | SHKURTI L, SELIMI M. BACA: bandwidth and CPU-aware adaptive federated learning for wireless environments [C]// Proceedings of the 13th Mediterranean Conference on Embedded Computing. Piscataway: IEEE, 2024: 1-5. |
| [56] | LIANG Y, OUYANG C, CHEN X. Adaptive asynchronous federated learning for heterogeneous clients [C]// Proceedings of the 18th International Conference on Computational Intelligence and Security. Piscataway: IEEE, 2022: 399-403. |
| [57] | TANG R, JIANG M. Enhancing federated learning: transfer learning insights [C]// Proceedings of the IEEE 3rd International Conference on Electrical Engineering, Big Data and Algorithms. Piscataway:IEEE,2024:1358-1362. |
| [58] | 王腾,霍峥,黄亚鑫,等. 联邦学习中的隐私保护技术研究综述[J]. 计算机应用, 2023, 43(2): 437-449. |
| WANG T, HUO Z, HUANG Y X, et al. Review on privacy-preserving technologies in federated learning [J]. Journal of Computer Applications, 2023, 43(2): 437-449. | |
| [59] | HITAJ B, ATENIESE G, PEREZ-CRUZ F. Deep models under the GAN: information leakage from collaborative deep learning[C]// Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2017: 603-618. |
| [60] | LIU J, HE X, SUN R, et al. Privacy-preserving data sharing scheme with FL via MPC in financial permissioned blockchain[C]// Proceedings of the 2021 IEEE International Conference on Communications. Piscataway: IEEE, 2021: 1-6. |
| [1] | 苏锦涛, 葛丽娜, 肖礼广, 邹经, 王哲. 联邦学习中针对后门攻击的检测与防御方案[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2399-2408. |
| [2] | 葛丽娜, 王明禹, 田蕾. 联邦学习的高效性研究综述[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2387-2398. |
| [3] | 张宏扬, 张淑芬, 谷铮. 面向个性化与公平性的联邦学习算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2123-2131. |
| [4] | 范亚州, 李卓. 能耗约束下分层联邦学习模型质量优化的节点协作机制[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1589-1594. |
| [5] | 张一鸣, 曹腾飞. 基于本地漂移和多样性算力的联邦学习优化算法[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1447-1454. |
| [6] | 陈庆礼, 郭渊博, 方晨. 面向数据异构的聚类联邦学习算法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1086-1094. |
| [7] | 项钰斐, 倪郑威. 基于演化博弈的分层联邦学习边缘联合动态分析[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1077-1085. |
| [8] | 林海力, 李京. 基于工作证明的联邦学习懒惰客户端识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 856-863. |
| [9] | 曾辉, 熊诗雨, 狄永正, 史红周. 基于剪枝的大模型联邦参数高效微调技术[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 715-724. |
| [10] | 徐超, 张淑芬, 陈海田, 彭璐璐, 张帅华. 基于自适应差分隐私与客户选择优化的联邦学习方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 482-489. |
| [11] | 王心妍, 杜嘉程, 钟李红, 徐旺旺, 刘伯宇, 佘维. 融合电力数据的纵向联邦学习企业排污预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 518-525. |
| [12] | 陈海田, 陈学斌, 马锐奎, 张帅华. 面向遥感数据的基于本地差分隐私的联邦学习隐私保护方案[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 506-517. |
| [13] | 任志强, 陈学斌. 基于历史模型更新的自适应防御机制FedAud[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 490-496. |
| [14] | 朱亮, 慕京哲, 左洪强, 谷晶中, 朱付保. 基于联邦图神经网络的位置隐私保护推荐方案[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 136-143. |
| [15] | 晏燕, 钱星颖, 闫鹏斌, 杨杰. 位置大数据的联邦学习统计预测与差分隐私保护方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 127-135. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||