


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (1): 10-20.DOI: 10.11772/j.issn.1001-9081.2025010115
张珂嘉1, 方志军1,2( ), 周南润1, 史志才3
), 周南润1, 史志才3
收稿日期:2025-02-07
修回日期:2025-03-14
接受日期:2025-03-19
发布日期:2026-01-10
出版日期:2026-01-10
通讯作者:
方志军
作者简介:张珂嘉(2001—),男,河南新乡人,硕士研究生,主要研究方向:联邦学习基金资助:
Kejia ZHANG1, Zhijun FANG1,2(), Nanrun ZHOU1, Zhicai SHI3
Received:2025-02-07
Revised:2025-03-14
Accepted:2025-03-19
Online:2026-01-10
Published:2026-01-10
Contact:
Zhijun FANG
About author:ZHANG Kejia, born in 2001, M. S. candidate. His research interests include federated learning.Supported by:摘要:
联邦学习(FL)是一种分布式机器学习方法,即利用分布式数据在训练模型的同时保护数据隐私。然而,它在高度异构的数据分布情况时表现不佳。个性化联邦学习(PFL)通过为每个客户端提供个性化模型来解决这一问题。然而,以往的PFL算法主要侧重于客户端本地模型的优化,忽略了服务器端全局模型的优化,导致服务器计算资源没有得到充分利用。针对上述局限性,提出基于模型预分配(PA)与自蒸馏(SD)的PFL方法FedPASD。FedPASD从服务器端和客户端2方面入手:在服务器端,对下一轮客户端模型有针对性地预先分配,这样不仅能提高模型的个性化性能,还能有效利用服务器的计算能力;在客户端,经过分层训练,并通过模型自蒸馏微调使模型更好地适应本地数据分布的特点。在3个数据集CIFAR-10、Fashion-MNIST和CIFAR-100上,将FedPASD与FedCP (Federated Conditional Policy)、FedPAC (Personalization with feature Alignment and classifier Collaboration)和FedALA (Federated learning with Adaptive Local Aggregation)等作为基准的典型算法进行对比实验的结果表明:FedPASD在不同异构设置下的测试准确率都高于基准算法。具体而言,FedPASD在CIFAR-100数据集上,客户端数量为50,参与率为50%的实验设置中,测试准确率较传统FL算法提升了29.05~29.22个百分点,较PFL算法提升了1.11~20.99个百分点;在CIFAR-10数据集上最高可达88.54%测试准确率。
中图分类号:
张珂嘉, 方志军, 周南润, 史志才. 基于模型预分配与自蒸馏的个性化联邦学习方法[J]. 计算机应用, 2026, 46(1): 10-20.
Kejia ZHANG, Zhijun FANG, Nanrun ZHOU, Zhicai SHI. Personalized federated learning method based on model pre-assignment and self-distillation[J]. Journal of Computer Applications, 2026, 46(1): 10-20.
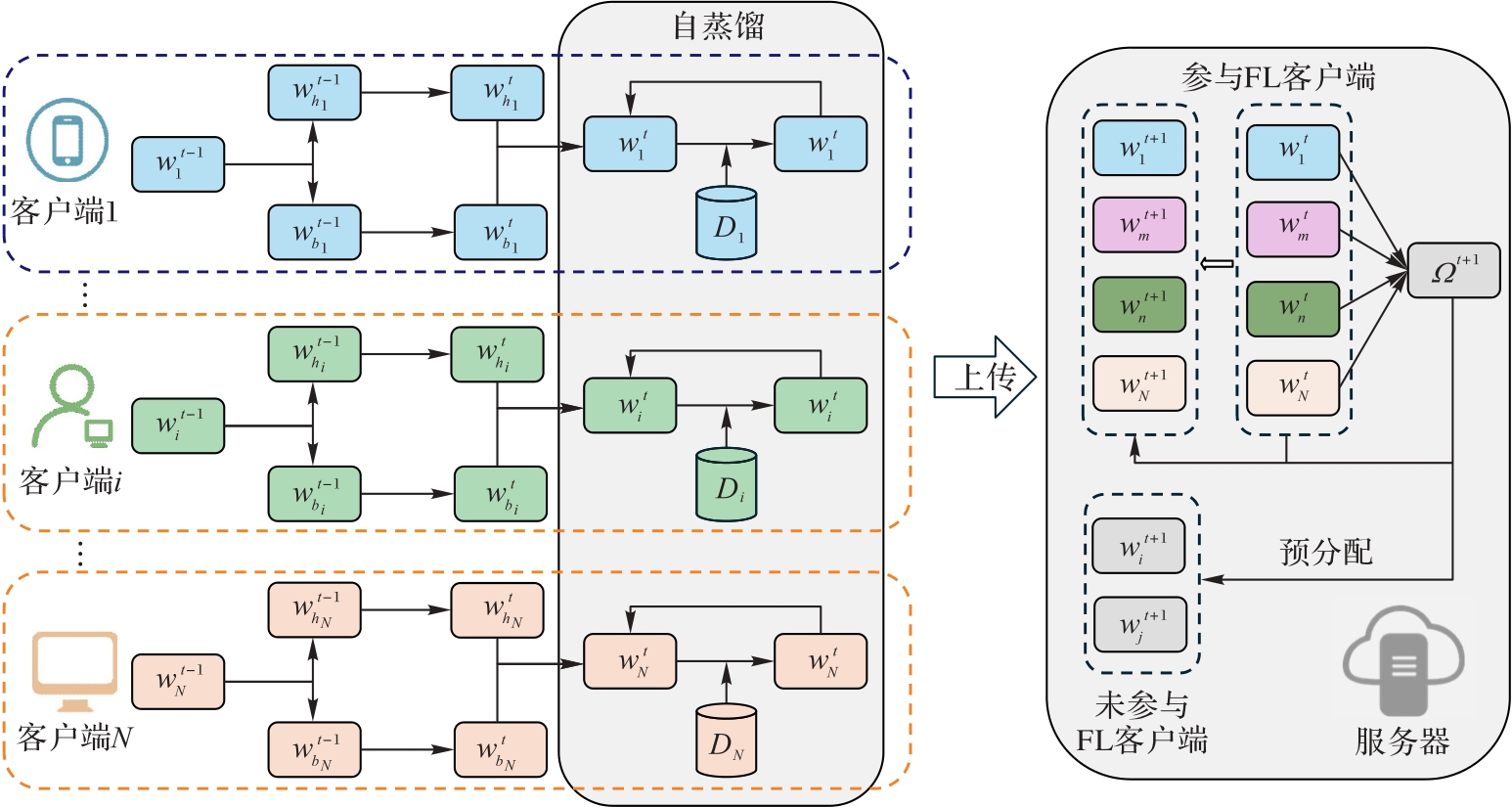
图1 FedPASD整体架构
Fig. 1 Overall architecture of FedPASD
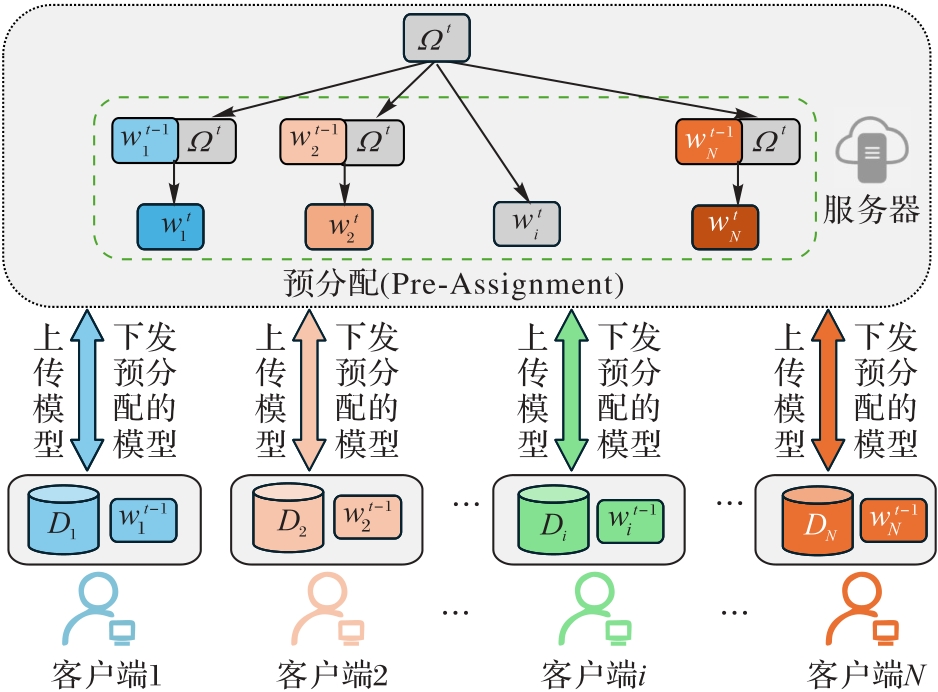
图2 服务器端的模型预分配架构
Fig. 2 Server-side pre-assignment architecture of models
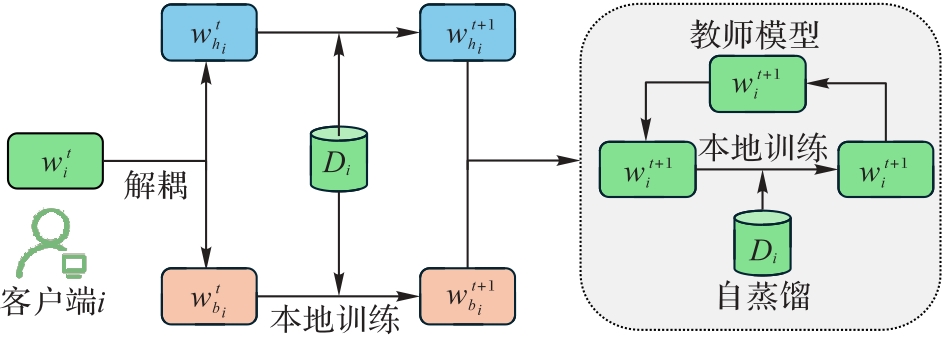
图3 客户端模型的本地训练流程
Fig. 3 Local training process of client model
| 数据集 | 任务 | 样本数 | 图片大小 | 类别数 |
|---|---|---|---|---|
| CIFAR-10 | 图像分类 | 60 000 | 32 | 10 |
| Fashion-MNIST | 图像分类 | 70 000 | 28 | 10 |
| CIFAR-100 | 图像分类 | 60 000 | 32 | 100 |
表1 数据集信息
Tab. 1 Dataset information
| 数据集 | 任务 | 样本数 | 图片大小 | 类别数 |
|---|---|---|---|---|
| CIFAR-10 | 图像分类 | 60 000 | 32 | 10 |
| Fashion-MNIST | 图像分类 | 70 000 | 28 | 10 |
| CIFAR-100 | 图像分类 | 60 000 | 32 | 100 |

图4 CIFAR-10数据集上各客户端数据样本的分布情况
Fig. 4 Distribution of data samples across clients on CIFAR-10 dataset
| 算法 | CIFAR-10 | Fashion-MNIST | CIFAR-100 | |||
|---|---|---|---|---|---|---|
| 20clients | 50clients | 20clients | 50clients | 20clients | 50clients | |
| FedAvg[ | 39.34 | 38.22 | 78.80 | 75.46 | 20.47 | 12.40 |
| FedProx[ | 39.16 | 40.14 | 78.98 | 75.07 | 20.35 | 12.56 |
| FedLC[ | 39.14 | 40.03 | 79.00 | 75.89 | 20.34 | 12.39 |
| FedBN[ | 39.17 | 38.63 | 78.79 | 75.91 | 20.45 | 12.41 |
| FedCP[ | 87.76 | 83.58 | 96.32 | 95.35 | 46.68 | 39.44 |
| FedFomo[ | 87.52 | 81.60 | 96.49 | 94.81 | 38.09 | 35.69 |
| FedProto[ | 86.04 | 80.39 | 96.20 | 93.78 | 45.52 | 27.62 |
| FedPAC[ | 84.03 | 81.83 | 95.66 | 94.50 | 48.00 | 39.22 |
| FedALA[ | 88.14 | 83.96 | 96.34 | 95.46 | 45.60 | 37.92 |
| FedGH[ | 88.00 | 83.84 | 96.49 | 95.56 | 45.96 | 40.50 |
| FedAS[ | 85.84 | 81.26 | 96.61 | 95.64 | 24.51 | 20.62 |
| FedPASD | 88.54 | 84.30 | 96.73 | 95.55 | 50.42 | 41.61 |
表2 不同客户端设置下不同算法在3个数据集上的测试准确率比较 ( %)
Tab. 2 Test accuracy comparison of different algorithms on three datasets under different client settings
| 算法 | CIFAR-10 | Fashion-MNIST | CIFAR-100 | |||
|---|---|---|---|---|---|---|
| 20clients | 50clients | 20clients | 50clients | 20clients | 50clients | |
| FedAvg[ | 39.34 | 38.22 | 78.80 | 75.46 | 20.47 | 12.40 |
| FedProx[ | 39.16 | 40.14 | 78.98 | 75.07 | 20.35 | 12.56 |
| FedLC[ | 39.14 | 40.03 | 79.00 | 75.89 | 20.34 | 12.39 |
| FedBN[ | 39.17 | 38.63 | 78.79 | 75.91 | 20.45 | 12.41 |
| FedCP[ | 87.76 | 83.58 | 96.32 | 95.35 | 46.68 | 39.44 |
| FedFomo[ | 87.52 | 81.60 | 96.49 | 94.81 | 38.09 | 35.69 |
| FedProto[ | 86.04 | 80.39 | 96.20 | 93.78 | 45.52 | 27.62 |
| FedPAC[ | 84.03 | 81.83 | 95.66 | 94.50 | 48.00 | 39.22 |
| FedALA[ | 88.14 | 83.96 | 96.34 | 95.46 | 45.60 | 37.92 |
| FedGH[ | 88.00 | 83.84 | 96.49 | 95.56 | 45.96 | 40.50 |
| FedAS[ | 85.84 | 81.26 | 96.61 | 95.64 | 24.51 | 20.62 |
| FedPASD | 88.54 | 84.30 | 96.73 | 95.55 | 50.42 | 41.61 |

图5 各算法在不同客户端设置下的收敛曲线
Fig. 5 Convergence curves of each algorithm under different client settings
| 算法 | CIFAR-10 | Fashion-MNIST | CIFAR-100 | |||
|---|---|---|---|---|---|---|
| 轮次 | 提速倍数 | 轮次 | 提速倍数 | 轮次 | 提速倍数 | |
| FedProto[ | 200 | 1.00 | 200 | 1.00 | 200 | 1.00 |
| FedFomo[ | 54 | 3.70 | 158 | 1.27 | — | — |
| FedPAC[ | — | — | — | — | 160 | 1.25 |
| FedCP[ | 77 | 2.60 | 182 | 1.10 | 181 | 1.10 |
| FedALA[ | 63 | 3.17 | 185 | 1.09 | 200 | 1.00 |
| FedGH[ | 74 | 2.70 | 156 | 1.60 | 194 | 1.03 |
| FedAS[ | 120 | 1.67 | 105 | 1.90 | — | — |
| FedPASD | 48 | 4.17 | 135 | 1.48 | 136 | 1.47 |
表3 不同算法达到目标准确率所需的通信轮次
Tab. 3 Communication rounds required for different algorithms to achieve target accuracy
| 算法 | CIFAR-10 | Fashion-MNIST | CIFAR-100 | |||
|---|---|---|---|---|---|---|
| 轮次 | 提速倍数 | 轮次 | 提速倍数 | 轮次 | 提速倍数 | |
| FedProto[ | 200 | 1.00 | 200 | 1.00 | 200 | 1.00 |
| FedFomo[ | 54 | 3.70 | 158 | 1.27 | — | — |
| FedPAC[ | — | — | — | — | 160 | 1.25 |
| FedCP[ | 77 | 2.60 | 182 | 1.10 | 181 | 1.10 |
| FedALA[ | 63 | 3.17 | 185 | 1.09 | 200 | 1.00 |
| FedGH[ | 74 | 2.70 | 156 | 1.60 | 194 | 1.03 |
| FedAS[ | 120 | 1.67 | 105 | 1.90 | — | — |
| FedPASD | 48 | 4.17 | 135 | 1.48 | 136 | 1.47 |
| 算法 | CIFAR-10 | Fashion-MNIST | CIFAR-100 |
|---|---|---|---|
| FedAvg[ | 0.800 3 | 0.943 3 | 0.806 0 |
| FedProx[ | 0.798 5 | 0.943 6 | 0.805 7 |
| FedLC[ | 0.798 1 | 0.943 0 | 0.806 3 |
| FedBN[ | 0.798 9 | 0.943 9 | 0.805 6 |
| FedCP[ | 0.985 3 | 0.9980 | 0.964 7 |
| FedFomo[ | 0.977 7 | 0.994 9 | 0.949 5 |
| FedProto[ | 0.984 5 | 0.997 6 | 0.965 2 |
| FedPAC[ | 0.944 3 | 0.990 5 | 0.961 9 |
| FedALA[ | 0.892 1 | 0.975 5 | 0.952 1 |
| FedGH[ | 0.968 5 | 0.971 5 | 0.908 2 |
| FedAS[ | 0.980 0 | 0.993 4 | 0.938 1 |
| FedPASD | 0.9856 | 0.996 5 | 0.9724 |
表4 不同算法在默认实验设置下的AUC指标
Tab. 4 AUC metrics of different algorithms under default experimental setting
| 算法 | CIFAR-10 | Fashion-MNIST | CIFAR-100 |
|---|---|---|---|
| FedAvg[ | 0.800 3 | 0.943 3 | 0.806 0 |
| FedProx[ | 0.798 5 | 0.943 6 | 0.805 7 |
| FedLC[ | 0.798 1 | 0.943 0 | 0.806 3 |
| FedBN[ | 0.798 9 | 0.943 9 | 0.805 6 |
| FedCP[ | 0.985 3 | 0.9980 | 0.964 7 |
| FedFomo[ | 0.977 7 | 0.994 9 | 0.949 5 |
| FedProto[ | 0.984 5 | 0.997 6 | 0.965 2 |
| FedPAC[ | 0.944 3 | 0.990 5 | 0.961 9 |
| FedALA[ | 0.892 1 | 0.975 5 | 0.952 1 |
| FedGH[ | 0.968 5 | 0.971 5 | 0.908 2 |
| FedAS[ | 0.980 0 | 0.993 4 | 0.938 1 |
| FedPASD | 0.9856 | 0.996 5 | 0.9724 |
| 算法 | CIFAR-10 | Fashion-MNIST | CIFAR-100 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FedAvg[ | 39.34 | 47.31 | 52.07 | 52.92 | 78.80 | 83.37 | 86.00 | 85.76 | 20.47 | 22.27 | 22.89 | 23.05 |
| FedProx[ | 39.16 | 47.64 | 52.39 | 52.59 | 78.98 | 83.67 | 86.06 | 85.70 | 20.35 | 22.06 | 22.88 | 22.97 |
| FedLC[ | 39.14 | 47.53 | 52.16 | 52.71 | 79.00 | 83.54 | 85.80 | 85.80 | 20.34 | 22.08 | 22.86 | 22.93 |
| FedBN[ | 39.17 | 47.64 | 52.38 | 52.56 | 78.79 | 83.44 | 85.86 | 85.85 | 20.45 | 22.07 | 22.84 | 22.86 |
| FedCP[ | 87.76 | 76.46 | 70.59 | 65.76 | 96.32 | 91.77 | 90.02 | 89.02 | 46.68 | 36.15 | 30.23 | 25.68 |
| FedFomo[ | 87.52 | 76.22 | 67.04 | 61.69 | 96.49 | 91.44 | 88.65 | 87.06 | 38.09 | 29.14 | 23.23 | 19.80 |
| FedProto[ | 86.04 | 73.77 | 65.17 | 60.69 | 96.20 | 89.77 | 86.30 | 84.91 | 45.52 | 32.92 | 27.59 | 23.69 |
| FedPAC[ | 84.03 | 77.04 | 71.75 | 67.12 | 95.66 | 91.83 | 90.28 | 89.40 | 48.00 | 37.01 | 32.23 | 28.66 |
| FedALA[ | 88.14 | 77.45 | 71.87 | 67.41 | 96.34 | 92.15 | 90.46 | 89.46 | 45.60 | 37.77 | 33.80 | 29.50 |
| FedGH[ | 88.00 | 76.52 | 71.16 | 66.92 | 96.49 | 92.12 | 90.53 | 89.44 | 45.96 | 36.19 | 31.85 | 28.01 |
| FedAS[ | 85.84 | 70.01 | 59.66 | 52.92 | 96.61 | 91.87 | 89.21 | 87.71 | 24.51 | 17.16 | 11.92 | 6.83 |
| FedPASD | 88.54 | 77.96 | 72.38 | 67.60 | 96.73 | 92.36 | 90.50 | 89.55 | 50.42 | 39.26 | 33.86 | 29.30 |
表5 不同数据异构程度下各算法在3个数据集上的测试准确率比较 ( %)
Tab. 5 Test accuracy comparison of each algorithm on three datasets under different degrees of data heterogeneity
| 算法 | CIFAR-10 | Fashion-MNIST | CIFAR-100 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FedAvg[ | 39.34 | 47.31 | 52.07 | 52.92 | 78.80 | 83.37 | 86.00 | 85.76 | 20.47 | 22.27 | 22.89 | 23.05 |
| FedProx[ | 39.16 | 47.64 | 52.39 | 52.59 | 78.98 | 83.67 | 86.06 | 85.70 | 20.35 | 22.06 | 22.88 | 22.97 |
| FedLC[ | 39.14 | 47.53 | 52.16 | 52.71 | 79.00 | 83.54 | 85.80 | 85.80 | 20.34 | 22.08 | 22.86 | 22.93 |
| FedBN[ | 39.17 | 47.64 | 52.38 | 52.56 | 78.79 | 83.44 | 85.86 | 85.85 | 20.45 | 22.07 | 22.84 | 22.86 |
| FedCP[ | 87.76 | 76.46 | 70.59 | 65.76 | 96.32 | 91.77 | 90.02 | 89.02 | 46.68 | 36.15 | 30.23 | 25.68 |
| FedFomo[ | 87.52 | 76.22 | 67.04 | 61.69 | 96.49 | 91.44 | 88.65 | 87.06 | 38.09 | 29.14 | 23.23 | 19.80 |
| FedProto[ | 86.04 | 73.77 | 65.17 | 60.69 | 96.20 | 89.77 | 86.30 | 84.91 | 45.52 | 32.92 | 27.59 | 23.69 |
| FedPAC[ | 84.03 | 77.04 | 71.75 | 67.12 | 95.66 | 91.83 | 90.28 | 89.40 | 48.00 | 37.01 | 32.23 | 28.66 |
| FedALA[ | 88.14 | 77.45 | 71.87 | 67.41 | 96.34 | 92.15 | 90.46 | 89.46 | 45.60 | 37.77 | 33.80 | 29.50 |
| FedGH[ | 88.00 | 76.52 | 71.16 | 66.92 | 96.49 | 92.12 | 90.53 | 89.44 | 45.96 | 36.19 | 31.85 | 28.01 |
| FedAS[ | 85.84 | 70.01 | 59.66 | 52.92 | 96.61 | 91.87 | 89.21 | 87.71 | 24.51 | 17.16 | 11.92 | 6.83 |
| FedPASD | 88.54 | 77.96 | 72.38 | 67.60 | 96.73 | 92.36 | 90.50 | 89.55 | 50.42 | 39.26 | 33.86 | 29.30 |
| 算法 | CIFAR-10 | CIFAR-100 | ||||
|---|---|---|---|---|---|---|
| FedAvg[ | 38.03 | 38.22 | 40.34 | 11.90 | 12.40 | 12.71 |
| FedProx[ | 38.01 | 40.14 | 40.21 | 12.11 | 12.56 | 12.87 |
| FedLC[ | 39.17 | 40.03 | 40.01 | 12.15 | 12.39 | 12.75 |
| FedBN[ | 37.42 | 38.63 | 39.74 | 12.15 | 12.41 | 12.67 |
| FedCP[ | 83.26 | 83.58 | 83.90 | 38.36 | 39.44 | 40.27 |
| FedFomo[ | 80.25 | 81.60 | 82.22 | 32.76 | 35.69 | 37.14 |
| FedProto[ | 78.91 | 80.39 | 81.13 | 18.83 | 27.62 | 37.20 |
| FedPAC[ | 82.94 | 81.83 | 79.22 | 38.31 | 39.22 | 40.01 |
| FedALA[ | 83.15 | 83.96 | 83.93 | 37.97 | 37.92 | 37.10 |
| FedGH[ | 83.74 | 83.84 | 83.96 | 39.82 | 40.50 | 40.69 |
| FedAS[ | 81.67 | 81.26 | 80.70 | 20.14 | 20.62 | 23.20 |
| FedPASD | 83.72 | 84.30 | 84.64 | 40.05 | 41.61 | 43.51 |
表6 不同客户端参与率下不同算法在CIFAR-10和CIFAR-100数据集上的测试准确率对比 ( %)
Tab. 6 Test accuracy comparison of different algorithms on CIFAR-10 and CIFAR-100 datasets under different client participation rates
| 算法 | CIFAR-10 | CIFAR-100 | ||||
|---|---|---|---|---|---|---|
| FedAvg[ | 38.03 | 38.22 | 40.34 | 11.90 | 12.40 | 12.71 |
| FedProx[ | 38.01 | 40.14 | 40.21 | 12.11 | 12.56 | 12.87 |
| FedLC[ | 39.17 | 40.03 | 40.01 | 12.15 | 12.39 | 12.75 |
| FedBN[ | 37.42 | 38.63 | 39.74 | 12.15 | 12.41 | 12.67 |
| FedCP[ | 83.26 | 83.58 | 83.90 | 38.36 | 39.44 | 40.27 |
| FedFomo[ | 80.25 | 81.60 | 82.22 | 32.76 | 35.69 | 37.14 |
| FedProto[ | 78.91 | 80.39 | 81.13 | 18.83 | 27.62 | 37.20 |
| FedPAC[ | 82.94 | 81.83 | 79.22 | 38.31 | 39.22 | 40.01 |
| FedALA[ | 83.15 | 83.96 | 83.93 | 37.97 | 37.92 | 37.10 |
| FedGH[ | 83.74 | 83.84 | 83.96 | 39.82 | 40.50 | 40.69 |
| FedAS[ | 81.67 | 81.26 | 80.70 | 20.14 | 20.62 | 23.20 |
| FedPASD | 83.72 | 84.30 | 84.64 | 40.05 | 41.61 | 43.51 |
| 测试准确率/% | |||
|---|---|---|---|
| CIFAR-10 | Fashion-MNIST | CIFAR-100 | |
| 0.0 | 88.19 | 96.60 | 50.23 |
| 0.2 | 88.29 | 96.61 | 50.27 |
| 0.5 | 88.54 | 96.73 | 50.42 |
| 0.8 | 88.62 | 96.64 | 50.39 |
表7 超参数μ的不同取值对算法测试准确率的影响
Tab. 7 Impact of different hyperparameter μ value on algorithm test accuracy
| 测试准确率/% | |||
|---|---|---|---|
| CIFAR-10 | Fashion-MNIST | CIFAR-100 | |
| 0.0 | 88.19 | 96.60 | 50.23 |
| 0.2 | 88.29 | 96.61 | 50.27 |
| 0.5 | 88.54 | 96.73 | 50.42 |
| 0.8 | 88.62 | 96.64 | 50.39 |
| 测试准确率/% | |||
|---|---|---|---|
| CIFAR-10 | Fashion-MNIST | CIFAR-100 | |
| 2 | 88.54 | 96.73 | 50.42 |
| 5 | 88.32 | 96.68 | 50.67 |
| 8 | 88.40 | 96.65 | 50.49 |
| 10 | 88.22 | 96.70 | 50.38 |
表8 超参数τ的不同取值对算法测试准确率的影响
Tab. 8 Impact of different hyperparameter τ value on algorithm test accuracy
| 测试准确率/% | |||
|---|---|---|---|
| CIFAR-10 | Fashion-MNIST | CIFAR-100 | |
| 2 | 88.54 | 96.73 | 50.42 |
| 5 | 88.32 | 96.68 | 50.67 |
| 8 | 88.40 | 96.65 | 50.49 |
| 10 | 88.22 | 96.70 | 50.38 |
| 模块 | 测试准确率/% | ||
|---|---|---|---|
| CIFAR-10 | Fashion-MNIST | CIFAR-100 | |
| None | 85.77 | 95.66 | 45.52 |
| SD | 88.24 | 96.64 | 50.10 |
| PA | 86.28 | 96.02 | 48.49 |
| Both | 88.54 | 96.73 | 50.42 |
表9 不同模块对算法测试准确率的影响
Tab. 9 Impact of different modules on algorithm test accuracy
| 模块 | 测试准确率/% | ||
|---|---|---|---|
| CIFAR-10 | Fashion-MNIST | CIFAR-100 | |
| None | 85.77 | 95.66 | 45.52 |
| SD | 88.24 | 96.64 | 50.10 |
| PA | 86.28 | 96.02 | 48.49 |
| Both | 88.54 | 96.73 | 50.42 |
| [1] | McMAHAN B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data [C]// Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2017: 1273-1282. |
| [2] | YAN Z, WICAKSANA J, WANG Z, et al. Variation-aware federated learning with multi-source decentralized medical image data [J]. IEEE Journal of Biomedical and Health Informatics, 2021, 25(7): 2615-2628. |
| [3] | CETINKAYA A E, AKIN M, SAGIROGLU S. Improving performance of federated learning based medical image analysis in non-IID settings using image augmentation [C]// Proceedings of the 2021 International Conference on Information Security and Cryptology. Piscataway: IEEE, 2021: 69-74. |
| [4] | ZHENG W, YAN L, GOU C, et al. Federated meta-learning for fraudulent credit card detection [C]// Proceedings of the 29th International Joint Conferences on Artificial Intelligence. California: ijcai.org, 2020: 4654-4660. |
| [5] | LIANG X, LIU Y, CHEN T, et al. Federated transfer reinforcement learning for autonomous driving [M]// RAZAVI-FAR R, WANG B, TAYLOR M E, et al. Federated and transfer learning, ALO 27. Cham: Springer, 2023: 357-371. |
| [6] | REISIZADEH A, MOKHTARI A, HASSANI H, et al. FedPAQ: a communication-efficient federated learning method with periodic averaging and quantization [C]// Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2020: 2021-2031. |
| [7] | 李少波,杨磊,李传江,等.联邦学习概述:技术,应用及未来[J].计算机集成制造系统, 2022, 28(7): 2119-2138. |
| LI S B, YANG L, LI C J, et al. Overview of federated learning: technology, applications and future [J]. Computer Integrated Manufacturing Systems, 2022, 28(7): 2119-2138. | |
| [8] | WANG J, YANG X, CUI S, et al. Towards personalized federated learning via heterogeneous model reassembly [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 29515-29531. |
| [9] | LI X, JIANG M, ZHANG X, et al. FedBN: federated learning on non-iid features via local batch normalization [EB/OL]. [2024-06-26]. . |
| [10] | JIN H, BAI D, YAO D, et al. Personalized edge intelligence via federated self-knowledge distillation [J]. IEEE Transactions on Parallel and Distributed Systems, 2023, 34(2): 567-580. |
| [11] | KAIROUZ P, McMAHAN H B, AVENT B, et al. Advances and open problems in federated learning [J]. Foundations and Trends in Machine Learning, 2021, 14(1/2): 1-210. |
| [12] | XU J, TONG X, HUANG S L. Personalized federated learning with feature alignment and classifier collaboration [EB/OL]. [2024-11-02]. . |
| [13] | ZHU H, XU J, LIU S, et al. Federated learning on non-IID data: a survey [J]. Neurocomputing, 2021, 465: 371-390. |
| [14] | LI T, SAHU A K, ZAHEER M, et al. Federated optimization in heterogeneous networks [EB/OL]. [2024-11-02]. . |
| [15] | KARIMIREDDY S P, KALE S, MOHRI M, et al. SCAFFOLD: stochastic controlled averaging for federated learning [C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 5132-5143. |
| [16] | ZHANG J, LI Z, LI B, et al. Federated learning with label distribution skew via logits calibration [C]// Proceedings of the 39th International Conference on Machine Learning. New York: JMLR.org, 2022: 26311-26329. |
| [17] | LI Q, HE B, SONG D. Model-contrastive federated learning [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10708-10717. |
| [18] | LIU Z, WU F, WANG Y, et al. FedCL: federated contrastive learning for multi-center medical image classification [J]. Pattern Recognition, 2023, 143: No.109739. |
| [19] | TAN A Z, YU H, CUI L, et al. Towards personalized federated learning [J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(12): 9587-9603. |
| [20] | SABAH F, CHEN Y, YANG Z, et al. Model optimization techniques in personalized federated learning: a survey [J]. Expert Systems with Applications, 2024, 243: No.122874. |
| [21] | FALLAH A, MOKHTRI A, OZDAGLAR A. Personalized federated learning with theoretical guarantees: a model-agnostic meta-learning approach [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 3557-3568. |
| [22] | FINN C, ABBEEL P, LEVINE S. Model-agnostic meta-learning for fast adaptation of deep networks [C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1126-1135. |
| [23] | LIN T, KONG L, STICH S U, et al. Ensemble distillation for robust model fusion in federated learning [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 2351-2363. |
| [24] | LI T, HU S, BEIRAMI A, et al. Ditto: fair and robust federated learning through personalization [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 6357-6368. |
| [25] | DINH C T, TRAN N H, NGUYEN T D. Personalized federated learning with Moreau envelopes [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 21394-21405. |
| [26] | COLLINS L, HASSANI H, MOKHTARI A, et al. Exploiting shared representations for personalized federated learning [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 2089-2099. |
| [27] | ARIVAZHAGAN M G, AGGARWAL V, SINGH A K, et al. Federated learning with personalization layers [EB/OL]. [2024-10-03]. . |
| [28] | OH J, KIM S, YUN S Y. FedBABU: towards enhanced representation for federated image classification [EB/OL]. [2024-11-02]. . |
| [29] | ZHANG J, HUA Y, WANG H, et al. FedCP: separating feature information for personalized federated learning via conditional policy [C]// Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2023: 3249-3261. |
| [30] | HUANG Y, CHU L, ZHOU Z, et al. Personalized cross-silo federated learning on non-IID data [C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 7865-7873. |
| [31] | ZHANG M, SAPRA K, FIDLER S, et al. Personalized federated learning with first order model optimization [EB/OL]. [2024-11-02]. . |
| [32] | LIU X, LI H, XU G, et al. Adaptive privacy-preserving federated learning [J]. Peer-to-Peer Networking and Applications, 2020, 13(6): 2356-2366. |
| [33] | TAN Y, LONG G, LIU L, et al. FedProto: federated prototype learning across heterogeneous clients [C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 8432-8440. |
| [34] | LI H, CAI Z, WANG J, et al. FedTP: federated learning by transformer personalization [J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(10): 13426-13440. |
| [35] | ZHANG J, HUA Y, WANG H, et al. FedALA: adaptive local aggregation for personalized federated learning [C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 11237-11244. |
| [36] | LUO J, WU S. Adapt to adaptation: learning personalization for cross-silo federated learning [C]// Proceedings of the 31st International Joint Conferences on Artificial Intelligence. California: ijcai.org, 2022: 2166-2173. |
| [37] | KRIZHEVSKY A. Learning multiple layers of features from tiny images [EB/OL]. [2024-11-02]. . |
| [38] | XIAO H, RASUL K, VOLLGRAF R. Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms [EB/OL]. [2024-11-02]. . |
| [39] | YI L, WANG G, LIU X, et al. FedGH: heterogeneous federated learning with generalized global header [C]// Proceedings of the 31st ACM International Conference on Multimedia. New York: ACM, 2023: 8686-8696. |
| [40] | YANG X, HUANG W, YE M. FedAS: bridging inconsistency in personalized federated learning [C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 11986-11995. |
| [41] | PASZKE A, GROSS S, MASSA F, et al. PyTorch: an imperative style, high-performance deep learning library [C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 8026-8037. |
| [1] | 菅银龙, 陈学斌, 景忠瑞, 钟琪, 张镇博. 联邦学习中基于条件生成对抗网络的数据增强方案[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 21-32. |
| [2] | 俞浩, 范菁, 孙伊航, 金亚东, 郗恩康, 董华. 边缘异构下的联邦分割学习优化方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 33-42. |
| [3] | 俞浩, 范菁, 孙伊航, 董华, 郗恩康. 联邦学习统计异质性综述[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2737-2746. |
| [4] | 苏锦涛, 葛丽娜, 肖礼广, 邹经, 王哲. 联邦学习中针对后门攻击的检测与防御方案[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2399-2408. |
| [5] | 葛丽娜, 王明禹, 田蕾. 联邦学习的高效性研究综述[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2387-2398. |
| [6] | 张宏扬, 张淑芬, 谷铮. 面向个性化与公平性的联邦学习算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2123-2131. |
| [7] | 张一鸣, 曹腾飞. 基于本地漂移和多样性算力的联邦学习优化算法[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1447-1454. |
| [8] | 范亚州, 李卓. 能耗约束下分层联邦学习模型质量优化的节点协作机制[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1589-1594. |
| [9] | 陈庆礼, 郭渊博, 方晨. 面向数据异构的聚类联邦学习算法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1086-1094. |
| [10] | 项钰斐, 倪郑威. 基于演化博弈的分层联邦学习边缘联合动态分析[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1077-1085. |
| [11] | 曾辉, 熊诗雨, 狄永正, 史红周. 基于剪枝的大模型联邦参数高效微调技术[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 715-724. |
| [12] | 林海力, 李京. 基于工作证明的联邦学习懒惰客户端识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 856-863. |
| [13] | 徐超, 张淑芬, 陈海田, 彭璐璐, 张帅华. 基于自适应差分隐私与客户选择优化的联邦学习方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 482-489. |
| [14] | 王心妍, 杜嘉程, 钟李红, 徐旺旺, 刘伯宇, 佘维. 融合电力数据的纵向联邦学习企业排污预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 518-525. |
| [15] | 陈海田, 陈学斌, 马锐奎, 张帅华. 面向遥感数据的基于本地差分隐私的联邦学习隐私保护方案[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 506-517. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||