


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (2): 580-586.DOI: 10.11772/j.issn.1001-9081.2025020241
• 多媒体计算与计算机仿真 • 上一篇
樊跃波, 陈明轩( ), 汤显, 高永彬, 李文超
), 汤显, 高永彬, 李文超
收稿日期:2025-03-11
修回日期:2025-05-10
接受日期:2025-05-15
发布日期:2025-06-10
出版日期:2026-02-10
通讯作者:
陈明轩
作者简介:樊跃波(2000—),男,河南长垣人,硕士研究生,主要研究方向:计算机视觉、机器学习
Yuebo FAN, Mingxuan CHEN(), Xian TANG, Yongbin GAO, Wenchao LI
Received:2025-03-11
Revised:2025-05-10
Accepted:2025-05-15
Online:2025-06-10
Published:2026-02-10
Contact:
Mingxuan CHEN
About author:FAN Yuebo, born in 2000, M. S. candidate. His research interests include computer vision, machine learning.摘要:
人物交互(HOI)检测任务的目标是检测图像中所有人与物体之间的交互关系。目前的研究大多采用编码器-解码器结构进行端到端的训练,依赖绝对位置编码(APE),且在复杂的多对象交互场景中表现欠佳。针对现有方法依赖APE,难以有效捕捉人与物体之间的相对空间关系,以及在复杂多对象交互场景中局部与全局信息整合不足的问题,提出一种结合跨维度交互特征提取与频域特征融合的HOI检测模型。首先,改进传统的Transformer编码器,额外引入一种相对位置编码(RPE),并通过融合RPE与APE,使模型能够对人与物体之间的相对关系进行建模;其次,引入一种新的特征提取模块加强图像信息的整合,即通过跨维度交互捕捉图像中通道、空间和特征维度的交互特征,提升信息表达能力,同时利用离散余弦变换(DCT)提取频域特征,从而捕捉更丰富的局部与全局信息;最后,使用Wise-IoU损失函数提升检测精度与类别区分能力,使模型可以更灵活地处理不同类别的目标。实验在HICO-DET和V-COCO两个公开数据集上进行,结果表明,与GEN-VLKT(Guided Embedding Network Visual-Linguistic Knowledge Transfer)模型相比,所提模型在HICO-DET数据集全部种类上的平均精度均值(mAP)提升了0.95个百分点,在V-COCO数据集场景1上的AP提升了0.9个百分点。
中图分类号:
樊跃波, 陈明轩, 汤显, 高永彬, 李文超. 基于多维频域特征融合的人物交互检测[J]. 计算机应用, 2026, 46(2): 580-586.
Yuebo FAN, Mingxuan CHEN, Xian TANG, Yongbin GAO, Wenchao LI. Multi-dimensional frequency domain feature fusion for human-object interaction detection[J]. Journal of Computer Applications, 2026, 46(2): 580-586.

图1 MFNet模型的结构
Fig. 1 Structure of MFNet model
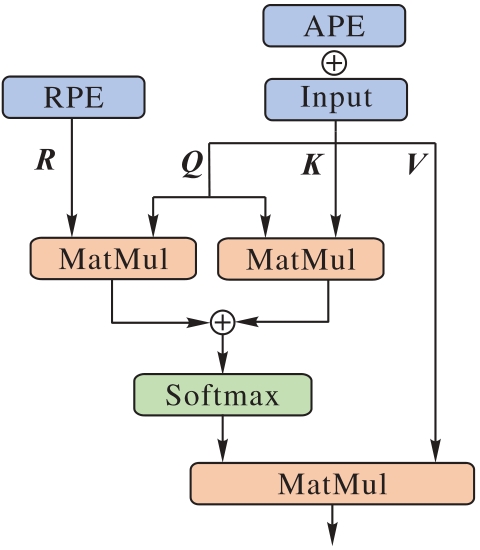
图2 HPE Self-Attention的结构
Fig. 2 Structure of HPE Self-Attention
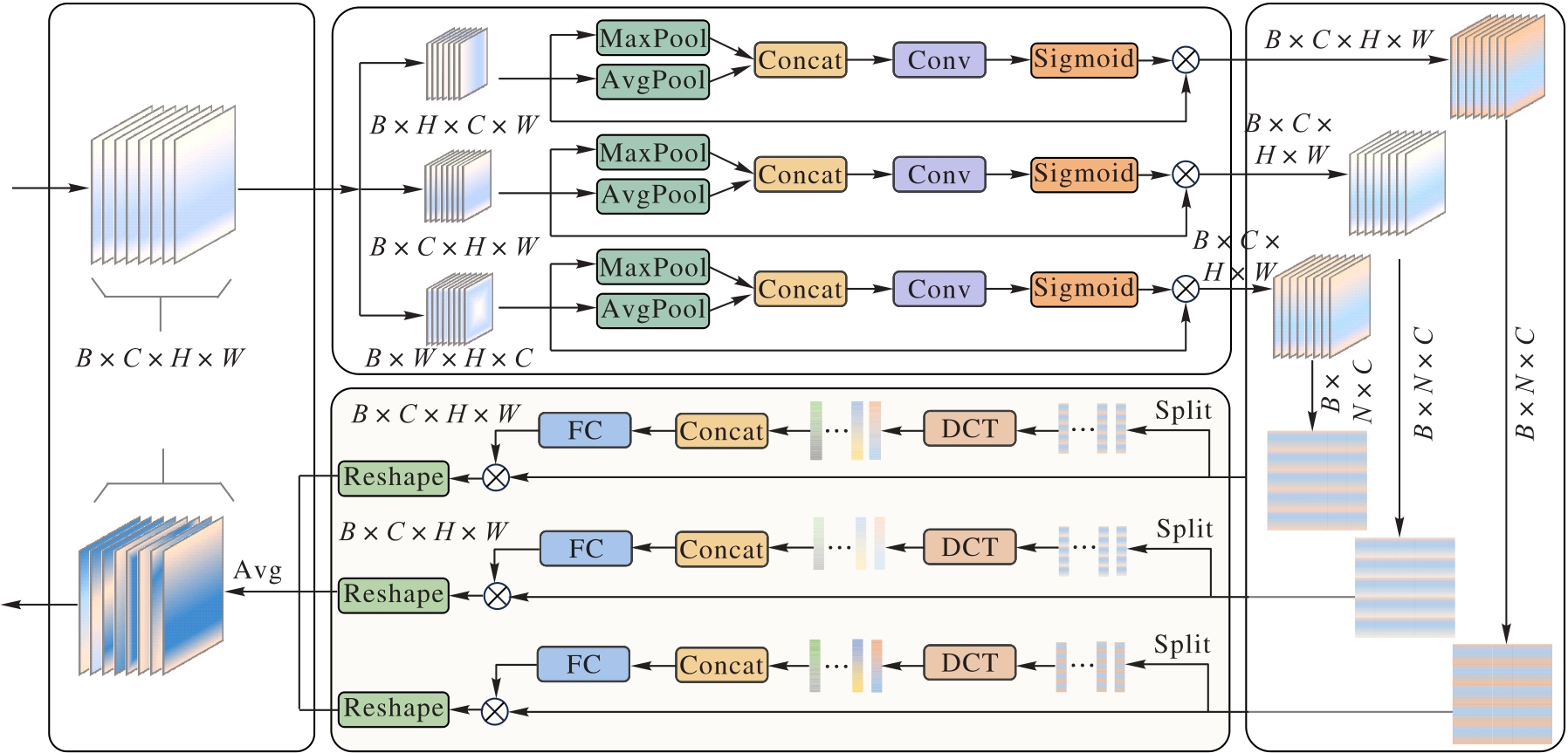
图3 MFF模块的结构
Fig. 3 Structure of MFF module
| 模型 | Backbone | mAP/% | ||
|---|---|---|---|---|
| Full | Rare | Non-rare | ||
| DRG[ | ResNet50-FPN | 19.26 | 17.74 | 19.71 |
| HOTR[ | ResNet50 | 25.10 | 17.34 | 27.42 |
| HOI-Trans[ | ResNet101 | 26.61 | 19.15 | 28.84 |
| SCG[ | ResNet50-FPN | 29.26 | 24.61 | 30.65 |
| QPIC[ | ResNet101 | 29.90 | 23.92 | 31.69 |
| MSTR[ | ResNet50 | 31.17 | 25.31 | 32.92 |
| UPT[ | ResNet50 | 31.66 | 25.94 | 33.36 |
| CDN[ | ResNet50 | 31.78 | 27.55 | 33.05 |
| CycleHOI[ | ResNet50 | 32.23 | 25.27 | 34.01 |
| GEN-VLKT[ | ResNet50 | 32.37 | 26.13 | 34.24 |
| OpenCat[ | ResNet101 | 32.68 | 28.42 | 33.75 |
| PRNet[ | ResNet101 | 32.86 | 28.03 | 34.30 |
| AFFNSNet[ | ResNet50 | 33.08 | 28.66 | 34.41 |
| MFNet | ResNet50 | 33.32 | 28.44 | 34.77 |
表1 HICO-DET测试集上的检测性能比较
Tab. 1 Comparison of detection performance on HICO-DET test set
| 模型 | Backbone | mAP/% | ||
|---|---|---|---|---|
| Full | Rare | Non-rare | ||
| DRG[ | ResNet50-FPN | 19.26 | 17.74 | 19.71 |
| HOTR[ | ResNet50 | 25.10 | 17.34 | 27.42 |
| HOI-Trans[ | ResNet101 | 26.61 | 19.15 | 28.84 |
| SCG[ | ResNet50-FPN | 29.26 | 24.61 | 30.65 |
| QPIC[ | ResNet101 | 29.90 | 23.92 | 31.69 |
| MSTR[ | ResNet50 | 31.17 | 25.31 | 32.92 |
| UPT[ | ResNet50 | 31.66 | 25.94 | 33.36 |
| CDN[ | ResNet50 | 31.78 | 27.55 | 33.05 |
| CycleHOI[ | ResNet50 | 32.23 | 25.27 | 34.01 |
| GEN-VLKT[ | ResNet50 | 32.37 | 26.13 | 34.24 |
| OpenCat[ | ResNet101 | 32.68 | 28.42 | 33.75 |
| PRNet[ | ResNet101 | 32.86 | 28.03 | 34.30 |
| AFFNSNet[ | ResNet50 | 33.08 | 28.66 | 34.41 |
| MFNet | ResNet50 | 33.32 | 28.44 | 34.77 |
| 模型 | Backbone | ||
|---|---|---|---|
| DRG[ | ResNet50-FPN | 51.0 | |
| HOI-Trans[ | ResNet101 | 52.9 | |
| SCG[ | ResNet50-FPN | 54.2 | 60.9 |
| HOTR[ | ResNet50 | 55.2 | 64.4 |
| QPIC[ | ResNet101 | 58.3 | 60.7 |
| UPT[ | ResNet50 | 59.0 | 64.5 |
| CDN[ | ResNet50 | 61.7 | 63.8 |
| OpenCat[ | ResNet101 | 61.9 | 63.2 |
| MSTR[ | ResNet50 | 62.0 | 65.2 |
| GEN-VLKT[ | ResNet50 | 62.4 | 64.5 |
| CycleHOI[ | ResNet50 | 62.4 | 64.7 |
| PRNet[ | ResNet101 | 62.9 | 64.2 |
| AFFNSNet[ | ResNet50 | 62.4 | 64.5 |
| MFNet | ResNet50 | 63.3 | 66.4 |
表2 V-COCO测试集上的检测性能比较 (%)
Tab. 2 Comparison of detection performance on V-COCO test set
| 模型 | Backbone | ||
|---|---|---|---|
| DRG[ | ResNet50-FPN | 51.0 | |
| HOI-Trans[ | ResNet101 | 52.9 | |
| SCG[ | ResNet50-FPN | 54.2 | 60.9 |
| HOTR[ | ResNet50 | 55.2 | 64.4 |
| QPIC[ | ResNet101 | 58.3 | 60.7 |
| UPT[ | ResNet50 | 59.0 | 64.5 |
| CDN[ | ResNet50 | 61.7 | 63.8 |
| OpenCat[ | ResNet101 | 61.9 | 63.2 |
| MSTR[ | ResNet50 | 62.0 | 65.2 |
| GEN-VLKT[ | ResNet50 | 62.4 | 64.5 |
| CycleHOI[ | ResNet50 | 62.4 | 64.7 |
| PRNet[ | ResNet101 | 62.9 | 64.2 |
| AFFNSNet[ | ResNet50 | 62.4 | 64.5 |
| MFNet | ResNet50 | 63.3 | 66.4 |
| 模型 | ||
|---|---|---|
| Base | 61.6 | 64.2 |
| Base+IRPE | 62.1 | 65.1 |
| Base+MFF | 63.0 | 66.0 |
| Base+WIoU | 63.3 | 66.4 |
表3 V-COCO数据集上的消融实验结果 (%)
Tab. 3 Ablation experiment results on V-COCO dataset
| 模型 | ||
|---|---|---|
| Base | 61.6 | 64.2 |
| Base+IRPE | 62.1 | 65.1 |
| Base+MFF | 63.0 | 66.0 |
| Base+WIoU | 63.3 | 66.4 |
| 模型 | mAP | ||
|---|---|---|---|
| Full | Rare | Non-rare | |
| Base | 32.37 | 26.13 | 34.24 |
| Base+IRPE | 32.68 | 26.81 | 34.42 |
| Base+MFF | 33.16 | 27.73 | 34.69 |
| Base+WIoU | 33.32 | 28.44 | 34.77 |
表4 HICO-DET数据集上的消融实验结果 (%)
Tab. 4 Ablation experiments results on HICO-DET dataset
| 模型 | mAP | ||
|---|---|---|---|
| Full | Rare | Non-rare | |
| Base | 32.37 | 26.13 | 34.24 |
| Base+IRPE | 32.68 | 26.81 | 34.42 |
| Base+MFF | 33.16 | 27.73 | 34.69 |
| Base+WIoU | 33.32 | 28.44 | 34.77 |
| 方法 | ||
|---|---|---|
| MFF(base) | 62.6 | 65.1 |
| MFF(base+rotate-W) | 62.9 | 65.8 |
| MFF(base+rotate-H) | 62.9 | 65.6 |
| MFF(full) | 63.3 | 66.4 |
表5 V-COCO数据集上的MFF分支结构设计 (%)
Tab. 5 MFF branch structure design on V-COCO dataset
| 方法 | ||
|---|---|---|
| MFF(base) | 62.6 | 65.1 |
| MFF(base+rotate-W) | 62.9 | 65.8 |
| MFF(base+rotate-H) | 62.9 | 65.6 |
| MFF(full) | 63.3 | 66.4 |

图4 可视化动作结果
Fig. 4 Visualization results of movements
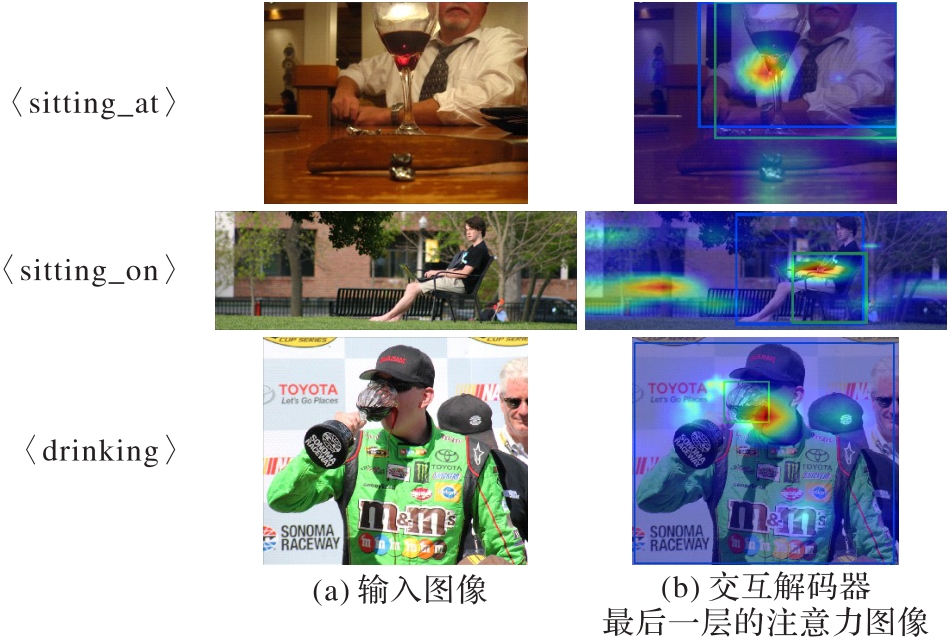
图5 可视化注意力结果
Fig. 5 Visualized attention results
| [1] | 龚勋,张志莹,刘璐,等. 人物交互检测研究进展综述[J]. 西南交通大学学报, 2022, 57(4): 693-704. |
| GONG X, ZHANG Z Y, LIU L, et al. A survey of human-object interaction detection[J]. Journal of Southwest Jiaotong University, 2022, 57(4): 693-704. | |
| [2] | 李佳宁,王东凯,张史梁. 基于深度学习的二维人体姿态估计:现状及展望[J]. 计算机学报, 2024, 47(1): 231-250. |
| LI J N, WANG D K, ZHANG S L. Deep-learning-based 2D human pose estimation: present and future[J]. Chinese Journal of Computers, 2024, 47(1): 231-250. | |
| [3] | 白雪冰,车进,吴金蔓,等. 基于Transformer视觉特征融合的图像描述方法[J]. 计算机工程, 2024, 50(8): 229-238. |
| BAI X B, CHE J, WU J M, et al. Image captioning method based on Transformer visual features fusion[J]. Computer Engineering, 2024, 50(8): 229-238. | |
| [4] | GAO C, ZOU Y, HUANG J B. iCAN: Instance-centric attention network for human-object interaction detection[C]// Proceedings of the 2018 British Machine Vision Conference. Durham: BMVA Press, 2018: No.17. |
| [5] | 宁欣,田伟娟,于丽娜,等. 面向小目标和遮挡目标检测的脑启发CIRA-DETR全推理方法[J]. 计算机学报, 2022, 45(10): 2080-2092. |
| NING X, TIAN W J, YU L N, et al. Brain-inspired CIRA-DETR full inference model for small and occluded object detection[J]. Chinese Journal of Computers, 2022, 45(10): 2080-2092. | |
| [6] | TAMURA M, OHASHI H, YOSHINAGA T. QPIC: query-based pairwise human-object interaction detection with image-wide contextual information[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10405-10414. |
| [7] | KIM B, LEE J, KANG J, et al. HOTR: end-to-end human-object interaction detection with Transformers[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 74-83. |
| [8] | ZHANG A, LIAO Y, LIU S, et al. Mining the benefits of two-stage and one-stage HOI detection[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 17209-17220. |
| [9] | LIAO Y, ZHANG A, LU M, et al. GEN-VLKT: simplify association and enhance interaction understanding for HOI detection[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 20091-20100. |
| [10] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [11] | CHAO Y W, WANG Z, HE Y, et al. HICO: a benchmark for recognizing human-object interactions in images[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1017-1025. |
| [12] | GUPTA S, MALIK J. Visual semantic role labeling[EB/OL]. [2024-05-17].. |
| [13] | WU K, PENG H, CHEN M, et al. Rethinking and improving relative position encoding for vision Transformer[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 10013-10021. |
| [14] | 李大海,王忠华,王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 计算机应用, 2024, 44(7): 2175-2182. |
| LI D H, WANG Z H, WANG Z D. Dual-branch low-light image enhancement network combining spatial and frequency domain information[J]. Journal of Computer Applications, 2024, 44(7): 2175-2182. | |
| [15] | MISRA D, NALAMADA T, ARASANIPALAI A U, et al. Rotate to attend: convolutional triplet attention module[C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2021: 3138-3147. |
| [16] | JIANG M, ZENG P, WANG K, et al. FECAM: frequency enhanced channel attention mechanism for time series forecasting[J]. Advanced Engineering Informatics, 2023, 58: No.102158. |
| [17] | GAO C, XU J, ZOU Y, et al. DRG: dual relation graph for human-object interaction detection[C]// Proceedings of the 2020 European Conference on Computer Vision. Cham: Springer, 2020: 696-712. |
| [18] | ZOU C, WANG B, HU Y, et al. End-to-end human object interaction detection with HOI Transformer[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 11820-11829. |
| [19] | ZHANG F Z, CAMPBELL D, GOULD S. Spatially conditioned graphs for detecting human-object interactions[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 13299-13307. |
| [20] | KIM B, MUN J, ON K W, et al. MSTR: multi-scale Transformer for end-to-end human-object interaction detection[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 19556-19565. |
| [21] | ZHANG F Z, CAMPBELL D, GOULD S. Efficient two-stage detection of human-object interactions with a novel unary-pairwise Transformer[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 20072-20080. |
| [22] | WANG Y, TENG Y, WANG L. CycleHOI: improving human-object interaction detection with cycle consistency of detection and generation[EB/OL]. [2024-07-16].. |
| [23] | ZHENG S, XU B, JIN Q. Open-category human-object interaction pre-training via language modeling framework[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 19392-19402. |
| [24] | PENG H, LIU F, LI Y, et al. Parallel reasoning network for human-object interaction detection[EB/OL]. [2024-01-09].. |
| [25] | CHAN S, ZENG X, WANG X, et al. Auxiliary feature fusion and noise suppression for HOI detection[J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2024, 20(10): No.299. |
| [1] | 李明光, 陶重犇. 基于Mamba模型的分级跨模态融合三维目标检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 572-579. |
| [2] | 李世伟, 周昱峰, 孙鹏飞, 刘伟松, 孟竹喧, 廉浩杰. 基于煤尘对激光雷达电磁波散射和吸收效应的点云数据增强方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 331-340. |
| [3] | 边小勇, 袁培洋, 胡其仁. 双编码空频混合的红外小目标检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 252-259. |
| [4] | 黄舒雯, 郭柯宇, 宋翔宇, 韩锋, 孙士杰, 宋焕生. 基于单目图像的多目标三维视觉定位方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 207-215. |
| [5] | 桑雨, 贡同, 赵琛, 于博文, 李思漫. 具有光度对齐的域适应夜间目标检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 242-251. |
| [6] | 谢斌红, 王瑞, 张睿, 张英俊. 代理原型蒸馏的小样本目标检测算法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 233-241. |
| [7] | 张嘉祥, 李晓明, 张佳慧. 结合新类特征增强与度量机制的小样本目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2984-2992. |
| [8] | 魏利利, 闫丽蓉, 唐晓芬. 上下文语义表征和像素关系纠正的小样本目标检测[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2993-3002. |
| [9] | 谢斌红, 剌颖坤, 张英俊, 张睿. 自步学习指导下的半监督目标检测框架[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2546-2554. |
| [10] | 颜承志, 陈颖, 钟凯, 高寒. 基于多尺度网络与轴向注意力的3D目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2537-2545. |
| [11] | 廖炎华, 鄢元霞, 潘文林. 基于YOLOv9的交通路口图像的多目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2555-2565. |
| [12] | 陈亮, 王璇, 雷坤. 复杂场景下跨层多尺度特征融合的安全帽佩戴检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2333-2341. |
| [13] | 张子墨, 赵雪专. 多尺度稀疏图引导的视觉图神经网络[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2188-2194. |
| [14] | 于平平, 闫玉婷, 唐心亮, 苏鹤, 王建超. 输电线路场景下的施工机械多目标跟踪算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2351-2360. |
| [15] | 范博淦, 王淑青, 陈开元. 基于改进YOLOv8的航拍无人机小目标检测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2342-2350. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||