


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (7): 2188-2194.DOI: 10.11772/j.issn.1001-9081.2024070910
张子墨1, 赵雪专2,3,4,5( )
)
收稿日期:2024-07-01
修回日期:2024-11-06
接受日期:2024-11-11
发布日期:2025-07-10
出版日期:2025-07-10
通讯作者:
赵雪专
作者简介:张子墨(2001—),女,河南郑州人,硕士研究生,主要研究方向:机器学习、大数据分析
基金资助:
Zimo ZHANG1, Xuezhuan ZHAO2,3,4,5()
Received:2024-07-01
Revised:2024-11-06
Accepted:2024-11-11
Online:2025-07-10
Published:2025-07-10
Contact:
Xuezhuan ZHAO
About author:ZHANG Zimo, born in 2001, M. S. candidate. Her research interests include machine learning, big data analysis.
Supported by:摘要:
近年来,视觉图神经网络(ViG)在计算机视觉领域引起了研究人员的广泛关注,其中构图是ViG的重要建模方式。目前流行的K近邻(KNN)构图方法尺度单一、具有二次计算复杂度并且难以建模图像的局部和多尺度信息。为了解决该问题,提出一种尺度稀疏图的构筑方法——MSSG(Multi-Scale Sparse Graph)。该方法将KNN图沿通道分解为3个不同尺度的稀疏子图,具有线性的计算复杂度并且能实现图像局部信息和多尺度信息的有效建模。为了增强模型的全局建模能力,提出一种全局和局部多尺度信息融合策略。基于以上方法,提出一种视觉架构——MSViG(Multi-Scale Vision Graph neural network)。在ImageNet-1K数据集上进行的图像分类实验的结果表明,MSViG优于传统的ViG。例如,与视觉神经网络ViG-T相比,所提MSViG-T的Top-1分类准确率提高了2.1个百分点,并且在目标检测和实例分割视觉下游任务上MSViG相较于传统ViG取得了较大的性能提升。
中图分类号:
张子墨, 赵雪专. 多尺度稀疏图引导的视觉图神经网络[J]. 计算机应用, 2025, 45(7): 2188-2194.
Zimo ZHANG, Xuezhuan ZHAO. Multi-scale sparse graph guided vision graph neural networks[J]. Journal of Computer Applications, 2025, 45(7): 2188-2194.

图1 多尺度稀疏图
Fig. 1 Multi-scale sparse graphs
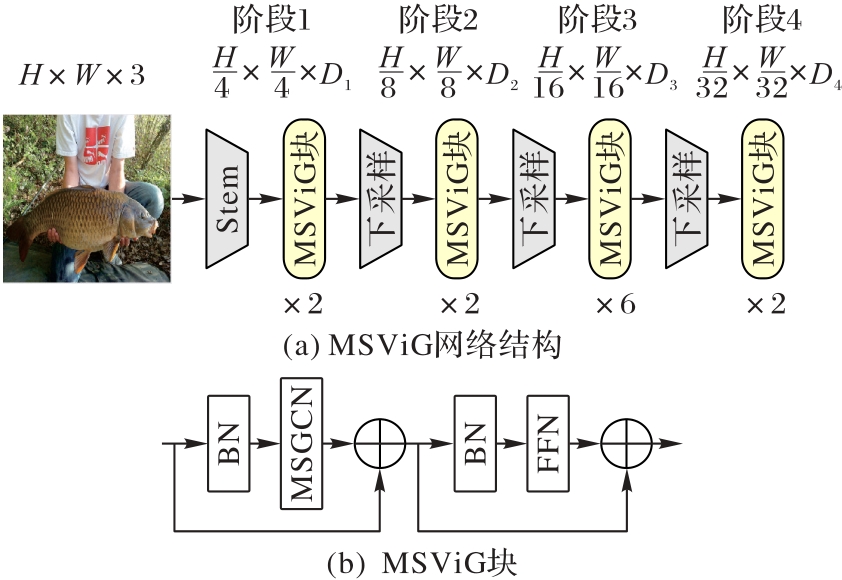
图2 MSViG模型架构
Fig. 2 Architecture of MSViG model
| 模型 | 通道维度 | 块数 | 通道比C1 |
|---|---|---|---|
| MSViG-T | [48, 96, 192, 192] | [2,2,6,2] | 0.8 |
| MSViG-S | [64, 128, 320, 512] | [3,3,10,3] | 0.6 |
| MSViG-M | [96, 192, 384, 768] | [3,3,12,3] | 0.5 |
| MSViG-B | [128, 256, 512, 768] | [3,4,14,4] | 0.4 |
表1 模型参数设置
Tab. 1 Model parameter setting
| 模型 | 通道维度 | 块数 | 通道比C1 |
|---|---|---|---|
| MSViG-T | [48, 96, 192, 192] | [2,2,6,2] | 0.8 |
| MSViG-S | [64, 128, 320, 512] | [3,3,10,3] | 0.6 |
| MSViG-M | [96, 192, 384, 768] | [3,3,12,3] | 0.5 |
| MSViG-B | [128, 256, 512, 768] | [3,4,14,4] | 0.4 |
| 模型 | 训练次数 | 优化器 | 初始学习率 | 学习率计划 | 预热训练次数 | 权重衰减 | Label smoothing | Stochastic path | Repeated augment |
|---|---|---|---|---|---|---|---|---|---|
| MSViG-T | 300 | AdamW | 2×10-3 | Cosine | 20 | 0.05 | 0.1 | 0.10 | √ |
| MSViG-S | 300 | AdamW | 2×10-3 | Cosine | 20 | 0.05 | 0.1 | 0.15 | √ |
| MSViG-M | 300 | AdamW | 2×10-3 | Cosine | 20 | 0.05 | 0.1 | 0.20 | √ |
| MSViG-B | 300 | AdamW | 2×10-3 | Cosine | 20 | 0.05 | 0.1 | 0.30 | √ |
表2 ImageNet-1K数据集的训练超参数
Tab. 2 Training hyper-parameters for ImageNet-1K dataset
| 模型 | 训练次数 | 优化器 | 初始学习率 | 学习率计划 | 预热训练次数 | 权重衰减 | Label smoothing | Stochastic path | Repeated augment |
|---|---|---|---|---|---|---|---|---|---|
| MSViG-T | 300 | AdamW | 2×10-3 | Cosine | 20 | 0.05 | 0.1 | 0.10 | √ |
| MSViG-S | 300 | AdamW | 2×10-3 | Cosine | 20 | 0.05 | 0.1 | 0.15 | √ |
| MSViG-M | 300 | AdamW | 2×10-3 | Cosine | 20 | 0.05 | 0.1 | 0.20 | √ |
| MSViG-B | 300 | AdamW | 2×10-3 | Cosine | 20 | 0.05 | 0.1 | 0.30 | √ |
| 模型 | 类型 | 参数量/106 | 运算量/GFLOPs | Top-1准确率/% | 模型 | 类型 | 参数量/106 | 运算量/GFLOPs | Top-1准确率/% |
|---|---|---|---|---|---|---|---|---|---|
| ResNet-18[ | CNN | 12.0 | 1.8 | 70.6 | SLaK-S[ | CNN | 55.0 | 9.8 | 83.8 |
| CycleMLP-B1[ | MLP | 15.0 | 2.1 | 78.9 | CycleMLP-B4[ | MLP | 52.0 | 10.1 | 83.0 |
| PVTv2-B1[ | ViT | 13.1 | 2.1 | 78.7 | Swin-S[ | ViT | 50.0 | 8.7 | 83.0 |
| ViG-T[ | GNN | 10.7 | 1.7 | 78.2 | PVTv2-B4[ | ViT | 62.6 | 10.1 | 83.6 |
| ViHGNN-T[ | GNN | 12.3 | 2.3 | 78.9 | DAT-S[ | ViT | 50.0 | 9.0 | 83.7 |
| MSViG-T | GNN | 11.7 | 1.8 | 80.3 | QFormer-S[ | ViT | 51.0 | 8.9 | 84.0 |
| ResNet-50[ | CNN | 25.6 | 4.1 | 79.8 | ViG-M[ | GNN | 51.7 | 8.9 | 83.1 |
| ConvNeXt-T[ | CNN | 28.6 | 4.5 | 82.1 | ViHGNN-M[ | GNN | 52.4 | 10.7 | 83.4 |
| InceptionNeXt-T[ | CNN | 28.0 | 4.2 | 82.3 | MSViG-M | GNN | 49.5 | 8.4 | 84.0 |
| SLaK-T[ | CNN | 30.0 | 5.0 | 82.5 | ConvNeXt-B[ | CNN | 89.0 | 15.4 | 83.8 |
| CycleMLP-B2[ | MLP | 27.0 | 3.9 | 81.6 | SLaK-B[ | CNN | 95.0 | 17.1 | 84.0 |
| Swin-T[ | ViT | 29.0 | 4.5 | 81.3 | InceptionNeXt-B[ | CNN | 87.0 | 14.9 | 84.0 |
| PVTv2-B2[ | ViT | 25.4 | 4.0 | 82.0 | CycleMLP-B5[ | MLP | 76.0 | 12.3 | 83.2 |
| DAT-T[ | ViT | 29.0 | 4.6 | 82.0 | Swin-B[ | ViT | 88.0 | 15.5 | 83.5 |
| QFormer-T[ | ViT | 29.0 | 4.6 | 82.5 | PVTv2-B5[ | ViT | 82.0 | 11.8 | 83.8 |
| ViG-S[ | GNN | 27.3 | 4.6 | 82.1 | DAT-B[ | ViT | 88.0 | 15.8 | 84.0 |
| ViHGNN-S[ | GNN | 28.5 | 6.3 | 82.5 | QFormer-B[ | ViT | 90.0 | 15.7 | 84.1 |
| MSViG-S | GNN | 26.1 | 4.4 | 83.1 | ViG-B[ | GNN | 92.6 | 16.8 | 83.7 |
| ResNet-152 [ | CNN | 60.2 | 11.5 | 81.8 | ViHGNN-B[ | GNN | 94.4 | 18.1 | 83.9 |
| ConvNeXt-S[ | CNN | 50.0 | 8.7 | 83.1 | MSViG-B | GNN | 82.7 | 16.2 | 84.3 |
| InceptionNeXt-S[ | CNN | 49.0 | 8.4 | 83.5 |
表3 ImageNet-1K数据集的图像分类结果对比
Tab. 3 Comparison of image classification results on ImageNet-1K dataset
| 模型 | 类型 | 参数量/106 | 运算量/GFLOPs | Top-1准确率/% | 模型 | 类型 | 参数量/106 | 运算量/GFLOPs | Top-1准确率/% |
|---|---|---|---|---|---|---|---|---|---|
| ResNet-18[ | CNN | 12.0 | 1.8 | 70.6 | SLaK-S[ | CNN | 55.0 | 9.8 | 83.8 |
| CycleMLP-B1[ | MLP | 15.0 | 2.1 | 78.9 | CycleMLP-B4[ | MLP | 52.0 | 10.1 | 83.0 |
| PVTv2-B1[ | ViT | 13.1 | 2.1 | 78.7 | Swin-S[ | ViT | 50.0 | 8.7 | 83.0 |
| ViG-T[ | GNN | 10.7 | 1.7 | 78.2 | PVTv2-B4[ | ViT | 62.6 | 10.1 | 83.6 |
| ViHGNN-T[ | GNN | 12.3 | 2.3 | 78.9 | DAT-S[ | ViT | 50.0 | 9.0 | 83.7 |
| MSViG-T | GNN | 11.7 | 1.8 | 80.3 | QFormer-S[ | ViT | 51.0 | 8.9 | 84.0 |
| ResNet-50[ | CNN | 25.6 | 4.1 | 79.8 | ViG-M[ | GNN | 51.7 | 8.9 | 83.1 |
| ConvNeXt-T[ | CNN | 28.6 | 4.5 | 82.1 | ViHGNN-M[ | GNN | 52.4 | 10.7 | 83.4 |
| InceptionNeXt-T[ | CNN | 28.0 | 4.2 | 82.3 | MSViG-M | GNN | 49.5 | 8.4 | 84.0 |
| SLaK-T[ | CNN | 30.0 | 5.0 | 82.5 | ConvNeXt-B[ | CNN | 89.0 | 15.4 | 83.8 |
| CycleMLP-B2[ | MLP | 27.0 | 3.9 | 81.6 | SLaK-B[ | CNN | 95.0 | 17.1 | 84.0 |
| Swin-T[ | ViT | 29.0 | 4.5 | 81.3 | InceptionNeXt-B[ | CNN | 87.0 | 14.9 | 84.0 |
| PVTv2-B2[ | ViT | 25.4 | 4.0 | 82.0 | CycleMLP-B5[ | MLP | 76.0 | 12.3 | 83.2 |
| DAT-T[ | ViT | 29.0 | 4.6 | 82.0 | Swin-B[ | ViT | 88.0 | 15.5 | 83.5 |
| QFormer-T[ | ViT | 29.0 | 4.6 | 82.5 | PVTv2-B5[ | ViT | 82.0 | 11.8 | 83.8 |
| ViG-S[ | GNN | 27.3 | 4.6 | 82.1 | DAT-B[ | ViT | 88.0 | 15.8 | 84.0 |
| ViHGNN-S[ | GNN | 28.5 | 6.3 | 82.5 | QFormer-B[ | ViT | 90.0 | 15.7 | 84.1 |
| MSViG-S | GNN | 26.1 | 4.4 | 83.1 | ViG-B[ | GNN | 92.6 | 16.8 | 83.7 |
| ResNet-152 [ | CNN | 60.2 | 11.5 | 81.8 | ViHGNN-B[ | GNN | 94.4 | 18.1 | 83.9 |
| ConvNeXt-S[ | CNN | 50.0 | 8.7 | 83.1 | MSViG-B | GNN | 82.7 | 16.2 | 84.3 |
| InceptionNeXt-S[ | CNN | 49.0 | 8.4 | 83.5 |
| 解码器及训练时长 | 骨干网络 | 参数量/106 | 浮点运算量/GFLOPs | 平均精度/% | |||||
|---|---|---|---|---|---|---|---|---|---|
| RetinaNet 1× | ResNet-50 | 38 | 239 | 36.3 | 55.3 | 38.6 | 19.3 | 40.0 | 48.8 |
| PVT-Small | 34 | 227 | 40.4 | 61.3 | 44.2 | 25.0 | 42.9 | 55.7 | |
| Swin-T | 39 | 245 | 41.5 | 62.1 | 44.2 | 25.1 | 44.9 | 55.5 | |
| ViG-S | 36 | 240 | 41.8 | 63.1 | 44.7 | 28.5 | 45.4 | 53.4 | |
| ViHGNN-S | 38 | 244 | 42.2 | 63.8 | 45.1 | 29.3 | 45.9 | 55.7 | |
| MSViG-S | 33 | 243 | 42.9 | 64.3 | 45.9 | 28.6 | 47.7 | 55.9 | |
| Mask R-CNN 1× | ResNet-50 | 44 | 260 | 38.0 | 58.6 | 41.4 | 34.4 | 55.1 | 36.7 |
| PVT-Small | 44 | 245 | 40.4 | 62.9 | 43.8 | 37.8 | 60.1 | 40.3 | |
| Swin-T | 48 | 264 | 42.2 | 64.6 | 46.2 | 39.1 | 61.6 | 42.0 | |
| ViG-S | 46 | 259 | 42.6 | 65.2 | 46.0 | 39.4 | 62.4 | 41.6 | |
| ViHGNN-S | 48 | 262 | 43.1 | 66.0 | 46.5 | 39.6 | 63.0 | 42.3 | |
| MSViG-S | 45 | 261 | 44.3 | 66.4 | 48.7 | 39.8 | 63.4 | 42.7 | |
表4 目标检测和实例分割的结果
Tab. 4 Results of object detection and instance segmentation
| 解码器及训练时长 | 骨干网络 | 参数量/106 | 浮点运算量/GFLOPs | 平均精度/% | |||||
|---|---|---|---|---|---|---|---|---|---|
| RetinaNet 1× | ResNet-50 | 38 | 239 | 36.3 | 55.3 | 38.6 | 19.3 | 40.0 | 48.8 |
| PVT-Small | 34 | 227 | 40.4 | 61.3 | 44.2 | 25.0 | 42.9 | 55.7 | |
| Swin-T | 39 | 245 | 41.5 | 62.1 | 44.2 | 25.1 | 44.9 | 55.5 | |
| ViG-S | 36 | 240 | 41.8 | 63.1 | 44.7 | 28.5 | 45.4 | 53.4 | |
| ViHGNN-S | 38 | 244 | 42.2 | 63.8 | 45.1 | 29.3 | 45.9 | 55.7 | |
| MSViG-S | 33 | 243 | 42.9 | 64.3 | 45.9 | 28.6 | 47.7 | 55.9 | |
| Mask R-CNN 1× | ResNet-50 | 44 | 260 | 38.0 | 58.6 | 41.4 | 34.4 | 55.1 | 36.7 |
| PVT-Small | 44 | 245 | 40.4 | 62.9 | 43.8 | 37.8 | 60.1 | 40.3 | |
| Swin-T | 48 | 264 | 42.2 | 64.6 | 46.2 | 39.1 | 61.6 | 42.0 | |
| ViG-S | 46 | 259 | 42.6 | 65.2 | 46.0 | 39.4 | 62.4 | 41.6 | |
| ViHGNN-S | 48 | 262 | 43.1 | 66.0 | 46.5 | 39.6 | 63.0 | 42.3 | |
| MSViG-S | 45 | 261 | 44.3 | 66.4 | 48.7 | 39.8 | 63.4 | 42.7 | |
| 方法 | 参数量/106 | 浮点运算量/GFLOPs | mIoU/% |
|---|---|---|---|
| ResNet-50 | 29 | 183 | 36.7 |
| PVT-S | 28 | 225 | 42.0 |
| DAT-T | 32 | 198 | 42.6 |
| Swin-T | 32 | 182 | 41.5 |
| MSViG-S | 30 | 176 | 43.8 |
表5 语义分割结果
Tab. 5 Results of semantic segmentation
| 方法 | 参数量/106 | 浮点运算量/GFLOPs | mIoU/% |
|---|---|---|---|
| ResNet-50 | 29 | 183 | 36.7 |
| PVT-S | 28 | 225 | 42.0 |
| DAT-T | 32 | 198 | 42.6 |
| Swin-T | 32 | 182 | 41.5 |
| MSViG-S | 30 | 176 | 43.8 |
| 方法 | 参数量/106 | 运算量/GFLOPs | Top-1准确率/% |
|---|---|---|---|
| KNN图 | 11.7 | 1.9 | 78.6 |
| MSSG | 11.7 | 1.6 | 79.8 |
| MSSG+GLMIF | 11.7 | 1.8 | 80.3 |
表6 消融实验结果
Tab. 6 Results of ablation experiments
| 方法 | 参数量/106 | 运算量/GFLOPs | Top-1准确率/% |
|---|---|---|---|
| KNN图 | 11.7 | 1.9 | 78.6 |
| MSSG | 11.7 | 1.6 | 79.8 |
| MSSG+GLMIF | 11.7 | 1.8 | 80.3 |

图3 Grad-CAM的可视化图
Fig. 3 Grad-CAM visualization maps
| [1] | LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition [J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. |
| [2] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [J]. Communications of the ACM, 2017, 60(6): 84-90. |
| [3] | RUSSAKOVSKY O, DENG J, SU H, et al. ImageNet large scale visual recognition challenge [J]. International Journal of Computer Vision, 2015, 115(3): 211-252. |
| [4] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [5] | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale [EB/OL]. [2024-05-11]. . |
| [6] | TOUVRON H, CORD M, DOUZE M, et al. Training data-efficient image transformers & distillation through attention [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 10347-10357. |
| [7] | LIU Z, LIN Y, CAO Y, et al. [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002. |
| [8] | WANG W, XIE E, LI X, et al. Pyramid vision Transformer: a versatile backbone for dense prediction without convolutions [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 548-558. |
| [9] | HAN K, WANG Y, GUO J, et al. Vision GNN: an image is worth graph of nodes [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 8291-8303. |
| [10] | HAN Y, WANG P, KUNDU S, et al. Vision HGNN: an image is more than a graph of nodes [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 19821-19831. |
| [11] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. [2024-05-11]. . |
| [12] | SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C]// Proceedings of the 18th IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1-9. |
| [13] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [14] | DAI J, QI H, XIONG Y, et al. Deformable convolutional networks [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 764-773. |
| [15] | HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional network [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2261-2269. |
| [16] | LIU Z, MAO H, WU C Y, et al. A ConvNet for the 2020s [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 11966-11976. |
| [17] | LIU S, CHEN T, CHEN X, et al. More convNets in the 2020s: scaling up kernels beyond 51×51 using sparsity [EB/OL]. [2024-05-11]. . |
| [18] | WANG W, XIE E, LI X, et al. PVT v2: improved baselines with pyramid vision Transformer [J]. Computational Visual Media, 2022, 8(3): 415-424. |
| [19] | XIA Z, PAN X, SONG S, et al. Vision Transformer with deformable attention [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 4784-4793. |
| [20] | TOLSTIKHIN I, HOULSBY N, KOLESNIKOV A, et al. MLP-Mixer: an all-MLP architecture for vision [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 24261-24272. |
| [21] | TOUVRON H, BOJANOWSKI P, CARON M, et al. ResMLP: feedforward networks for image classification with data-efficient training [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(4): 5314-5321. |
| [22] | CHEN S, XIE E, GE C, et al. CycleMLP: a MLP-like architecture for dense prediction [EB/OL]. [2024-05-11]. . |
| [23] | GORI M, MONFARDINI G, SCARSELLI F. A new model for learning in Graph domains [C]// Proceedings of the 2005 IEEE International Joint Conference on Neural Networks — Volume 2. Piscataway: IEEE, 2005: 729-734. |
| [24] | SCARSELLI F, GORI M, CHUNG TSOI AH, et al. The graph neural network model [J]. IEEE Transactions on Neural Networks, 2009: 61-80. |
| [25] | 吴博,梁循,张树森,等.图神经网络前沿进展与应用[J].计算机学报,2022, 45(1): 35-68. |
| WU B, LIANG X, ZHANG S S, et al. Advances and applications of graph neural networks [J]. Chinese Journal of Computers, 2022, 45(1): 35-68. | |
| [26] | 徐冰冰,岑科廷,黄俊杰,等.图卷积神经网络综述[J].计算机学报,2020, 43(5): 755-780. |
| XU B B, CEN K T, HUANG J J, et al. A survey of graph convolutional neural network [J]. Chinese Journal of Computers, 2020, 43(5): 755-780. | |
| [27] | 郭嘉琰,李荣华,张岩,等.基于图神经网络的动态网络异常检测算法[J].软件学报,2020, 31(3): 748-762. |
| GUO J Y, LI R H, ZHANG Y, et al. Graph neural network based anomaly detection in dynamic networks [J]. Journal of Software, 2020, 31(3): 748-762. | |
| [28] | 呼延康,樊鑫,余乐天,等.图神经网络回归的人脸超分辨率重建[J].软件学报,2018, 29(4): 914-925. |
| HUYAN K, FAN X, YU L T, et al. Graph based neural network regression strategy for facial image super-resolution [J]. Journal of Software, 2018, 29(4): 914-925. | |
| [29] | 潘润超,虞启山,熊泓霏,等.基于深度图神经网络的协同推荐算法[J].计算机应用,2023, 43(9): 2741-2746. |
| PAN R C, YU Q S, XIONG H F, et al. Collaborative recommendation algorithm based on deep graph neural network [J]. Journal of Computer Applications, 2023, 43(9): 2741-2746. | |
| [30] | 刘欢,李晓戈,胡立坤,等.基于知识图谱驱动的图神经网络推荐模型[J].计算机应用,2021, 41(7): 1865-1870. |
| LIU H, LI X G, HU L K, et al. Knowledge graph driven recommendation model of graph neural network [J]. Journal of Computer Applications, 2021, 41(7): 1865-1870. | |
| [31] | CHEN Z M, WEI X S, WANG P, et al. Multi-label image recognition with graph convolutional networks [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 5172-5181. |
| [32] | ZHAO G, GE W, YU Y. GraphFPN: graph feature pyramid network for object detection [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 2743-2752. |
| [33] | ZHANG L, LI X, ARNAB A, et al. Dual graph convolutional network for semantic segmentation [C]// Proceedings of the 2019 British Machine Vision Conference. Durham: BMVA Press, 2019: No.254. |
| [34] | LI G, MÜLLER M, THABET A, et al. DeepGCNs: can GCNs go as deep as CNNs? [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9266-9275. |
| [35] | HENDRYCKS D, GIMPEL K. Gaussian Error Linear Units(GELUs) [EB/OL]. [2024-05-11]. . |
| [36] | PASZKE A, GROSS S, MASSA F, et al. PyTorch: an imperative style, high-performance deep learning library [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 8026-8037. |
| [37] | LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization [EB/OL]. [2024-05-11]. . |
| [38] | CUBUK E D, ZOPH B, SHLENS J, et al. Randaugment: practical automated data augmentation with a reduced search space [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2020: 3008-3017. |
| [39] | HOFFER E, BEN-NUN T, HUBARA I, et al. Augment your batch: improving generalization through instance repetition [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 8126-8135. |
| [40] | ZHANG H, CISSE M, DAUPHIN Y N, et al. mixup: beyond empirical risk minimization [EB/OL]. [2024-05-11]. . |
| [41] | YUN S, HAN D, CHUN S, et al. CutMix: regularization strategy to train strong classifiers with localizable features [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 6022-6031. |
| [42] | ZHONG Z, ZHENG L, KANG G, et al. Random erasing data augmentation [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 13001-13008. |
| [43] | SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2818-2826. |
| [44] | HUANG G, SUN Y, LIU Z, et al. Deep networks with stochastic depth [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9908. Cham: Springer, 2016: 646-661. |
| [45] | YU W, ZHOU P, YAN S, et al. InceptionNeXT: when inception meets ConvNeXT [C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 5672-5683. |
| [46] | ZHANG Q, ZHANG J, XU Y, et al. Vision Transformer with quadrangle attention [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(5): 3608-3624. |
| [47] | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// Proceedings of the 2014 European Conference on Computer Vision European Conference, LNCS 8693. Cham: Springer, 2014: 740-755. |
| [48] | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2999-3007. |
| [49] | HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 386-397. |
| [50] | ZHOU B, ZHAO H, PUIG X, et al. Scene parsing through ADE20K dataset [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5122-5130. |
| [51] | KIRILLOV A, GIRSHICK R, HE K, et al. Panoptic feature pyramid networks [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6392-6401. |
| [52] | SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization [J]. International Journal of Computer Vision, 2020, 128(2): 336-359. |
| [1] | 蒋权, 黄文清, 苟志勇. 基于等变图神经网络的拉格朗日粒子流模拟[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2666-2671. |
| [2] | 谢斌红, 剌颖坤, 张英俊, 张睿. 自步学习指导下的半监督目标检测框架[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2546-2554. |
| [3] | 赵彪, 秦玉华, 田荣坤, 胡月航, 陈芳锐. 依赖类型及距离增强的方面级情感分析模型[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2507-2514. |
| [4] | 颜承志, 陈颖, 钟凯, 高寒. 基于多尺度网络与轴向注意力的3D目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2537-2545. |
| [5] | 王静, 刘嘉星, 宋婉莹, 薛嘉兴, 丁温欣. 基于空间变换网络和特征分布校准的小样本皮肤图像分类模型[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2720-2726. |
| [6] | 王义, 马应龙. 基于项图动态适应性生成的多任务社交项推荐方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2592-2599. |
| [7] | 廖炎华, 鄢元霞, 潘文林. 基于YOLOv9的交通路口图像的多目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2555-2565. |
| [8] | 涂银川, 郭勇, 毛恒, 任怡, 张建锋, 李宝. 基于分布式环境的图神经网络模型训练效率与训练性能评估[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2409-2420. |
| [9] | 于平平, 闫玉婷, 唐心亮, 苏鹤, 王建超. 输电线路场景下的施工机械多目标跟踪算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2351-2360. |
| [10] | 陈丹阳, 张长伦. 多尺度去相关的图卷积网络模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2180-2187. |
| [11] | 张悦岚, 苏静, 赵航宇, 杨白利. 基于知识感知与交互的多视图蒸馏推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2211-2220. |
| [12] | 范博淦, 王淑青, 陈开元. 基于改进YOLOv8的航拍无人机小目标检测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2342-2350. |
| [13] | 张英俊, 闫薇薇, 谢斌红, 张睿, 陆望东. 梯度区分与特征范数驱动的开放世界目标检测[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2203-2210. |
| [14] | 蒋沛宇, 王永光, 任亚亭, 李硕晨, 谭火彬. 基于测量不确定度表示指南的红外目标检测不确定度测量方案[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2162-2168. |
| [15] | 齐巧玲, 王啸啸, 张茜茜, 汪鹏, 董永峰. 基于元学习的标签噪声自适应学习算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2113-2122. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||