


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (4): 1124-1130.DOI: 10.11772/j.issn.1001-9081.2025040515
张婧1, 刘松华2( ), 朱远乾2
), 朱远乾2
收稿日期:2025-05-12
修回日期:2025-06-30
接受日期:2025-07-02
发布日期:2025-07-11
出版日期:2026-04-10
通讯作者:
刘松华
作者简介:张婧(2000—),女,山西朔州人,硕士研究生,CCF会员,主要研究方向:时序表示学习与预测、数据挖掘基金资助:
Jing ZHANG1, Songhua LIU2(), Yuanqian ZHU2
Received:2025-05-12
Revised:2025-06-30
Accepted:2025-07-02
Online:2025-07-11
Published:2026-04-10
Contact:
Songhua LIU
About author:ZHANG Jing, born in 2000, M. S. candidate. Her research interests include time series representation learning and prediction, data mining.Supported by:摘要:
时间序列数据在电力负荷预测和气象分析等领域广泛应用,提炼高质量的时间序列表示对下游预测任务至关重要。然而,高频噪声干扰、长期依赖的建模困难和标记稀缺问题限制了现有方法的性能。因此,提出一种基于频谱滤波和层次化扩张(SFHD)的时间序列表示方法。首先,设计频谱滤波块(SFB),通过全局与局部滤波器提取多尺度特征,并在频域采用自适应频谱滤波机制,从而削弱高频噪声的影响;其次,构建层次化扩张块(HDB),利用指数膨胀卷积结构逐层扩大感受野,提升对长期依赖关系的捕获能力;最后,提出变化感知的自监督预训练策略,通过掩蔽高动态变化数据块,迫使模型理解序列的潜在结构,从而缓解标记不足的问题。在7个公开数据集上不同预测长度的实验结果表明,相较于次优模型iTransformer(inverted Transformer),SFHD的均方误差(MSE)指标的平均值下降了9.47%,平均绝对误差(MAE)指标的平均值下降了5.36%。实验结果验证了SFHD具有更强的表征能力,对下游时间序列预测任务的表现有所提升。
中图分类号:
张婧, 刘松华, 朱远乾. 基于频谱感知和层次卷积的时间序列表示方法[J]. 计算机应用, 2026, 46(4): 1124-1130.
Jing ZHANG, Songhua LIU, Yuanqian ZHU. Time series representation method based on spectral sensing and hierarchical convolution[J]. Journal of Computer Applications, 2026, 46(4): 1124-1130.
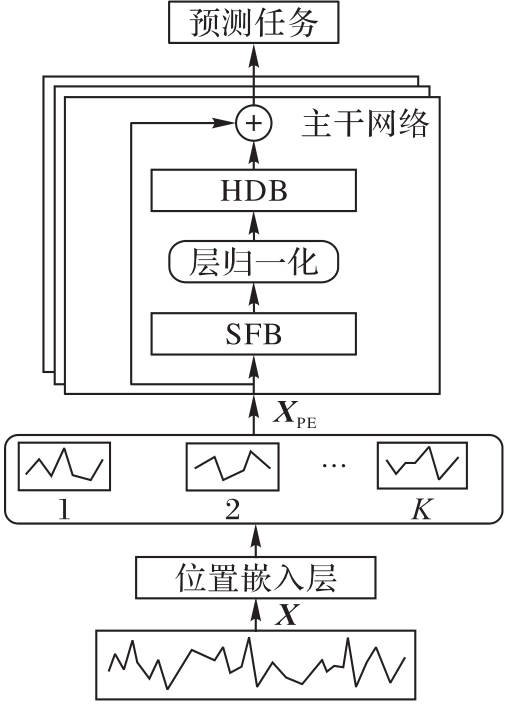
图1 SFHD模型的架构
Fig. 1 Architecture of SFHD model
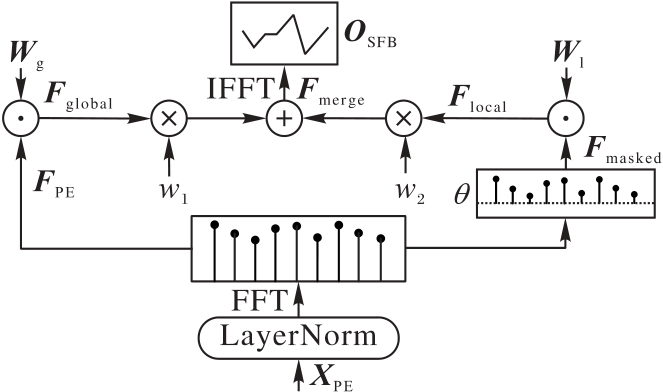
图2 SFB的结构
Fig. 2 Structure of SFB
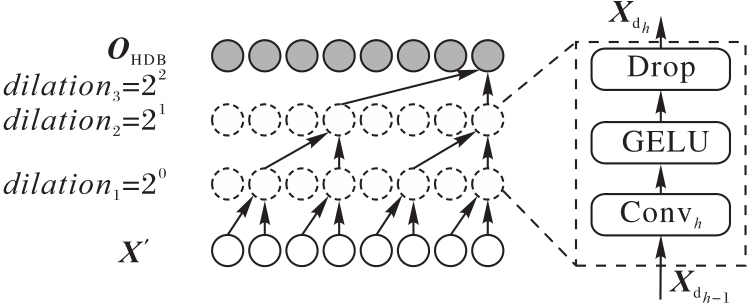
图3 HDB的结构
Fig. 3 Structure of HDB
| 数据集 | 变量数 | 时间步数 | 采样频率/min |
|---|---|---|---|
| ETTh1&ETTh2 | 7 | 17 420 | 60 |
| ETTm1&ETTm2 | 7 | 69 680 | 15 |
| Weather | 21 | 52 696 | 10 |
| Exchange_rate | 8 | 7 588 | 1 440 |
| ILI | 7 | 966 | 10 080 |
表1 数据集描述
Tab. 1 Dataset description
| 数据集 | 变量数 | 时间步数 | 采样频率/min |
|---|---|---|---|
| ETTh1&ETTh2 | 7 | 17 420 | 60 |
| ETTm1&ETTm2 | 7 | 69 680 | 15 |
| Weather | 21 | 52 696 | 10 |
| Exchange_rate | 8 | 7 588 | 1 440 |
| ILI | 7 | 966 | 10 080 |
图4 Exchange_rate数据集的时序图
Fig. 4 Time series diagrams of Exchange_rate dataset
| 数据集 | 输入长度 | 批量大小 | 块大小 | 模型层数 |
|---|---|---|---|---|
| ETTh1 | 512 | 512 | 32 | 1 |
| ETTh2 | 512 | 512 | 32 | 1 |
| ETTm1 | 512 | 512 | 8 | 2 |
| ETTm2 | 512 | 512 | 64 | 1 |
| Weather | 96 | 64 | 64 | 4 |
| Exchange_rate | 64 | 64 | 64 | 3 |
| ILI | 36 | 36 | 2 | 2 |
表2 数据集的对应参数
Tab. 2 Corresponding parameters of datasets
| 数据集 | 输入长度 | 批量大小 | 块大小 | 模型层数 |
|---|---|---|---|---|
| ETTh1 | 512 | 512 | 32 | 1 |
| ETTh2 | 512 | 512 | 32 | 1 |
| ETTm1 | 512 | 512 | 8 | 2 |
| ETTm2 | 512 | 512 | 64 | 1 |
| Weather | 96 | 64 | 64 | 4 |
| Exchange_rate | 64 | 64 | 64 | 3 |
| ILI | 36 | 36 | 2 | 2 |
| 数据集 | 预测长度 | SFHD | iTransformer | Crossformer | MICN | CrossTimeNet | TimesNet | SimMTM | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| ETTh1 | 96 | 0.369 | 0.400 | 0.386 | 0.405 | 0.423 | 0.448 | 0.426 | 0.446 | 0.456 | 0.465 | 0.546 | 0.497 | ||
| 192 | 0.411 | 0.427 | 0.441 | 0.436 | 0.471 | 0.474 | 0.454 | 0.464 | 0.495 | 0.484 | 0.568 | 0.511 | |||
| 336 | 0.398 | 0.429 | 0.570 | 0.546 | 0.493 | 0.487 | 0.513 | 0.496 | 0.491 | 0.469 | 0.562 | 0.523 | |||
| 720 | 0.466 | 0.479 | 0.653 | 0.621 | 0.526 | 0.526 | 0.540 | 0.533 | 0.521 | 0.500 | 0.720 | 0.609 | |||
| Avg | 0.411 | 0.434 | 0.529 | 0.522 | 0.475 | 0.480 | 0.501 | 0.495 | 0.458 | 0.450 | 0.599 | 0.535 | |||
| ETTh2 | 96 | 0.258 | 0.328 | 0.745 | 0.584 | 0.372 | 0.424 | 0.359 | 0.405 | 0.340 | 0.374 | 0.395 | 0.420 | ||
| 192 | 0.309 | 0.363 | 0.380 | 0.877 | 0.656 | 0.492 | 0.492 | 0.417 | 0.402 | 0.414 | 0.469 | 0.454 | |||
| 336 | 0.310 | 0.371 | 0.428 | 0.432 | 1.043 | 0.731 | 0.607 | 0.555 | 0.452 | 0.452 | 0.464 | 0.463 | |||
| 720 | 0.399 | 0.440 | 1.104 | 0.763 | 0.824 | 0.655 | 0.454 | 0.462 | 0.468 | 0.488 | 0.484 | ||||
| Avg | 0.319 | 0.376 | 0.942 | 0.684 | 0.574 | 0.531 | 0.384 | 0.424 | 0.414 | 0.427 | 0.454 | 0.455 | |||
| ETTm1 | 96 | 0.286 | 0.343 | 0.404 | 0.426 | 0.365 | 0.387 | 0.343 | 0.382 | 0.338 | 0.375 | 0.461 | 0.442 | ||
| 192 | 0.323 | 0.368 | 0.377 | 0.391 | 0.450 | 0.451 | 0.403 | 0.408 | 0.405 | 0.374 | 0.469 | 0.451 | |||
| 336 | 0.349 | 0.385 | 0.426 | 0.420 | 0.532 | 0.515 | 0.436 | 0.431 | 0.420 | 0.418 | 0.502 | 0.473 | |||
| 720 | 0.399 | 0.417 | 0.491 | 0.459 | 0.666 | 0.589 | 0.489 | 0.462 | 0.464 | 0.478 | 0.542 | 0.510 | |||
| Avg | 0.339 | 0.378 | 0.407 | 0.410 | 0.513 | 0.495 | 0.423 | 0.422 | 0.403 | 0.417 | 0.494 | 0.469 | |||
| ETTm2 | 96 | 0.169 | 0.259 | 0.287 | 0.366 | 0.197 | 0.296 | 0.208 | 0.297 | 0.187 | 0.267 | 0.230 | 0.302 | ||
| 192 | 0.228 | 0.300 | 0.250 | 0.414 | 0.492 | 0.284 | 0.361 | 0.259 | 0.328 | 0.311 | 0.357 | ||||
| 336 | 0.279 | 0.333 | 0.597 | 0.542 | 0.381 | 0.429 | 0.317 | 0.361 | 0.321 | 0.351 | 0.421 | 0.421 | |||
| 720 | 0.355 | 0.382 | 0.412 | 0.407 | 1.730 | 1.042 | 0.549 | 0.522 | 0.404 | 0.408 | 0.569 | 0.492 | |||
| Avg | 0.258 | 0.319 | 0.757 | 0.611 | 0.353 | 0.402 | 0.293 | 0.348 | 0.291 | 0.333 | 0.383 | 0.393 | |||
| Exchange_rate | 96 | 0.080 | 0.197 | 0.256 | 0.367 | 0.148 | 0.278 | 0.244 | 0.367 | 0.107 | 0.234 | 0.223 | 0.341 | ||
| 192 | 0.170 | 0.292 | 0.470 | 0.509 | 0.271 | 0.315 | 0.328 | 0.417 | 0.226 | 0.344 | 0.344 | 0.431 | |||
| 336 | 0.317 | 0.406 | 1.268 | 0.883 | 0.460 | 0.427 | 0.605 | 0.583 | 0.367 | 0.448 | 0.515 | 0.537 | |||
| 720 | 0.846 | 0.691 | 1.767 | 1.068 | 1.195 | 0.695 | 1.194 | 0.832 | 0.964 | 0.746 | 1.192 | 0.829 | |||
| Avg | 0.353 | 0.397 | 0.940 | 0.707 | 0.519 | 0.429 | 0.593 | 0.550 | 0.416 | 0.443 | 0.569 | 0.535 | |||
| ILI | 24 | 0.867 | 1.985 | 0.998 | 3.041 | 1.186 | 3.029 | 1.180 | 3.090 | 1.235 | 2.317 | 3.102 | 1.240 | ||
| 36 | 0.885 | 2.302 | 1.003 | 3.406 | 1.232 | 2.507 | 1.013 | 2.566 | 1.068 | 1.972 | 2.587 | 1.075 | |||
| 48 | 1.797 | 0.848 | 0.954 | 3.459 | 1.221 | 2.423 | 1.012 | 2.403 | 1.189 | 2.238 | 2.453 | 1.213 | |||
| 60 | 1.643 | 0.812 | 2.117 | 1.007 | 3.640 | 1.305 | 2.653 | 1.085 | 2.673 | 1.081 | 2.723 | 1.105 | |||
| Avg | 1.868 | 0.853 | 0.991 | 3.387 | 1.236 | 2.653 | 1.073 | 2.683 | 1.143 | 2.139 | 2.716 | 1.158 | |||
| Weather | 96 | 0.175 | 0.214 | 0.174 | 0.214 | 0.158 | 0.230 | 0.198 | 0.261 | 0.204 | 0.258 | 0.205 | 0.256 | ||
| 192 | 0.224 | 0.221 | 0.254 | 0.206 | 0.277 | 0.239 | 0.299 | 0.256 | 0.292 | 0.261 | 0.265 | 0.299 | |||
| 336 | 0.296 | 0.296 | 0.272 | 0.335 | 0.285 | 0.336 | 0.306 | 0.330 | 0.280 | 0.370 | 0.351 | ||||
| 720 | 0.354 | 0.347 | 0.358 | 0.398 | 0.418 | 0.351 | 0.388 | 0.356 | 0.365 | 0.359 | 0.414 | 0.383 | |||
| Avg | 0.258 | 0.258 | 0.278 | 0.315 | 0.268 | 0.321 | 0.280 | 0.309 | 0.287 | 0.314 | 0.322 | ||||
表3 不同方法在7个数据集上的预测结果
Tab. 3 Prediction results of different methods on 7 datasets
| 数据集 | 预测长度 | SFHD | iTransformer | Crossformer | MICN | CrossTimeNet | TimesNet | SimMTM | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| ETTh1 | 96 | 0.369 | 0.400 | 0.386 | 0.405 | 0.423 | 0.448 | 0.426 | 0.446 | 0.456 | 0.465 | 0.546 | 0.497 | ||
| 192 | 0.411 | 0.427 | 0.441 | 0.436 | 0.471 | 0.474 | 0.454 | 0.464 | 0.495 | 0.484 | 0.568 | 0.511 | |||
| 336 | 0.398 | 0.429 | 0.570 | 0.546 | 0.493 | 0.487 | 0.513 | 0.496 | 0.491 | 0.469 | 0.562 | 0.523 | |||
| 720 | 0.466 | 0.479 | 0.653 | 0.621 | 0.526 | 0.526 | 0.540 | 0.533 | 0.521 | 0.500 | 0.720 | 0.609 | |||
| Avg | 0.411 | 0.434 | 0.529 | 0.522 | 0.475 | 0.480 | 0.501 | 0.495 | 0.458 | 0.450 | 0.599 | 0.535 | |||
| ETTh2 | 96 | 0.258 | 0.328 | 0.745 | 0.584 | 0.372 | 0.424 | 0.359 | 0.405 | 0.340 | 0.374 | 0.395 | 0.420 | ||
| 192 | 0.309 | 0.363 | 0.380 | 0.877 | 0.656 | 0.492 | 0.492 | 0.417 | 0.402 | 0.414 | 0.469 | 0.454 | |||
| 336 | 0.310 | 0.371 | 0.428 | 0.432 | 1.043 | 0.731 | 0.607 | 0.555 | 0.452 | 0.452 | 0.464 | 0.463 | |||
| 720 | 0.399 | 0.440 | 1.104 | 0.763 | 0.824 | 0.655 | 0.454 | 0.462 | 0.468 | 0.488 | 0.484 | ||||
| Avg | 0.319 | 0.376 | 0.942 | 0.684 | 0.574 | 0.531 | 0.384 | 0.424 | 0.414 | 0.427 | 0.454 | 0.455 | |||
| ETTm1 | 96 | 0.286 | 0.343 | 0.404 | 0.426 | 0.365 | 0.387 | 0.343 | 0.382 | 0.338 | 0.375 | 0.461 | 0.442 | ||
| 192 | 0.323 | 0.368 | 0.377 | 0.391 | 0.450 | 0.451 | 0.403 | 0.408 | 0.405 | 0.374 | 0.469 | 0.451 | |||
| 336 | 0.349 | 0.385 | 0.426 | 0.420 | 0.532 | 0.515 | 0.436 | 0.431 | 0.420 | 0.418 | 0.502 | 0.473 | |||
| 720 | 0.399 | 0.417 | 0.491 | 0.459 | 0.666 | 0.589 | 0.489 | 0.462 | 0.464 | 0.478 | 0.542 | 0.510 | |||
| Avg | 0.339 | 0.378 | 0.407 | 0.410 | 0.513 | 0.495 | 0.423 | 0.422 | 0.403 | 0.417 | 0.494 | 0.469 | |||
| ETTm2 | 96 | 0.169 | 0.259 | 0.287 | 0.366 | 0.197 | 0.296 | 0.208 | 0.297 | 0.187 | 0.267 | 0.230 | 0.302 | ||
| 192 | 0.228 | 0.300 | 0.250 | 0.414 | 0.492 | 0.284 | 0.361 | 0.259 | 0.328 | 0.311 | 0.357 | ||||
| 336 | 0.279 | 0.333 | 0.597 | 0.542 | 0.381 | 0.429 | 0.317 | 0.361 | 0.321 | 0.351 | 0.421 | 0.421 | |||
| 720 | 0.355 | 0.382 | 0.412 | 0.407 | 1.730 | 1.042 | 0.549 | 0.522 | 0.404 | 0.408 | 0.569 | 0.492 | |||
| Avg | 0.258 | 0.319 | 0.757 | 0.611 | 0.353 | 0.402 | 0.293 | 0.348 | 0.291 | 0.333 | 0.383 | 0.393 | |||
| Exchange_rate | 96 | 0.080 | 0.197 | 0.256 | 0.367 | 0.148 | 0.278 | 0.244 | 0.367 | 0.107 | 0.234 | 0.223 | 0.341 | ||
| 192 | 0.170 | 0.292 | 0.470 | 0.509 | 0.271 | 0.315 | 0.328 | 0.417 | 0.226 | 0.344 | 0.344 | 0.431 | |||
| 336 | 0.317 | 0.406 | 1.268 | 0.883 | 0.460 | 0.427 | 0.605 | 0.583 | 0.367 | 0.448 | 0.515 | 0.537 | |||
| 720 | 0.846 | 0.691 | 1.767 | 1.068 | 1.195 | 0.695 | 1.194 | 0.832 | 0.964 | 0.746 | 1.192 | 0.829 | |||
| Avg | 0.353 | 0.397 | 0.940 | 0.707 | 0.519 | 0.429 | 0.593 | 0.550 | 0.416 | 0.443 | 0.569 | 0.535 | |||
| ILI | 24 | 0.867 | 1.985 | 0.998 | 3.041 | 1.186 | 3.029 | 1.180 | 3.090 | 1.235 | 2.317 | 3.102 | 1.240 | ||
| 36 | 0.885 | 2.302 | 1.003 | 3.406 | 1.232 | 2.507 | 1.013 | 2.566 | 1.068 | 1.972 | 2.587 | 1.075 | |||
| 48 | 1.797 | 0.848 | 0.954 | 3.459 | 1.221 | 2.423 | 1.012 | 2.403 | 1.189 | 2.238 | 2.453 | 1.213 | |||
| 60 | 1.643 | 0.812 | 2.117 | 1.007 | 3.640 | 1.305 | 2.653 | 1.085 | 2.673 | 1.081 | 2.723 | 1.105 | |||
| Avg | 1.868 | 0.853 | 0.991 | 3.387 | 1.236 | 2.653 | 1.073 | 2.683 | 1.143 | 2.139 | 2.716 | 1.158 | |||
| Weather | 96 | 0.175 | 0.214 | 0.174 | 0.214 | 0.158 | 0.230 | 0.198 | 0.261 | 0.204 | 0.258 | 0.205 | 0.256 | ||
| 192 | 0.224 | 0.221 | 0.254 | 0.206 | 0.277 | 0.239 | 0.299 | 0.256 | 0.292 | 0.261 | 0.265 | 0.299 | |||
| 336 | 0.296 | 0.296 | 0.272 | 0.335 | 0.285 | 0.336 | 0.306 | 0.330 | 0.280 | 0.370 | 0.351 | ||||
| 720 | 0.354 | 0.347 | 0.358 | 0.398 | 0.418 | 0.351 | 0.388 | 0.356 | 0.365 | 0.359 | 0.414 | 0.383 | |||
| Avg | 0.258 | 0.258 | 0.278 | 0.315 | 0.268 | 0.321 | 0.280 | 0.309 | 0.287 | 0.314 | 0.322 | ||||
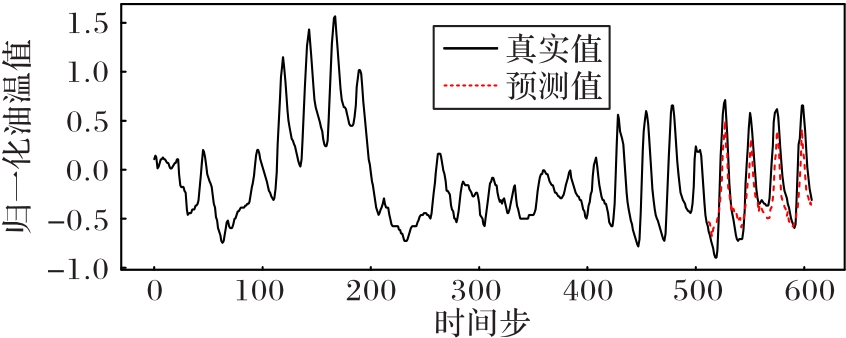
图5 ETTh2数据集上的预测结果可视化
Fig. 5 Visualization of prediction results on ETTh2 dataset
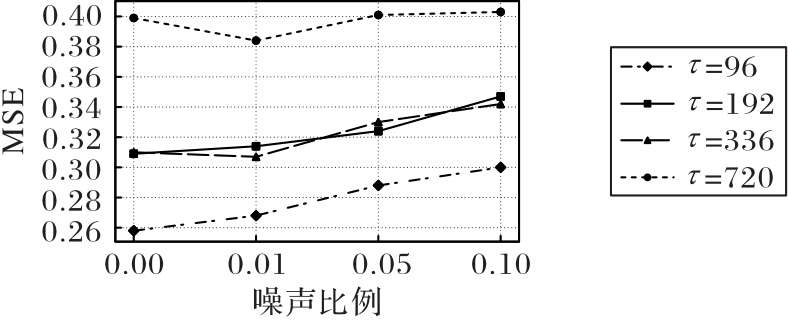
图6 高频噪声敏感性测试结果
Fig. 6 Test results of high frequency noise sensitivity
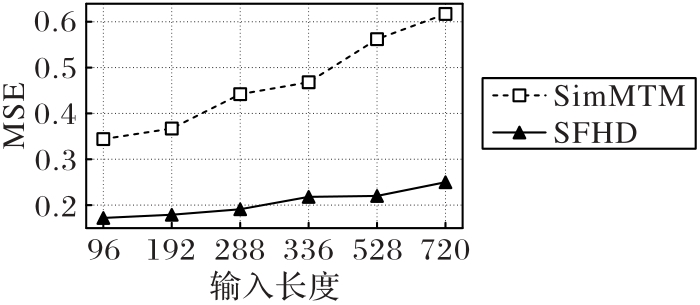
图7 长期依赖的捕获性能对比
Fig. 7 Comparison of long-term dependency capture performance
| 任务变量 | ETTm1(τ=96) | ILI(τ=36) | ||
|---|---|---|---|---|
| MSE | MAE | MSE | MAE | |
| R-SFB | 0.288 | 0.345 | 2.253 | 0.931 |
| R-HDB | 0.306 | 0.352 | 2.422 | 0.990 |
| R-pretraining | 0.290 | 0.347 | 2.166 | 0.902 |
| SFHD | 0.286 | 0.343 | 2.132 | 0.890 |
表4 消融实验中的预测结果
Tab. 4 Prediction results in ablation experiments
| 任务变量 | ETTm1(τ=96) | ILI(τ=36) | ||
|---|---|---|---|---|
| MSE | MAE | MSE | MAE | |
| R-SFB | 0.288 | 0.345 | 2.253 | 0.931 |
| R-HDB | 0.306 | 0.352 | 2.422 | 0.990 |
| R-pretraining | 0.290 | 0.347 | 2.166 | 0.902 |
| SFHD | 0.286 | 0.343 | 2.132 | 0.890 |
| [1] | 叶力硕,何志学. 融合时频特征的多粒度时间序列对比学习方法[J].计算机科学, 2025, 52(1): 170-182. |
| YE L S, HE Z X. Multi-granularity time series contrastive learning method incorporating time-frequency features[J]. Computer Science, 2025, 52(1): 170-182. | |
| [2] | ELDELE E, RAGAB M, CHEN Z, et al. TSLANet: rethinking transformers for time series representation learning[C]// Proceedings of the 41st International Conference on Machine Learning. New York: JMLR.org, 2024: 12409-12428. |
| [3] | WANG Y, WU M, LI X, et al. Multivariate time-series representation learning via hierarchical correlation pooling boosted graph neural network[J]. IEEE Transactions on Artificial Intelligence, 2024, 5(1): 321-333. |
| [4] | WU H, HU T, LIU Y, et al. TimesNet: temporal 2D-variation modeling for general time series analysis[EB/OL]. [2025-03-07].. |
| [5] | ZHONG S, SONG S, ZHOU W, et al. A multi-scale decomposition MLP-Mixer for time series analysis[J]. Proceedings of the VLDB Endowment, 2024, 17(7): 1723-1736. |
| [6] | CHENG M, TAO X, LIU Q, et al. Cross-domain pre-training with language models for transferable time series representations[C]// Proceedings of the 18th ACM International Conference on Web Search and Data Mining. New York: ACM, 2025: 175-183. |
| [7] | DONG J, WU H, ZHANG H, et al. SimMTM: a simple pre-training framework for masked time-series modeling[C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 29996-30025. |
| [8] | ABOUSSALAH A M, KWON M, PATEL R G, et al. Recursive time series data augmentation[EB/OL]. [2025-03-07].. |
| [9] | FANG Y, REN K, SHAN C, et al. Learning decomposed spatial relations for multi-variate time-series modeling[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 7530-7538. |
| [10] | ZHANG Q, YU C, WANG H, et al. FLDmamba: integrating Fourier and Laplace transform decomposition with Mamba for enhanced time series prediction[EB/OL]. [2025-08-07].. |
| [11] | 邓攀,刘俊廷,王晓,等. STCTN:一种基于时域偏倚校正与空域因果传递的时空因果表示学习方法[J]. 计算机学报, 2023, 46(12): 2535-2550. |
| DENG P, LIU J T, WANG X, et al. STCTN: a spatio-temporal causal representation learning method based on temporal bias adjustment and spatial causal transition[J]. Chinese Journal of Computers, 2023, 46(12): 2535-2550. | |
| [12] | ZERVEAS G, JAYARAMAN S, PATEL D, et al. A Transformer-based framework for multivariate time series representation learning[C]// Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2021: 2114-2124. |
| [13] | CHEN W, YE J, ZHAO C, et al. MFFCNN: multi-scale fractional Fourier transform convolutional neural network for multivariate time series forecasting[J]. The Journal of Supercomputing, 2025, 81(2): No.416. |
| [14] | YUE Z, WANG Y, DUAN J, et al . T S2Vec: towards universal representation of time series[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 8980-8987. |
| [15] | RAO Y, ZHAO W, ZHU Z, et al. Global filter networks for image classification[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 980-993. |
| [16] | CHUNG Y A, ZHANG Y, HAN W, et al. w2v-BERT: Combining contrastive learning and masked language modeling for self-supervised speech pre-training[C]// Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop. Piscataway: IEEE, 2021: 244-250. |
| [17] | FAN J, ZHANG K, HUANG Y, et al. Parallel spatio-temporal attention-based TCN for multivariate time series prediction[J]. Neural Computing and Applications, 2023, 35(18): 13109-13118. |
| [18] | 李兆玺,刘红岩. 融合全局和序列特征的多变量时间序列预测方法[J]. 计算机学报, 2023, 46(1): 70-84. |
| LI Z X, LIU H Y. Combining global and sequential patterns for multivariate time series forecasting[J]. Chinese Journal of Computers, 2023, 46(1): 70-84. | |
| [19] | ZHOU H, ZHANG S, PENG J, et al. Informer: beyond efficient Transformer for long sequence time-series forecasting[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 11106-11115. |
| [20] | LIU Y, HU T, ZHANG H, et al. iTransformer: inverted Transformers are effective for time series forecasting[EB/OL]. [2025-03-07].. |
| [21] | ZHANG Y, YAN J. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting[EB/OL]. [2025-03-07].. |
| [22] | WANG H, PENG J, HUANG F, et al. MICN: multi-scale local and global context modeling for long-term series forecasting[EB/OL]. [2025-03-07].. |
| [1] | 索逸凡, 刘松华, 郝秋智. 基于高阶特征聚合的时间序列异常检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1131-1138. |
| [2] | 尹春勇, 张不凡. 基于多尺度的多变量时间序列异常检测模型[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 790-797. |
| [3] | 于巧, 黄子睿, 程圣懿, 祝义, 张淑涛. 基于边权重的软件漏洞检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 518-527. |
| [4] | 魏涵玥, 郭晨娟, 梅杰源, 田锦东, 陈鹏, 徐榕荟, 杨彬. 融合时频特征与混合文本的多模态股票预测框架MATCH[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 427-436. |
| [5] | 吴俊衡, 王晓东, 何启学. 基于统计分布感知与频域双通道融合的时序预测模型[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 113-123. |
| [6] | 李玟, 李开荣, 杨凯. 基于数据增强的子图感知对比学习[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 1-9. |
| [7] | 程梓洋, 黄瑞章, 薛菁菁. 深度演化主题聚类模型[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 85-94. |
| [8] | 曲鹏欢, 魏巍, 闫京, 王锋. 基于双补全的不完整多视图度量学习[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2755-2763. |
| [9] | 刘超, 余岩化. 融合降噪策略与多视图对比学习的知识感知推荐模型[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2827-2837. |
| [10] | 王翔, 陈志祥, 毛国君. 融合局部和全局相关性的多变量时间序列预测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2806-2816. |
| [11] | 冯兴杰, 卞兴鹏, 冯小荣, 王兴隆. 基于扩散模型的增量式时间序列缺失值填充算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2582-2591. |
| [12] | 王义, 马应龙. 基于项图动态适应性生成的多任务社交项推荐方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2592-2599. |
| [13] | 谢劲, 褚苏荣, 强彦, 赵涓涓, 张华, 高勇. 用于胸片中硬负样本识别的双支分布一致性对比学习模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2369-2377. |
| [14] | 王慧斌, 胡展傲, 胡节, 徐袁伟, 文博. 基于分段注意力机制的时间序列预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2262-2268. |
| [15] | 闫龙博, 毛文涛, 仲志鸿, 范黎林. 面向城市排水管网缺陷诊断的鲁棒无监督多任务异常检测方法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1833-1840. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||