《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (5): 1416-1423.DOI: 10.11772/j.issn.1001-9081.2025050581
• 人工智能 • 上一篇
张棣锐1, 林佳瑜2( ), 梁祖红1,3
), 梁祖红1,3
Dirui ZHANG1, Jiayu LIN2(), Zuhong LIANG1,3
摘要:
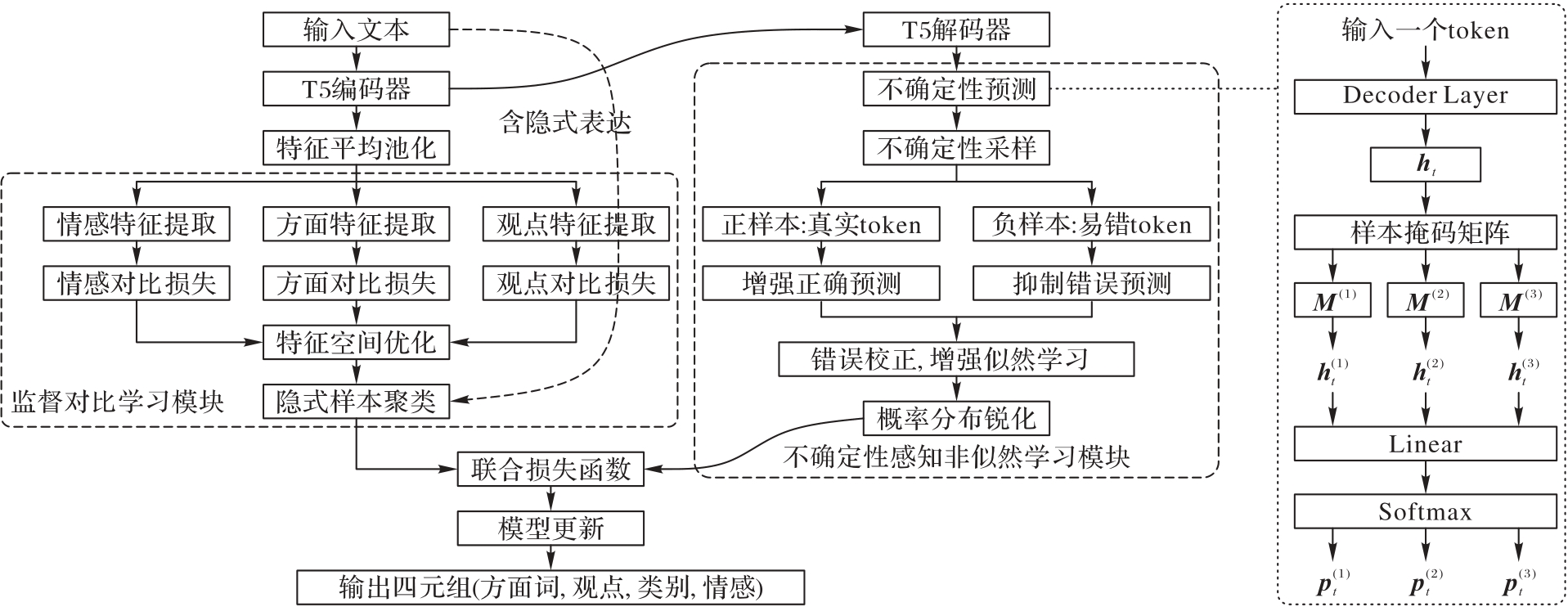
现有模型在方面情感四元组预测(ASQP)任务中仍面临着多重挑战:它们在处理隐式情感表达(如隐含的方面或观点)时存在困难,隐式情感表达缺乏明确的词汇线索,导致模型难以准确捕捉情感倾向;只有当四元组预测的所有预测元素都与正确元素完全匹配时,模型才被认为是准确的,而模型会生成易混淆近义词或同义词,导致四元组预测完全错误。而且现有模型致力于提高预测正确词语的概率,忽略了抑制易混淆词的概率;同时,现有模型采用的交叉熵损失使模型对错误预测过于自信,缺乏对不确定性的建模,难以主动抑制高风险错误。这些问题限制了现有模型在基于方面的情感分析(ABSA)任务上的表现。为了解决这些问题,提出一种基于不确定性感知非似然学习的监督对比生成式情感分析方法(SCUAUL)。首先,采用监督对比学习,通过对比损失拉近同类样本(如相同情感极性)的语义空间距离,增强模型对输入数据的关键特征(如情感极性、隐式方面等)的区分能力;其次,利用蒙特卡洛Dropout(MC Dropout)捕捉模型内在不确定性,发现易混淆词,通过边缘化非似然学习动态抑制易混淆词汇的生成概率,保持正确词汇的生成概率,并结合最小熵约束平衡生成多样性与准确性。在Rest15和Rest16数据集上进行5次实验的平均结果显示,相较于次优模型AugABSA(data Augmentation by text generation for ABSA)和经典模型PARAPHRASE,SCUAUL的精确率分别提升了0.40、3.98和0.38、3.83个百分点,召回率分别提升了0.30、2.87和0.48、2.88个百分点,F1 score分别提升了0.35、3.43和0.42、3.37个百分点,验证了SCUAUL在ABSA任务上的有效性。
中图分类号: