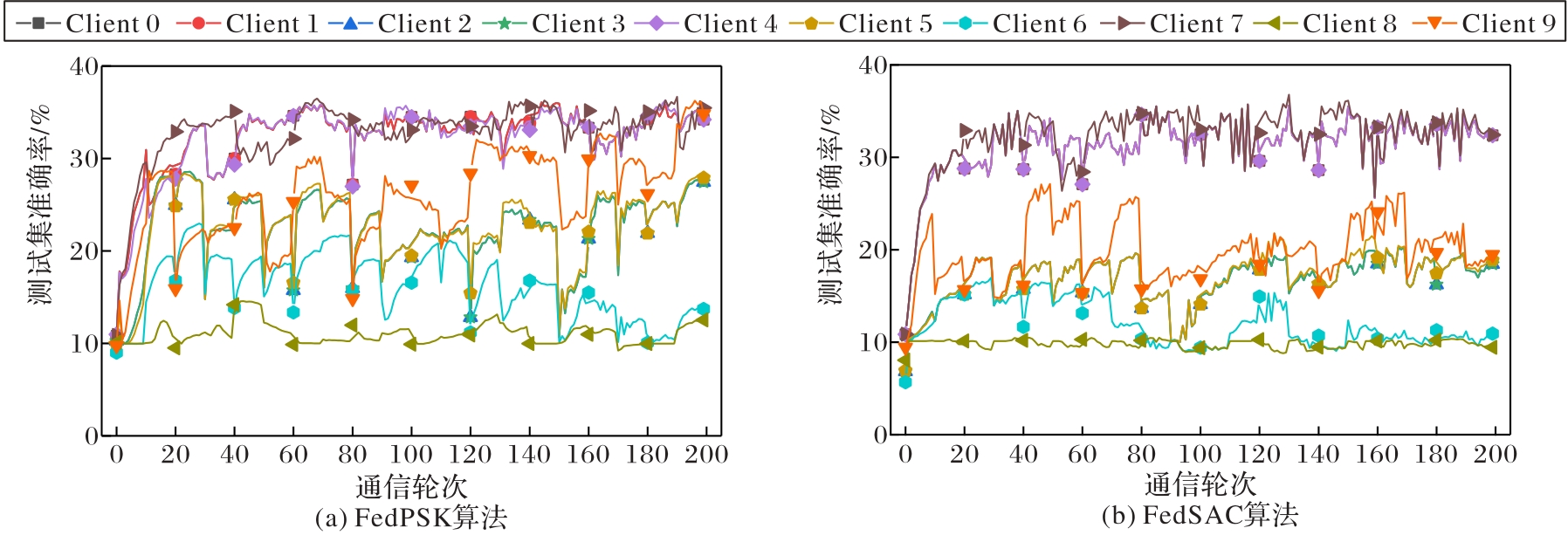
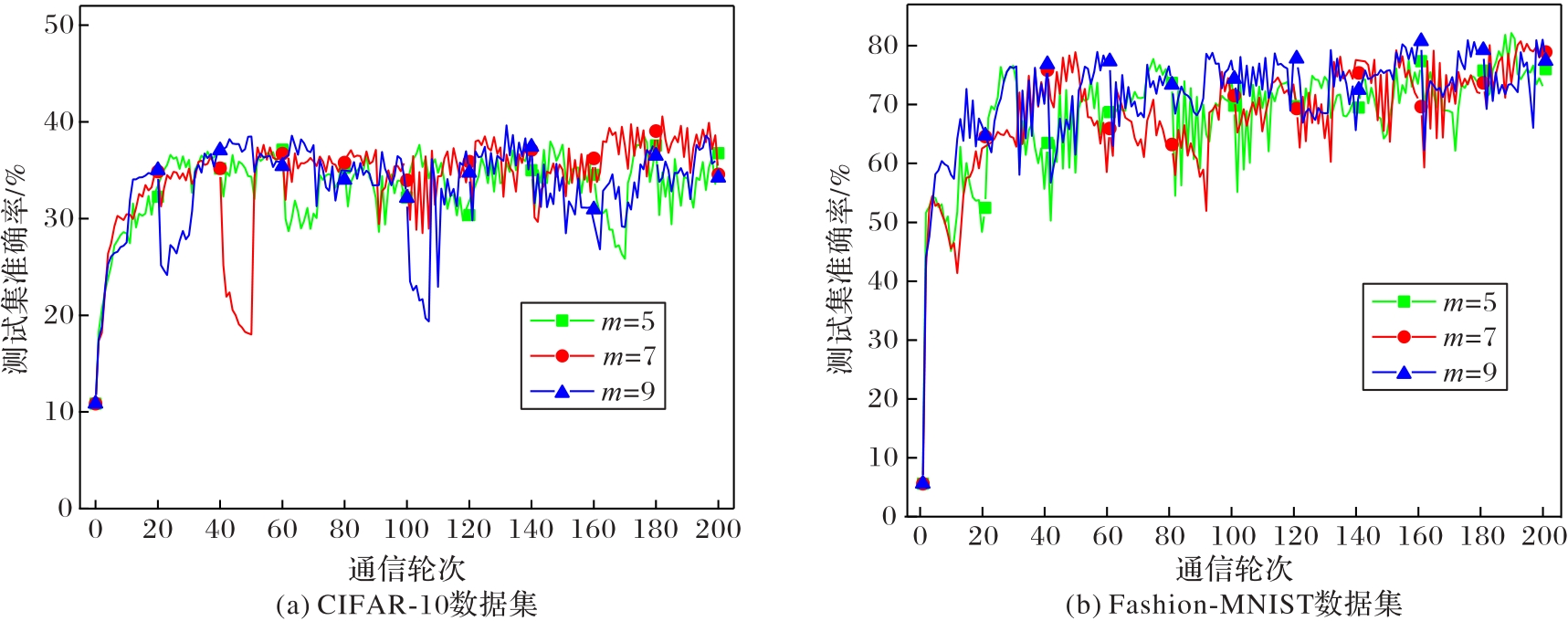
| [1] |
McMAHAN B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[C]// Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2017: 1273-1282.
|
| [2] |
PAN Z, LI C, YU F, et al. FedLF: layer-wise fair federated learning[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 14527-14535.
|
| [3] |
LYU L, XU X, WANG Q, et al. Collaborative fairness in federated learning[M]// YANG Q, FAN L, YU H. Federated learning: privacy and incentive, LNCS 12500. Cham: Springer, 2020: 189-204.
|
| [4] |
WANG Z, WANG Z, LYU L, et al. FedSAC: dynamic submodel allocation for collaborative fairness in federated learning[C]// Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2024: 3299-3310.
|
| [5] |
YU H, LIU Z, LIU Y, et al. A fairness-aware incentive scheme for federated learning[C]// Proceedings of the 2020 AAAI/ACM Conference on AI, Ethics, and Society. New York: ACM, 2020: 393-399.
|
| [6] |
SHI Y, YU H, LEUNG C. Towards fairness-aware federated learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(9): 11922-11938.
|
| [7] |
ZHANG J, LI C, ROBLES-KELLY A, et al. Hierarchically fair federated learning[EB/OL]. [2024-11-11]..
|
| [8] |
LYU L, YU J, NANDAKUMAR K, et al. Towards fair and privacy-preserving federated deep models[J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 31(11): 2524-2541.
|
| [9] |
KANG J, XIONG Z, NIYATO D, et al. Incentive design for efficient federated learning in mobile networks: a contract theory approach[C]// Proceedings of the 2019 IEEE VTS Asia Pacific Wireless Communications Symposium. Piscataway: IEEE, 2019: 1-5.
|
| [10] |
COHEN A I. Contract theory[M]// CLAEYS G. Encyclopedia of modern political thought. Thousand Oaks, CA: CQ Press, 2013: 191-194.
|
| [11] |
SARIKAYA Y, ERCETIN O. Motivating workers in federated learning: a Stackelberg game perspective[J]. IEEE Networking Letters, 2020, 2(1): 23-27.
|
| [12] |
FAN Z, FANG H, ZHOU Z, et al. Fair and efficient contribution valuation for vertical federated learning[EB/OL]. [2024-10-12]..
|
| [13] |
CHENG Q, QU S, LEE J. SHARPNN: shapley value regularized tabular neural network[EB/OL]. [2024-11-16]..
|
| [14] |
XU X, LYU L, MA X, et al. Gradient driven rewards to guarantee fairness in collaborative machine learning[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 16104-16117.
|
| [15] |
TASTAN N, FARES S, AREMU T, et al. Redefining contributions: shapley-driven federated learning [C]// Proceedings of the 33rd International Joint Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 5009-5017.
|
| [16] |
WAN T, DENG X, LIAO W, et al. Enhancing fairness in federated learning: a contribution‑based differentiated model approach [J]. International Journal of Intelligent Systems, 2023, 2023: No.6692995.
|
| [17] |
TASTAN N, HORVATH S, NANDAKUMAR K. CYCle: choosing your collaborators wisely to enhance collaborative fairness in decentralized learning[EB/OL]. [2025-02-08]..
|
| [18] |
WANG Z, PENG Z, FAN X, et al. FedAVE: adaptive data value evaluation framework for collaborative fairness in federated learning[J]. Neurocomputing, 2024, 574: No.127227.
|
| [19] |
RODGERS J l, NICEWANDER W A. Thirteen ways to look at the correlation coefficient[J]. The American Statistician, 1988, 42(1): 59-66.
|
| [20] |
LI T, SAHU A K, TALWALKAR A, et al. Federated learning: challenges, methods, and future directions[J]. IEEE Signal Processing Magazine, 2020, 37(3): 50-60.
|
| [21] |
浙江君同智能科技有限责任公司. 基于神经元激活值聚类的纵向联邦学习后门防御法: 202210146719.0[P]. 2022-03-18.
|
|
Zhejiang Juntong Intelligent Technology Company Limited. Longitudinal federated learning backdoor defense based on neuron activation value clustering: 202210146719.0 [P]. 2023-03-18.
|
| [22] |
HARTIGAN J A, WONG M A. Algorithm AS 136: a K-means clustering algorithm[J]. Journal of the Royal Statistical Society. Series C (Applied Statistics), 1979, 28(1): 100-108.
|
| [23] |
MOLCHANOV P, MALLYA A, TYREE S, et al. Importance estimation for neural network pruning[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 11256-11264.
|
| [24] |
KRIZHEVSKY A. Learning multiple layers of features from tiny images[R/OL]. [2024-11-25]..
|
| [25] |
XIAO H, RASUL K, VOLLGRAF R. Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms [EB/OL]. [2024-11-25]..
|
| [26] |
ZHANG J, LIU Y, HUA Y, et al. PFLlib: personalized federated learning algorithm library[J]. Journal of Machine Learning Research, 2025, 26: 1-10.
|
| [27] |
YU Y, WEI A, KARIMIREDDY S P, et al. TCT: convexifying federated learning using bootstrapped neural tangent kernels[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 30882-30897.
|
| [28] |
LI T, SAHU A K, ZAHEER M, et al. Federated optimization in heterogeneous networks [J]. Proceedings of Machine Learning and Systems, 2020, 2: 429-450.
|


 ), 菅银龙1,2,3, 钟琪1,2,3, 张镇博1,2,3
), 菅银龙1,2,3, 钟琪1,2,3, 张镇博1,2,3