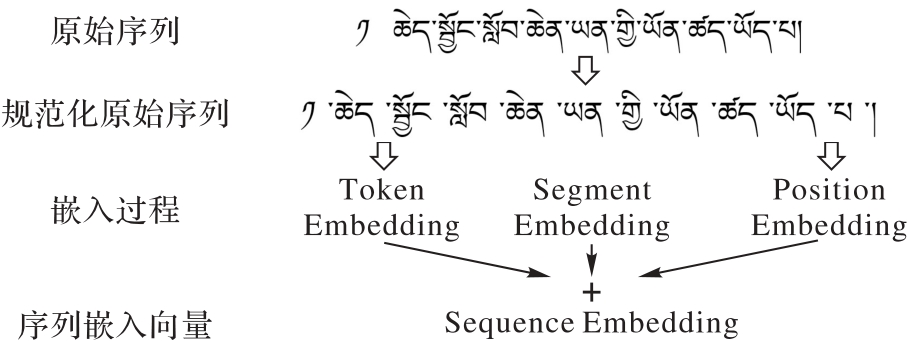
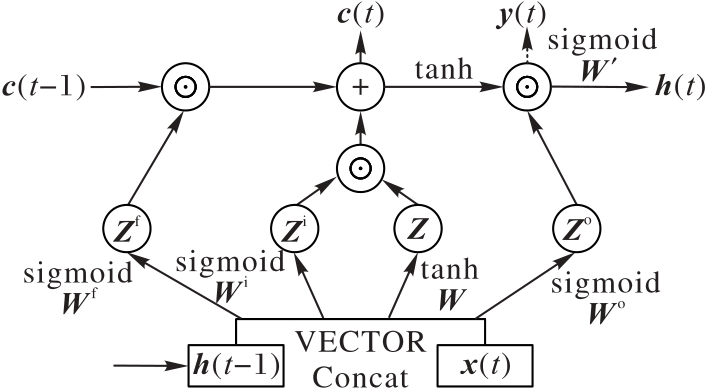
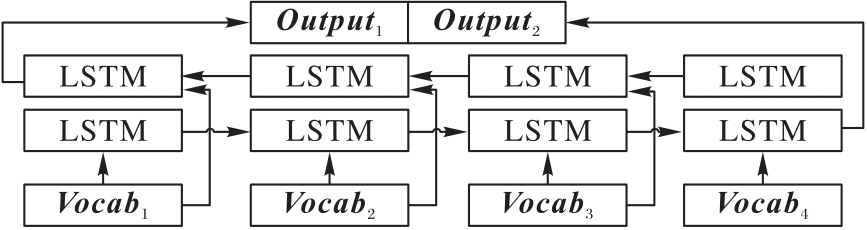
| 1 |
陈玉忠,李保利,俞士汶,等. 基于格助词和接续特征的藏文自动分词方案[J]. 语言文字应用, 2003(1):75-82.
|
|
CHEN Y Z, LI B L, YU S W, et al. An automatic word separation scheme for Tibetan based on case-auxiliary words and continuous features[J]. Applied Linguistics, 2003(1):75-82.
|
| 2 |
陈玉忠,李保利,俞士汶. 藏文自动分词系统的设计与实现[J]. 中文信息学报, 2003, 17(3):15-20, 65.
|
|
CHEN Y Z, LI B L, YU S W. The design and implementation of a Tibetan word segmentation system[J]. Journal of Chinese Information Processing, 2003, 17(3):15-20, 65.
|
| 3 |
祁坤钰. 信息处理用藏文自动分词研究[J]. 西北民族大学学报(哲学社会科学版), 2006(4):92-97.
|
|
QI K Y. On Tibetan automatic participate research with the aid of information treatment[J]. Journal of Northwest University for Nationalities (Philosophy and Social Science), 2006(4):92-97.
|
| 4 |
才智杰. 藏文自动分词系统中紧缩词的识别[J]. 中文信息学报, 2009, 23(1):35-37, 43.
|
|
CAI Z J. Identification of abbreviated word in Tibetan word segmentation[J]. Journal of Chinese Information Processing, 2009, 23(1):35-37, 43.
|
| 5 |
才智杰. 班智达藏文自动分词系统的设计与实现[J]. 青海师范大学民族师范学院学报, 2010, 21(2):75-77.
|
|
CAI Z J. Design and realization of “Banzhida” Tibetan automatic word segmentation system[J]. Journal of Minorities Teachers College of Qinghai Teachers University, 2010, 21(2):75-77.
|
| 6 |
才智杰,才让卓玛. 藏文自动分词系统的设计[J].计算机工程与科学, 2011, 33(5):151-154.
|
|
CAI Z J, CAI R Z M. Design of a Tibetan word segmentation system[J]. Computer Engineering and Science, 2011, 33(5):151-154.
|
| 7 |
刘汇丹,诺明花,赵维纳,等. SegT:一个实用的藏文分词系统[J]. 中文信息学报, 2012, 26(1):97-103.
|
|
LIU H D, NUO M H, ZHAO W N, et al. SegT: a practical Tibetan word segmentation system[J]. Journal of Chinese Information Processing, 2012, 26(1):97-103.
|
| 8 |
史晓东,卢亚军. 央金藏文分词系统[J]. 中文信息学报, 2011, 25(4):54-56.
|
|
SHI X D, LU Y J. A Tibetan segmentation system — Yangjin[J]. Journal of Chinese Information Processing, 2011, 25(4):54-56.
|
| 9 |
李亚超. 基于条件随机场的藏文分词与命名实体识别研究[D]. 兰州:西北民族大学, 2013.
|
|
LI Y C. Study on the Tibetan word segmentation and named entity recognition with conditional random fields[D]. Lanzhou: Northwest Minzu University, 2013.
|
| 10 |
李亚超,江静,加羊吉,等. TIP-LAS:一个开源的藏文分词词性标注系统[J]. 中文信息学报, 2015, 29(6):203-207.
|
|
LI Y C, JIANG J, JIA Y J, et al. TIP-LAS: an open source toolkit for Tibetan word segmentation and POS tagging[J]. Journal of Chinese Information Processing, 2015, 29(6):203-207.
|
| 11 |
李博涵,刘汇丹,龙从军,等. 基于深度学习的藏文分词方法[J]. 计算机工程与设计, 2018, 39(1):194-198.
|
|
LI B H, LIU H D, LONG C J, et al. Tibetan word segmentation based on deep learning[J]. Computer Engineering and Design, 2018, 39(1):194-198.
|
| 12 |
桑杰端珠,才让加. 神经网络藏文分词方法研究[J]. 青海科技, 2018, 25(6):15-21.
|
|
SANGJIE D, CAI R. Research on neural network Tibetan word segmentation method[J]. Qinghai Science and Technology, 2018, 25(6):15-21.
|
| 13 |
电子科技大学. 基于Transformer-CRF的藏文分词方法: 202111520289.6[P]. 2022-04-12.
|
|
University of Electronic Science and Technology of China. Transformer-CRF based segmentation method for Tibetan language: 202111520289.6[P]. 2022-04-12.
|
| 14 |
色差甲,桑杰端珠,才让加,等. 一种基于预训练模型的藏文分词方法[J]. 中文信息学报, 2023, 37(12):70-75.
|
|
SE C, SANGJIE D, CAI R, et al. A Tibetan word segmentation method based on pre-training model[J]. Journal of Chinese Information Processing, 2023, 37(12):70-75.
|
| 15 |
YANG J, TASHI N, DENG S, et al. Exploration on the effect of text preprocessing based on inflection morphology and attachment morphology restoration in Tibetan text classification[C]// Proceedings of the IEEE 4th International Conference on Pattern Recognition and Machine Learning. Piscataway: IEEE, 2023: 134-140.
|
| 16 |
LIU S, DENG J, SUN Y, et al. TiBERT: Tibetan pre-trained language model[C]// Proceedings of the 2022 IEEE International Conference on Systems, Man, and Cybernetics. Piscataway: IEEE, 2022: 2956-2961.
|
| 17 |
SIAMI-NAMINI S, TAVAKOLI N, NAMIN A S. The performance of LSTM and BiLSTM in forecasting time series[C]// Proceedings of the 2019 IEEE International Conference on Big Data. Piscataway: IEEE, 2019: 3285-3292.
|
| 18 |
LAFFERTY J D, McCALLUM A, PEREIRA F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data[C]// Proceedings of the 18th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 2001: 282-289.
|
| 19 |
BA J L, KIROS J R, HINTON G E. Layer normalization[EB/OL]. [2024-03-10]..
|
| 20 |
高定国,杨晓龙,杨宇帆,等. MLWS2021藏文分词评测报告[J]. 高原科学研究, 2022, 6(1):82-89.
|
|
GAO D G, YANG X L, YANG Y F, et al. Study on the evaluation of Tibetan words segmentation of MLWS2021[J]. Plateau Science Research, 2022, 6(1):82-89.
|


 ), 仁青东主1,2, 祁晋东1, 才让东知1,2
), 仁青东主1,2, 祁晋东1, 才让东知1,2