


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (1): 207-215.DOI: 10.11772/j.issn.1001-9081.2025010074
黄舒雯1, 郭柯宇1, 宋翔宇2( ), 韩锋1, 孙士杰2, 宋焕生1
), 韩锋1, 孙士杰2, 宋焕生1
收稿日期:2025-01-20
修回日期:2025-03-05
接受日期:2025-03-12
发布日期:2026-01-10
出版日期:2026-01-10
通讯作者:
宋翔宇
作者简介:黄舒雯(2001—),女,广西桂平人,硕士研究生, CCF会员,主要研究方向:计算机视觉、三维视觉定位基金资助:
Shuwen HUANG1, Keyu GUO1, Xiangyu SONG2(), Feng HAN1, Shijie SUN2, Huansheng SONG1
Received:2025-01-20
Revised:2025-03-05
Accepted:2025-03-12
Online:2026-01-10
Published:2026-01-10
Contact:
Xiangyu SONG
About author:HUANG Shuwen, born in 2001, M. S. candidate. Her research interests include computer vision, 3D visual grounding.Supported by:摘要:
针对现有的三维视觉定位方法依赖昂贵传感器设备、系统成本高且在复杂多目标定位中准确度和鲁棒性不足的问题,提出一种基于单目图像的多目标三维视觉定位方法。该方法结合自然语言描述,在单个RGB图像中实现对多个三维目标的识别。为此,构建一个多目标视觉定位数据集Mmo3DRefer,并设计跨模态匹配网络TextVizNet。TextVizNet通过预训练的单目检测器生成目标的三维边界框,并借助信息融合模块与信息对齐模块实现视觉与语言信息的深度整合,进而实现文本指导下的多目标三维检测。与CORE-3DVG (Contextual Objects and RElations for 3D Visual Grounding)、3DVG-Transformer和Multi3DRefer (Multiple 3D object Referencing dataset and task)等5种方法对比的实验结果表明,与次优方法Multi3DRefer相比,TextVizNet在Mmo3DRefer数据集上的F1-score、精确度和召回率分别提升了8.92%、8.39%和9.57%,显著提升了复杂场景下基于文本的多目标定位精度,为自动驾驶和智能机器人等实际应用提供了有效支持。
中图分类号:
黄舒雯, 郭柯宇, 宋翔宇, 韩锋, 孙士杰, 宋焕生. 基于单目图像的多目标三维视觉定位方法[J]. 计算机应用, 2026, 46(1): 207-215.
Shuwen HUANG, Keyu GUO, Xiangyu SONG, Feng HAN, Shijie SUN, Huansheng SONG. Multi-target 3D visual grounding method based on monocular images[J]. Journal of Computer Applications, 2026, 46(1): 207-215.

图1 单目多目标三维视觉定位任务与其他任务的对比分析
Fig. 1 Comparative analysis of monocular multi-target 3D visual grounding task and other tasks
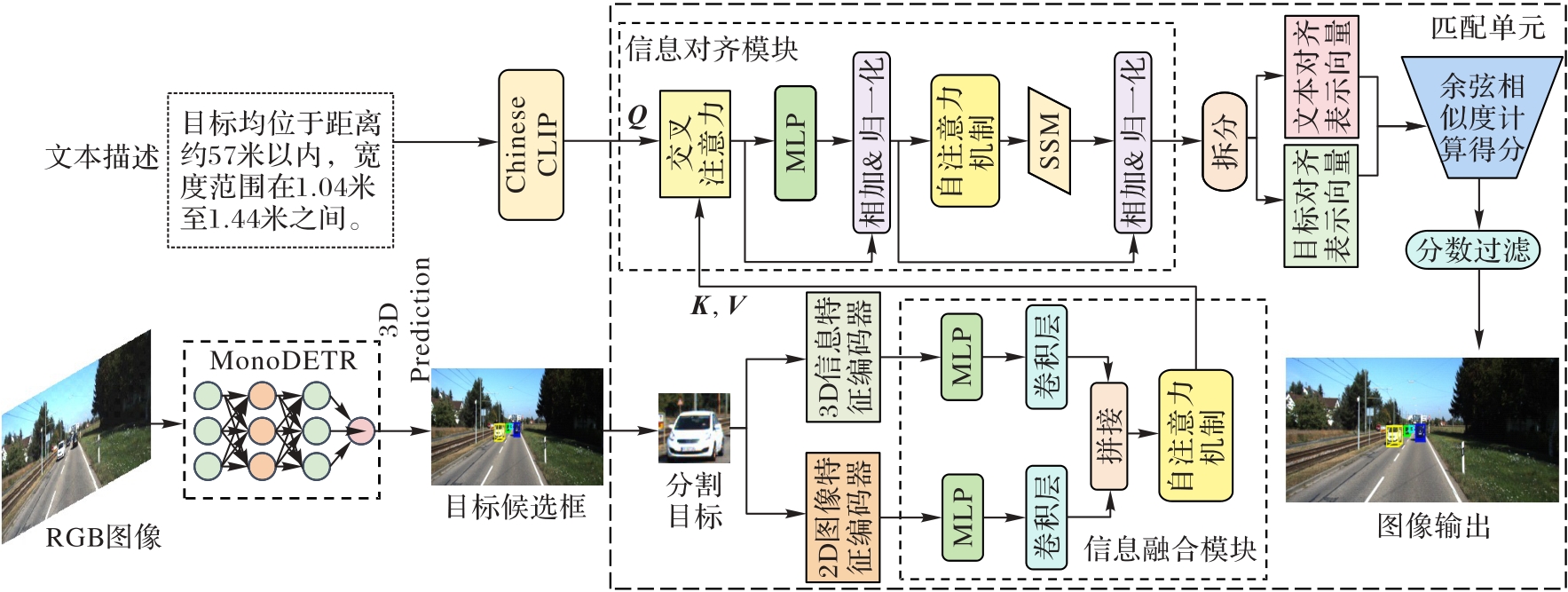
图2 TextVizNet整体框架
Fig. 2 Overall framework of TextVizNet
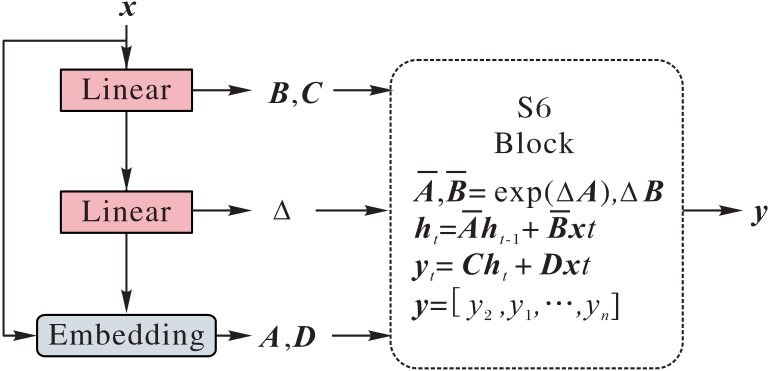
图3 SSM的结构
Fig. 3 Structure of SSM
| 数据集 | 样本数 | 表达数 | 范围/m | 视觉形式 | 标注类型 | 场景 | 目标类型 |
|---|---|---|---|---|---|---|---|
| ScanRefer | 11 046 | 51 583 | 10 | 点云图 | 3D框 | 室内 | 单目标 |
| Sr3D | 8 863 | 83 572 | 10 | 点云图 | 3D框 | 室内 | 单目标 |
| Nr3D | 5 879 | 41 503 | 10 | 点云图 | 3D框 | 室内 | 单目标 |
| SUNRefer | 7 699 | 38 495 | — | RGB-D图像 | 3D框 | 室内 | 单目标 |
| STRefer | 3 581 | 5 458 | 30 | 点云、RGB图像 | 3D框 | 室外 | 单目标 |
| Mono3DRefer | 8 228 | 41 140 | 102 | RGB | 2D/3D框 | 室外 | 单目标 |
| Mmo3DRefer | 12 763 | 6 075 | 103 | RGB | 2D/3D框 | 室外 | 多目标 |
表1 三维场景中视觉定位数据集的对比分析
Tab. 1 Comparison analysis of visual grounding datasets in 3D scenes
| 数据集 | 样本数 | 表达数 | 范围/m | 视觉形式 | 标注类型 | 场景 | 目标类型 |
|---|---|---|---|---|---|---|---|
| ScanRefer | 11 046 | 51 583 | 10 | 点云图 | 3D框 | 室内 | 单目标 |
| Sr3D | 8 863 | 83 572 | 10 | 点云图 | 3D框 | 室内 | 单目标 |
| Nr3D | 5 879 | 41 503 | 10 | 点云图 | 3D框 | 室内 | 单目标 |
| SUNRefer | 7 699 | 38 495 | — | RGB-D图像 | 3D框 | 室内 | 单目标 |
| STRefer | 3 581 | 5 458 | 30 | 点云、RGB图像 | 3D框 | 室外 | 单目标 |
| Mono3DRefer | 8 228 | 41 140 | 102 | RGB | 2D/3D框 | 室外 | 单目标 |
| Mmo3DRefer | 12 763 | 6 075 | 103 | RGB | 2D/3D框 | 室外 | 多目标 |
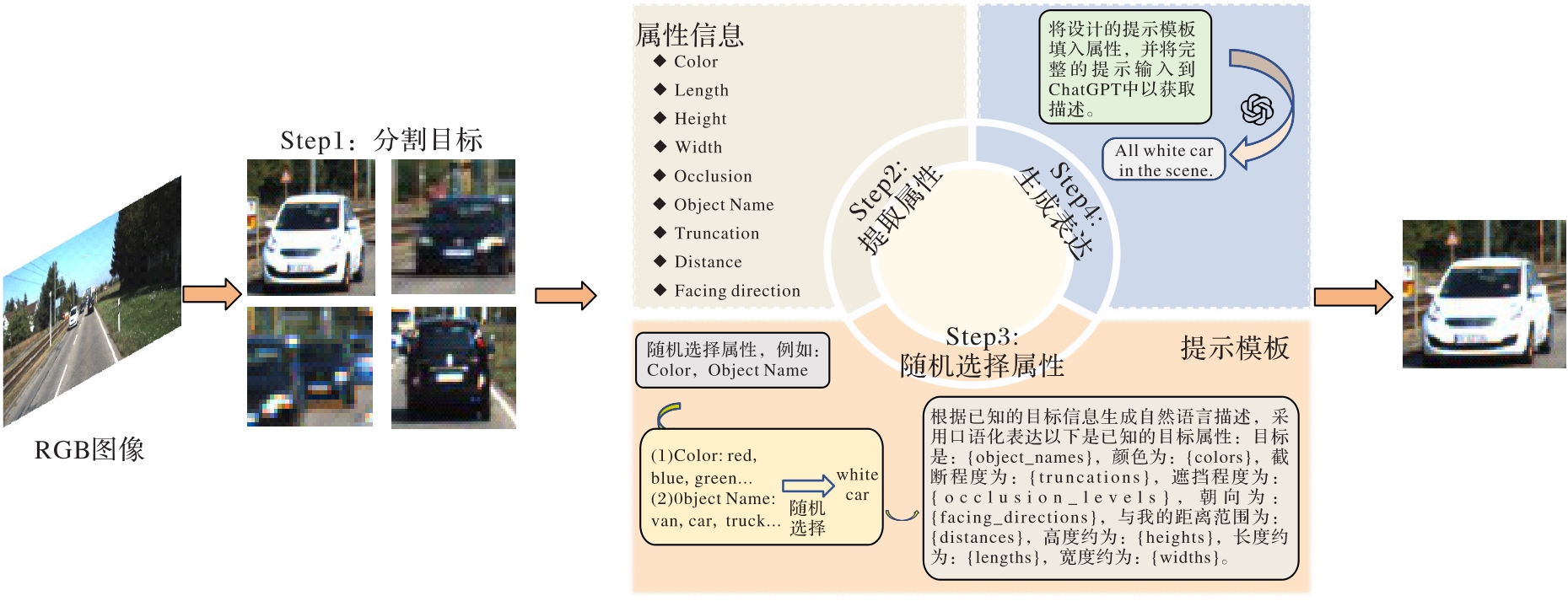
图4 数据集构建流程
Fig. 4 Dataset construction process
| 数据集 | 单样本描述数 | 多样本描述数 | 总计 |
|---|---|---|---|
| ScanRefer | 51 583 | — | 51 583 |
| Sr3D | 83 572 | — | 83 572 |
| Nr3D | 41 503 | — | 41 503 |
| SUNRefer | 38 495 | — | 38 495 |
| STRefer | 5 458 | — | 5 458 |
| Mono3DRefer | 8 228 | — | 8 228 |
| Mmo3DRefer | 2 846 | 3 229 | 6 075 |
表2 三维场景中视觉定位数据集样本的描述统计
Tab. 2 Descriptive statistics of visual grounding datasets in 3D scenes
| 数据集 | 单样本描述数 | 多样本描述数 | 总计 |
|---|---|---|---|
| ScanRefer | 51 583 | — | 51 583 |
| Sr3D | 83 572 | — | 83 572 |
| Nr3D | 41 503 | — | 41 503 |
| SUNRefer | 38 495 | — | 38 495 |
| STRefer | 5 458 | — | 5 458 |
| Mono3DRefer | 8 228 | — | 8 228 |
| Mmo3DRefer | 2 846 | 3 229 | 6 075 |
| 方法 | F1-score/% | P/% | R/% | FP | FN | TP |
|---|---|---|---|---|---|---|
| 3DJCG | 43.03 | 37.92 | 49.72 | 2 449 | 1 513 | 1 496 |
| CORE-3DVG | 47.14 | 42.41 | 53.06 | 2 200 | 1 433 | |
| 3DVG-Transformer | 47.98 | 47.66 | 48.83 | 1 700 | 1 622 | 1 548 |
| Cross3DVG | 44.13 | 46.98 | 41.61 | 1 485 | 1 847 | 1 316 |
| Multi3DRefer | 1 459 | |||||
| TextVizNet | 58.09 | 53.45 | 63.62 | 1 566 | 1028 | 1798 |
表3 TextVizNet与其他方法在Mmo3DRefer测试集上的性能比较
Tab. 3 Performance comparison of TextVizNet with other methods on Mmo3DRefer test set
| 方法 | F1-score/% | P/% | R/% | FP | FN | TP |
|---|---|---|---|---|---|---|
| 3DJCG | 43.03 | 37.92 | 49.72 | 2 449 | 1 513 | 1 496 |
| CORE-3DVG | 47.14 | 42.41 | 53.06 | 2 200 | 1 433 | |
| 3DVG-Transformer | 47.98 | 47.66 | 48.83 | 1 700 | 1 622 | 1 548 |
| Cross3DVG | 44.13 | 46.98 | 41.61 | 1 485 | 1 847 | 1 316 |
| Multi3DRefer | 1 459 | |||||
| TextVizNet | 58.09 | 53.45 | 63.62 | 1 566 | 1028 | 1798 |
| 方法 | F1-score/% | P/% | R/% | FP | FN | TP |
|---|---|---|---|---|---|---|
| 3DJCG | 54.41 | 49.83 | 59.92 | 4 690 | 3 116 | 4 658 |
| CORE-3DVG | 58.21 | 54.05 | 63.06 | 2 902 | 4 953 | |
| 3DVG-Transformer | 60.47 | 65.76 | 4063 | 2 689 | ||
| Cross3DVG | 58.27 | 51.93 | 66.37 | 5 006 | 2 740 | 5 407 |
| Multi3DRefer | 54.73 | 4 430 | 5 355 | |||
| TextVizNet | 64.46 | 57.05 | 74.08 | 4 551 | 2 115 | 6 046 |
表4 TextVizNet与其他方法在Mono3DRefer测试集上的性能比较
Tab. 4 Performance comparison of TextVizNet with other methods on Mono3DRefer test set
| 方法 | F1-score/% | P/% | R/% | FP | FN | TP |
|---|---|---|---|---|---|---|
| 3DJCG | 54.41 | 49.83 | 59.92 | 4 690 | 3 116 | 4 658 |
| CORE-3DVG | 58.21 | 54.05 | 63.06 | 2 902 | 4 953 | |
| 3DVG-Transformer | 60.47 | 65.76 | 4063 | 2 689 | ||
| Cross3DVG | 58.27 | 51.93 | 66.37 | 5 006 | 2 740 | 5 407 |
| Multi3DRefer | 54.73 | 4 430 | 5 355 | |||
| TextVizNet | 64.46 | 57.05 | 74.08 | 4 551 | 2 115 | 6 046 |
| 方法 | F1-score/% | P/% | R/% | FP | FN | TP |
|---|---|---|---|---|---|---|
| 3DJCG | 30.09 | 28.76 | 31.55 | 2 715 | 2 378 | 1 096 |
| CORE-3DVG | 32.44 | 31.90 | 33.01 | 2 541 | 2 415 | 1 190 |
| 3DVG-Transformer | 35.04 | 2 314 | ||||
| Cross3DVG | 28.63 | 26.89 | 30.63 | 2 490 | 2 075 | 916 |
| Multi3DRefer | 32.50 | 28.51 | 2 655 | 1 059 | ||
| TextVizNet | 43.11 | 38.76 | 48.56 | 2 130 | 1 428 | 1 348 |
表5 TextVizNet与其他方法在Mmo3DRefer测试集(添加高斯噪声)上的性能比较
Tab. 5 Performance comparison of TextVizNet with other methods on Mmo3DRefer test set (added Gaussian noise)
| 方法 | F1-score/% | P/% | R/% | FP | FN | TP |
|---|---|---|---|---|---|---|
| 3DJCG | 30.09 | 28.76 | 31.55 | 2 715 | 2 378 | 1 096 |
| CORE-3DVG | 32.44 | 31.90 | 33.01 | 2 541 | 2 415 | 1 190 |
| 3DVG-Transformer | 35.04 | 2 314 | ||||
| Cross3DVG | 28.63 | 26.89 | 30.63 | 2 490 | 2 075 | 916 |
| Multi3DRefer | 32.50 | 28.51 | 2 655 | 1 059 | ||
| TextVizNet | 43.11 | 38.76 | 48.56 | 2 130 | 1 428 | 1 348 |
| 信息对齐模块 | 信息融合模块 | P | R | F1-score |
|---|---|---|---|---|
| × | × | 44.39 | 50.04 | 47.05 |
| √ | × | 51.48 | 61.24 | 55.94 |
| √ | √ | 53.45 | 63.74 | 58.14 |
表6 TextVizNet在Mmo3DRefer测试集上各模块的消融实验结果 ( %)
Tab. 6 Ablation study results for each module of TextVizNet on Mmo3DRefer test set
| 信息对齐模块 | 信息融合模块 | P | R | F1-score |
|---|---|---|---|---|
| × | × | 44.39 | 50.04 | 47.05 |
| √ | × | 51.48 | 61.24 | 55.94 |
| √ | √ | 53.45 | 63.74 | 58.14 |
| 3D IoU阈值 | P/% | R/% | F1-score/% |
|---|---|---|---|
| 0.25 | 56.27 | 68.24 | 61.68 |
| 0.50 | 53.45 | 63.74 | 58.14 |
| 0.60 | 49.33 | 57.42 | 53.07 |
| 0.75 | 36.89 | 45.31 | 40.67 |
表7 Mmo3DRefer测试集上不同3D IoU阈值的模型性能比较
Tab. 7 Model performance comparison with different 3D IoU thresholds on Mmo3DRefer test set
| 3D IoU阈值 | P/% | R/% | F1-score/% |
|---|---|---|---|
| 0.25 | 56.27 | 68.24 | 61.68 |
| 0.50 | 53.45 | 63.74 | 58.14 |
| 0.60 | 49.33 | 57.42 | 53.07 |
| 0.75 | 36.89 | 45.31 | 40.67 |

图5 在Mmo3DRefer数据集上的可视化结果
Fig. 5 Visualization results on Mmo3DRefer dataset
| [1] | DENG C, WU Q, WU Q, et al. Visual grounding via accumulated attention [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7746-7755. |
| [2] | ZHANG Y, CHEN X, JIA J, et al. Text-visual prompting for efficient 2D temporal video grounding [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 14794-14804. |
| [3] | DENG J, YANG Z, CHEN T, et al. TransVG: end-to-end visual grounding with Transformers [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 1749-1759. |
| [4] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [5] | CHEN Y C, LI L, YU L, et al. UNITER: UNiversal Image-TExt Representation learning [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12375. Cham: Springer, 2020: 104-120. |
| [6] | HUANG S, CHEN Y, JIA J, et al. Multi-View Transformer for 3D visual grounding [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 15503-15512. |
| [7] | LIU Y, SUN B, WANG Y, et al. Talk to parallel LiDARs: a human-LiDAR interaction method based on 3D visual grounding [C]// Proceedings of the 2024 European Conference on Computer Vision Workshops, LNCS 15629. Cham: Springer, 2025: 305-321. |
| [8] | LU Z, PEI Y, WANG G, et al. ScanERU: interactive 3D visual grounding based on embodied reference understanding [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 3936-3944. |
| [9] | ZHU Z, ZHANG Z, MA X, et al. Unifying 3D vision-language understanding via promptable queries [C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15102. Cham: Springer, 2025: 188-206. |
| [10] | YANG L, YUAN C, ZHANG Z, et al. Exploiting contextual objects and relations for 3D visual grounding [C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2023: 49542-49554. |
| [11] | CUI K, SHEN L, ZHENG Y, et al. Talk2Radar: talking to mmWave radars via smartphone speaker [C]// Proceedings of the 2024 IEEE Conference on Computer Communications. Piscataway: IEEE, 2024: 2358-2367. |
| [12] | YANG S, LIU J, ZHANG R, et al. LiDAR-LLM: exploring the potential of large language models for 3D LiDAR understanding [C]// Proceedings of the 39th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2025: 9247-9255. |
| [13] | LI M, WANG C, FENG W, et al. Iterative robust visual grounding with masked reference based centerpoint supervision [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE, 2023: 4653-4658. |
| [14] | YANG L, XU Y, YUAN C, et al. Improving visual grounding with visual-linguistic verification and iterative reasoning [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 9489-9498. |
| [15] | CHEN S, LI B. Multi-modal dynamic graph transformer for visual grounding [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 15513-15522. |
| [16] | ZHANG Q, YUAN J. Semantic-aligned cross-modal visual grounding network with Transformers [J]. Applied Sciences, 2023, 13(9): No.5649. |
| [17] | 陆庆阳,袁广林,朱虹,等.一种基于对比学习大模型的视觉定位方法[J].电子学报, 2024, 52(10): 3448-3458. |
| LU Q Y, YUAN G L, ZHU H, et al. A visual grounding method with contrastive learning large model [J]. Acta Electronica Sinica, 2024, 52(10): 3448-3458. | |
| [18] | BIANCHI F, ATTANASIO G, PISONI R, et al. Contrastive language-image pre-training for the Italian language [C]// Proceedings of the 2023 Italian Conference on Computational Linguistics. Aachen: CEUR-WS.org, 2023: 78-85. |
| [19] | LI Y, YU A W, MENG T, et al. DeepFusion: lidar-camera deep fusion for multi-modal 3D object detection [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 17161-17170. |
| [20] | 谢凌芙.单视角RGBD图的三维视觉文本定位算法研究[D].西安:西安理工大学, 2024. |
| XIE L F. Research on 3D visual grounding based on single-vision RGBD images [D]. Xi'an: Xi'an University of Technology, 2024. | |
| [21] | ZHAO L, CAI D, SHENG L, et al. 3DVG-Transformer: relation modeling for visual grounding on point clouds [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 2908-2917. |
| [22] | ZHANG Y, GONG Z, CHANG A X. Multi3DRefer: grounding text description to multiple 3D objects [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 15179-15190. |
| [23] | MOUSAVIAN A, ANGUELOV D, FLYNN J, et al. 3D bounding box estimation using deep learning and geometry [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5632-5640. |
| [24] | BAO W, XU B, CHEN Z. MonoFENet: monocular 3D object detection with feature enhancement networks [J]. IEEE Transactions on Image Processing, 2020, 29: 2753-2765. |
| [25] | 柳长源,高阁君,刘金凤.采用深度感知Swin Transformer的单目三维目标检测方法[J/OL].北京工业大学学报[2025-03-03]. . |
| LIU C Y, GAO G J, LIU J F. Monocular three-dimensional object detection based on depth perception Swin Transformer [J]. Journal of Beijing University of Technology[2025-03-03]. . | |
| [26] | LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical Vision Transformer using shifted windows [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002. |
| [27] | ZHANG R, QIU H, WANG T, et al. MonoDETR: depth-guided transformer for monocular 3D object detection [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 9121-9132. |
| [28] | YANG A, PAN J, LIN J, et al. Chinese CLIP: contrastive vision-language pretraining in Chinese [EB/OL]. [2025-01-15]. . |
| [29] | GU A, DAO T. Mamba: linear-time sequence modeling with selective state spaces [EB/OL]. [2025-01-15]. . |
| [30] | HO Y, WOOKEY S. The real-world-weight cross-entropy loss function: modeling the costs of mislabeling [J]. IEEE Access, 2020, 8: 4806-4813. |
| [31] | CHEN D Z, CHANG A X, NIEẞNER M. ScanRefer: 3D object localization in RGB-D scans using natural language [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12365. Cham: Springer, 2020: 202-221. |
| [32] | ACHLIOPTAS P, ABDELREHEEM A, XIA F, et al. ReferIt3D: neural listeners for fine-grained 3D object identification in real-world scenes [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12346. Cham: Springer, 2020: 422-440. |
| [33] | LIU H, LIN A, HAN X, et al. Refer-it-in-RGBD: a bottom-up approach for 3D visual grounding in RGBD images [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 6028-6037. |
| [34] | LIN Z, PENG X, CONG P, et al. WildRefer: 3D object localization in large-scale dynamic scenes with multi-modal visual data and natural language [C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15104. Cham: Springer, 2025: 456-473. |
| [35] | ZHAN Y, YUAN Y, XIONG Z. Mono3DVG: 3D visual grounding in monocular images [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 6988-6996. |
| [36] | GEIGER A, LENZ P, STILLER C, et al. Vision meets robotics: the KITTI dataset [J]. The International Journal of Robotics Research, 2013, 32(11): 1231-1237. |
| [37] | CAI D, ZHAO L, ZHANG J, et al. 3DJCG: a unified framework for joint dense captioning and visual grounding on 3D point clouds [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 16443-16452. |
| [38] | MIYANISHI T, AZUMA D, KURITA S, et al. Cross3DVG: cross-dataset 3D visual grounding on different RGB-D scans [C]// Proceedings of the 2024 International Conference on 3D Vision. Piscataway: IEEE, 2024: 717-727. |
| [1] | 谢斌红, 王瑞, 张睿, 张英俊. 代理原型蒸馏的小样本目标检测算法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 233-241. |
| [2] | 李世伟, 周昱峰, 孙鹏飞, 刘伟松, 孟竹喧, 廉浩杰. 基于煤尘对激光雷达电磁波散射和吸收效应的点云数据增强方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 331-340. |
| [3] | 边小勇, 袁培洋, 胡其仁. 双编码空频混合的红外小目标检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 252-259. |
| [4] | 桑雨, 贡同, 赵琛, 于博文, 李思漫. 具有光度对齐的域适应夜间目标检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 242-251. |
| [5] | 魏利利, 闫丽蓉, 唐晓芬. 上下文语义表征和像素关系纠正的小样本目标检测[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2993-3002. |
| [6] | 张嘉祥, 李晓明, 张佳慧. 结合新类特征增强与度量机制的小样本目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2984-2992. |
| [7] | 颜承志, 陈颖, 钟凯, 高寒. 基于多尺度网络与轴向注意力的3D目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2537-2545. |
| [8] | 廖炎华, 鄢元霞, 潘文林. 基于YOLOv9的交通路口图像的多目标检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2555-2565. |
| [9] | 谢斌红, 剌颖坤, 张英俊, 张睿. 自步学习指导下的半监督目标检测框架[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2546-2554. |
| [10] | 张子墨, 赵雪专. 多尺度稀疏图引导的视觉图神经网络[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2188-2194. |
| [11] | 于平平, 闫玉婷, 唐心亮, 苏鹤, 王建超. 输电线路场景下的施工机械多目标跟踪算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2351-2360. |
| [12] | 范博淦, 王淑青, 陈开元. 基于改进YOLOv8的航拍无人机小目标检测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2342-2350. |
| [13] | 张英俊, 闫薇薇, 谢斌红, 张睿, 陆望东. 梯度区分与特征范数驱动的开放世界目标检测[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2203-2210. |
| [14] | 蒋沛宇, 王永光, 任亚亭, 李硕晨, 谭火彬. 基于测量不确定度表示指南的红外目标检测不确定度测量方案[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2162-2168. |
| [15] | 陈亮, 王璇, 雷坤. 复杂场景下跨层多尺度特征融合的安全帽佩戴检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2333-2341. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||