


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (5): 1560-1567.DOI: 10.11772/j.issn.1001-9081.2025050631
• 多媒体计算与计算机仿真 • 上一篇
明文超, 蔺素珍( ), 晋赞霞
), 晋赞霞
收稿日期:2025-06-06
修回日期:2025-07-14
接受日期:2025-08-08
发布日期:2025-08-15
出版日期:2026-05-10
通讯作者:
蔺素珍
作者简介:明文超(1999—),男,山东济南人,硕士研究生,CCF会员,主要研究方向:图像描述基金资助:
Wenchao MING, Suzhen LIN(), Zanxia JIN
Received:2025-06-06
Revised:2025-07-14
Accepted:2025-08-08
Online:2025-08-15
Published:2026-05-10
Contact:
Suzhen LIN
About author:MING Wenchao, born in 1999, M. S. candidate. His research interests include image captioning.Supported by:摘要:
现有的图像描述模型在处理复杂场景下的多波段图像时,由于多波段图像的特征在空间上存在显著差异,直接使用简单的交叉注意力难以有效地对齐和融合这些特征;而且多波段图像成像原理的不同以及场景的复杂性,导致模型难以捕捉关键的视觉语义信息,生成的描述中会出现关键目标缺失、描述不完整的情况。针对上述问题,提出一种基于场景概念引导特征融合的多波段图像描述生成方法。首先,使用预训练的特征提取器Faster R-CNN(Faster Region-based Convolutional Neural Network)提取红外和可见光图像的区域特征,构建由场景概念引导的多波段特征对齐融合模块(FAFM);其次,为了提高模型对视觉语义信息的建模能力,设计概念引导模块(CGM)为图像检索场景概念并进行编码;最后,构建自适应的门控机制(AGM),当解码器在每个时间步生成单词时,模型可以根据不同情况动态调整多波段图像的融合特征与概念特征的权重,从而实现特征的融合。在可见光图像-红外图像描述数据集上的实验结果表明,所提方法在BLEU-4(BiLingual Evaluation Understudy with 4-grams)和CIDEr(Consensus-based Image Description Evaluation)指标上分别达到56.7%和119.5%,较次优方法分别提高了1.1个和2.9个百分点。可见,所提方法能有效提高多波段图像描述的准确度。
中图分类号:
明文超, 蔺素珍, 晋赞霞. 基于场景概念引导特征融合的多波段图像描述生成方法[J]. 计算机应用, 2026, 46(5): 1560-1567.
Wenchao MING, Suzhen LIN, Zanxia JIN. Multi-band image captioning method based on scene concept-guided feature fusion[J]. Journal of Computer Applications, 2026, 46(5): 1560-1567.
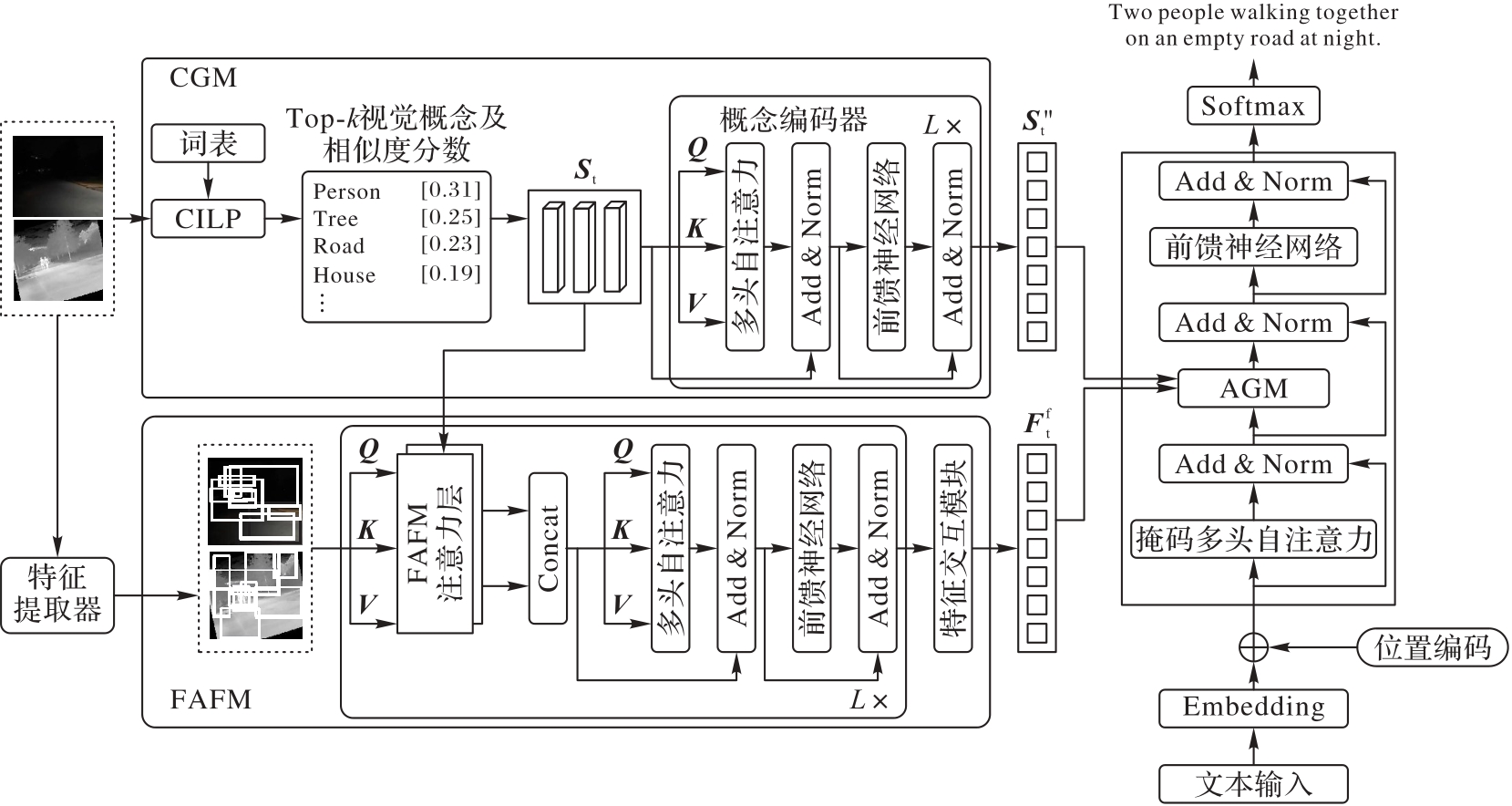
图1 本文方法的总体框架
Fig. 1 Overall framework of proposed method
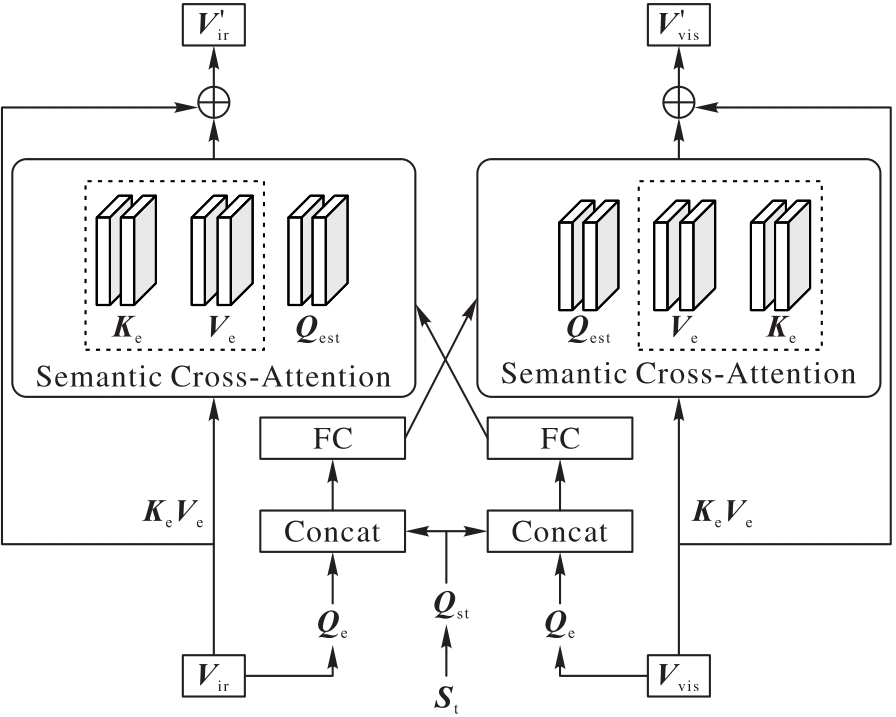
图2 FAFM注意力层结构
Fig.2 FAFM attention layer structure
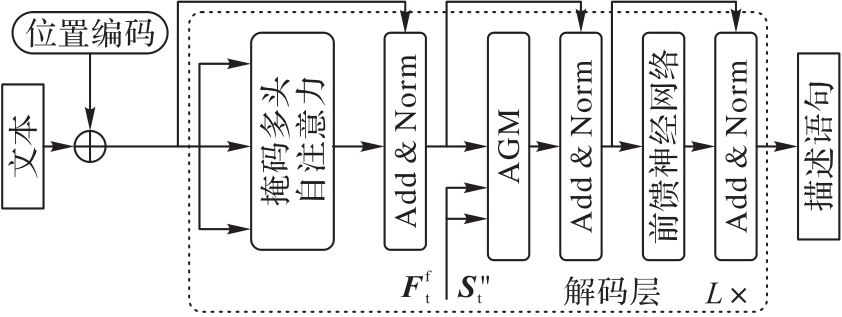
图3 解码器框架
Fig.3 Decoder framework
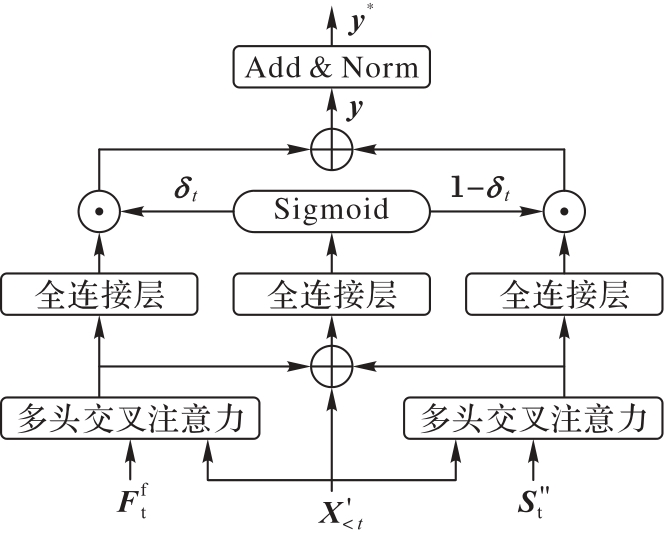
图4 AGM网络结构
Fig.4 AGM network structure
| 视觉概念数 | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| 5 | 79.9 | 70.2 | 61.8 | 54.8 | 35.4 | 68.0 | 117.0 |
| 10 | 80.0 | 70.7 | 62.4 | 55.6 | 35.9 | 68.0 | 118.9 |
| 15 | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
| 20 | 79.6 | 70.4 | 62.4 | 55.6 | 35.6 | 67.8 | 118.5 |
| 25 | 79.7 | 70.3 | 62.1 | 55.3 | 35.7 | 68.0 | 116.9 |
| 30 | 79.6 | 70.2 | 61.9 | 55.0 | 35.7 | 68.0 | 116.1 |
表1 视觉概念数对模型性能的影响 ( %)
Tab. 1 Impact of visual concept number on model performance
| 视觉概念数 | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| 5 | 79.9 | 70.2 | 61.8 | 54.8 | 35.4 | 68.0 | 117.0 |
| 10 | 80.0 | 70.7 | 62.4 | 55.6 | 35.9 | 68.0 | 118.9 |
| 15 | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
| 20 | 79.6 | 70.4 | 62.4 | 55.6 | 35.6 | 67.8 | 118.5 |
| 25 | 79.7 | 70.3 | 62.1 | 55.3 | 35.7 | 68.0 | 116.9 |
| 30 | 79.6 | 70.2 | 61.9 | 55.0 | 35.7 | 68.0 | 116.1 |
| FAFM | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| × | 78.8 | 69.5 | 61.7 | 55.4 | 35.2 | 67.8 | 117.3 |
| √ | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
表2 FAFM的消融实验结果 ( %)
Tab. 2 Results of ablation experiment on FAFM
| FAFM | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| × | 78.8 | 69.5 | 61.7 | 55.4 | 35.2 | 67.8 | 117.3 |
| √ | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
| CGM | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| × | 79.6 | 69.8 | 61.4 | 54.6 | 35.5 | 67.5 | 116.4 |
| √ | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
表3 CGM的消融实验结果 ( %)
Tab. 3 Results of ablation experiment on CGM
| CGM | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| × | 79.6 | 69.8 | 61.4 | 54.6 | 35.5 | 67.5 | 116.4 |
| √ | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
| AGM | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| × | 79.6 | 70.1 | 61.9 | 55.1 | 35.5 | 67.7 | 117.9 |
| √ | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
表4 AGM的消融实验结果 ( %)
Tab. 4 Results of ablation experiment on AGM
| AGM | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| × | 79.6 | 70.1 | 61.9 | 55.1 | 35.5 | 67.7 | 117.9 |
| √ | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
| 方法 | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| SCST[ | 58.9 | 48.4 | 31.7 | 25.9 | 23.2 | 41.7 | 55.2 |
| Up-Down[ | 57.6 | 47.2 | 31.0 | 24.2 | 22.5 | 40.8 | 51.7 |
| AoA[ | 61.2 | 50.1 | 34.7 | 27.8 | 23.7 | 47.4 | 60.3 |
| ORT[ | 59.1 | 44.7 | 32.8 | 25.9 | 23.2 | 46.3 | 55.8 |
| M2[ | 79.2 | 69.5 | 61.1 | 54.1 | 35.3 | 67.4 | 114.5 |
| RSTNet[ | 78.1 | 68.7 | 60.4 | 53.6 | 34.9 | 66.8 | 112.9 |
| DLCT[ | 77.1 | 68.1 | 60.4 | 54.1 | 34.5 | 66.2 | 113.0 |
| VisualGPT[ | 79.3 | 69.7 | 62.2 | 54.8 | 35.6 | 67.5 | 115.2 |
| DRET[ | 79.0 | 69.2 | 61.3 | 53.8 | 35.2 | 67.9 | 115.5 |
| GSSF[ | 79.3 | 70.4 | 62.4 | 54.3 | 35.1 | 66.8 | 116.3 |
| MBIC[ | 81.2 | 70.1 | 62.3 | 55.3 | 34.0 | 66.8 | 111.3 |
| FFIC[ | 79.2 | 70.0 | 62.0 | 55.6 | 35.7 | 67.9 | 116.6 |
| 本文方法 | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |
表5 本文方法与代表性方法的性能对比 ( %)
Tab. 5 Performance comparison of proposed method and representative methods
| 方法 | B1 | B2 | B3 | B4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| SCST[ | 58.9 | 48.4 | 31.7 | 25.9 | 23.2 | 41.7 | 55.2 |
| Up-Down[ | 57.6 | 47.2 | 31.0 | 24.2 | 22.5 | 40.8 | 51.7 |
| AoA[ | 61.2 | 50.1 | 34.7 | 27.8 | 23.7 | 47.4 | 60.3 |
| ORT[ | 59.1 | 44.7 | 32.8 | 25.9 | 23.2 | 46.3 | 55.8 |
| M2[ | 79.2 | 69.5 | 61.1 | 54.1 | 35.3 | 67.4 | 114.5 |
| RSTNet[ | 78.1 | 68.7 | 60.4 | 53.6 | 34.9 | 66.8 | 112.9 |
| DLCT[ | 77.1 | 68.1 | 60.4 | 54.1 | 34.5 | 66.2 | 113.0 |
| VisualGPT[ | 79.3 | 69.7 | 62.2 | 54.8 | 35.6 | 67.5 | 115.2 |
| DRET[ | 79.0 | 69.2 | 61.3 | 53.8 | 35.2 | 67.9 | 115.5 |
| GSSF[ | 79.3 | 70.4 | 62.4 | 54.3 | 35.1 | 66.8 | 116.3 |
| MBIC[ | 81.2 | 70.1 | 62.3 | 55.3 | 34.0 | 66.8 | 111.3 |
| FFIC[ | 79.2 | 70.0 | 62.0 | 55.6 | 35.7 | 67.9 | 116.6 |
| 本文方法 | 80.4 | 71.0 | 62.8 | 56.7 | 36.1 | 68.5 | 119.5 |

图5 不同方法的结果可视化分析
Fig. 5 Visual analysis results by different methods
| [1] | SHARMA H, PADHA D. Domain-specific image captioning: a comprehensive review[J]. International Journal of Multimedia Information Retrieval, 2024, 13: No.20. |
| [2] | GHANDI T, POURREZA H, MAHYAR H. Deep learning approaches on image captioning: a review[J]. ACM Computing Surveys, 2024, 56(3): No.62. |
| [3] | ALEISSAEE A A, KUMAR A, ANWER R M, et al. Transformers in remote sensing: a survey[J]. Remote Sensing, 2023, 15(7): No.1860. |
| [4] | 朱翌,李秀.医学图像描述综述:编码、解码及最新进展[J].中国图象图形学报,2023,28(7):1990-2010. |
| ZHU Y, LI X. A survey of medical image captioning technique: encoding, decoding and latest advance[J]. Journal of Image and Graphics, 2023, 28(7): 1990-2010. | |
| [5] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| [6] | 贺姗,蔺素珍,王彦博,等. 基于特征融合的多波段图像描述生成方法[J]. 计算机工程, 2024, 50(6): 236-244. |
| HE S, LIN S Z, WANG Y B, et al. Multi-band image caption generation method based on feature fusion[J]. Computer Engineering, 2024, 50(6): 236-244. | |
| [7] | 顾梦瑶,蔺素珍,晋赞霞,等.基于特征对齐融合的双波段图像描述生成方法[J].现代电子技术,2025,48(7):65-71. |
| GU M Y, LIN S Z, JIN Z X, et al. Dual-band image captioning generation method based on feature alignment fusion[J]. Modern Electronic Technique, 2025, 48(7): 65-71. | |
| [8] | 贺姗. 面向可见光和红外同步探测的图像描述方法研究[D]. 太原:中北大学, 2024. |
| HE S. Research on image caption method for visible and infrared synchronous detection[D]. Taiyuan: North University of China, 2024. | |
| [9] | WANG Y, LOU S, WANG K, et al. Automatic captioning based on visible and infrared images[C]// Proceedings of the 2024 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2024: 11312-11318. |
| [10] | STEFANINI M, CORNIA M, BARALDI L, et al. From show to tell: a survey on deep learning-based image captioning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 539-559. |
| [11] | 周峻宇,施水才,王洪俊. 基于深度学习的图像字幕生成综述[J]. 软件导刊, 2025, 24(1): 211-220. |
| ZHOU J Y, SHI S C, WANG H J. An overview of deep learning-based image caption generation[J]. Software Guide, 2025, 24(1): 211-220. | |
| [12] | XU K, BA J L, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention[C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 2048-2057. |
| [13] | RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1179-1195. |
| [14] | ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6077-6086. |
| [15] | HUANG L, WANG W, CHEN J, et al. Attention on attention for image captioning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 4633-4642. |
| [16] | PAN Y, YAO T, LI Y, et al. X-Linear attention networks for image captioning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10968-10977. |
| [17] | GAO C, BIAN G, DONG Y, et al. Infrared image captioning based on unsupervised learning and reinforcement learning[C]// Proceedings of the 2022 International Conference on Automation, Robotics and Computer Engineering. Piscataway: IEEE, 2022: 1-4. |
| [18] | YANG X, TANG K, ZHANG H, et al. Auto-encoding scene graphs for image captioning[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 10677-10686. |
| [19] | YANG X, LIU Y, WANG X. ReFormer: the relational Transformer for image captioning[C]// Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 5398-5406. |
| [20] | HERDADE S, KAPPELER A, BOAKYE K, et al. Image captioning: transforming objects into words[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 11137-11147. |
| [21] | CORNIA M, STEFANINI M, BARALDI L, et al. Meshed-memory Transformer for image captioning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10575-10584. |
| [22] | ZHANG J, FANG Z, SUN H, et al. Adaptive semantic-enhanced Transformer for image captioning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(2): 1785-1796. |
| [23] | 白雪冰,车进,吴金蔓,等. 基于Transformer视觉特征融合的图像描述方法[J]. 计算机工程, 2024, 50(8): 229-238. |
| BAI X B, CHE J, WU J M, et al. Image captioning method based on Transformer visual features fusion[J]. Computer Engineering, 2024, 50(8): 229-238. | |
| [24] | FANG Z, WANG J, HU X, et al. Injecting semantic concepts into end-to-end image captioning[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 17988-17998. |
| [25] | CHEN J, GUO H, YI K, et al. VisualGPT: data-efficient adaptation of pretrained language models for image captioning[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 18009-18019. |
| [26] | 王子怡,李卫军,刘雪洋,等. 基于Swin Transformer与多尺度特征融合的图像描述方法[J]. 计算机应用, 2025, 45(10): 3154-3160. |
| WANG Z Y, LI W J, LIU X Y, et al. Image caption method based on Swin Transformer and multi-scale feature fusion[J]. Journal of Computer Applications, 2025, 45(10): 3154-3160. | |
| [27] | LV J, HUI T, ZHI Y, et al. Infrared image caption based on object-oriented attention[J]. Entropy, 2023, 25(5): No.826. |
| [28] | GEBHARDT E, WOLF M. Camel dataset for visual and thermal infrared multiple object detection and tracking[C]// Proceedings of the 15th IEEE International Conference on Advanced Video and Signal based Surveillance. Piscataway: IEEE, 2018: 1-6. |
| [29] | LI C, CHENG H, HU S, et al. Learning collaborative sparse representation for grayscale-thermal tracking[J]. IEEE Transactions on Image Processing, 2016, 25(12): 5743-5756. |
| [30] | LI C, LIANG X, LU Y, et al. RGB-T object tracking: benchmark and baseline[J]. Pattern Recognition, 2019, 96: No.106977. |
| [31] | CHENG C, XU T, WU X J, et al. TextFusion: unveiling the power of textual semantics for controllable image fusion[J]. Information Fusion, 2025, 117: No.102790. |
| [32] | LI H, XU T, WU X J, et al. LRRNet: a novel representation learning guided fusion network for infrared and visible images[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(9): 11040-11052. |
| [33] | ZHANG X, SUN X, LUO Y, et al. RSTNet: captioning with adaptive attention on visual and non-visual words[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 15460-15469. |
| [34] | LUO Y, JI J, SUN X, et al. Dual-level collaborative Transformer for image captioning[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 2286-2293. |
| [35] | ZHOU W, SONG C, CHEN D, et al. From multi-scale grids to dynamic regions: dual-relation enhanced Transformer for image captioning[J]. Knowledge-Based Systems, 2025, 311: No.113127. |
| [36] | PARSEH M J, GHADIRI S. Graph-based image captioning with semantic and spatial features[J]. Signal Processing: Image Communication, 2025, 133: No.117273. |
| [1] | 黄雨倩, 黄辉, 秦永彬, 黄瑞章, 陈艳平, 周裕林, 孙倩. 融合全局和局部语义的司法要素抽取方法[J]. 《计算机应用》唯一官方网站, 2026, 46(5): 1460-1467. |
| [2] | 郑嘉丽, 周刚, 陈静, 李顺航. 基于多特征自适应融合的智能生成文本检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(5): 1433-1440. |
| [3] | 李文浩, 郭银章. 基于双层多尺度动态GCN模型的城市交通流量预测[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1323-1333. |
| [4] | 刘欢娴, 王洪涛, 王宪奥, 王洪梅, 徐伟峰. 跨模态语义关联的多模态事实验证[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1069-1076. |
| [5] | 何帅, 邓春华. 基于YOLO-World的少样本学习目标检测算法[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1275-1282. |
| [6] | 严心怡, 朱灵龙, 张永宏. 面向复杂交通场景的多尺度实时人车检测方法CDC-DETR[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1283-1291. |
| [7] | 刘汉卿, 桑国明, 张益嘉. 结合密集多尺度特征融合和特征知识增强Transformer的遥感图像描述模型[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 741-749. |
| [8] | 付锦程, 杨仕友. 基于贝叶斯优化和特征融合混合模型的短期风电功率预测[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 652-658. |
| [9] | 韩锋, 卜永丰, 梁浩翔, 黄舒雯, 张朝阳, 孙士杰. 基于多层次时空交互依赖的车辆轨迹异常检测[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 604-612. |
| [10] | 梁瑾裕, 高宏娟, 杜晓飞. 基于潜在特征增强进行解耦的三维人脸生成方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 216-223. |
| [11] | 昝志辉, 王雅静, 李珂, 杨智翔, 杨光宇. 基于SAA-CNN-BiLSTM网络的多特征融合语音情感识别方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 69-76. |
| [12] | 曹柠, 温昕, 郝雁嵘, 曹锐. 多域特征融合的轻量化运动想象脑电信号解码神经网络[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 289-296. |
| [13] | 梁一鸣, 范菁, 柴汶泽. 基于双向交叉注意力的多尺度特征融合情感分类[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2773-2782. |
| [14] | 李维刚, 邵佳乐, 田志强. 基于双注意力机制和多尺度融合的点云分类与分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3003-3010. |
| [15] | 许志雄, 李波, 边小勇, 胡其仁. 对抗样本嵌入注意力U型网络的3D医学图像分割[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 3011-3016. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||