


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (11): 3379-3385.DOI: 10.11772/j.issn.1001-9081.2023101516
颜新月, 杨淑群, 高永彬( )
)
收稿日期:2023-11-06
修回日期:2024-01-31
接受日期:2024-02-04
发布日期:2024-11-13
出版日期:2024-11-10
通讯作者:
高永彬
作者简介:颜新月(2000—),女,山东临沂人,硕士研究生,主要研究方向:自然语言处理基金资助:
Xinyue YAN, Shuqun YANG, Yongbin GAO()
Received:2023-11-06
Revised:2024-01-31
Accepted:2024-02-04
Online:2024-11-13
Published:2024-11-10
Contact:
Yongbin GAO
About author:YAN Xinyue, born in 2000, M. S. candidate. Her research interests include natural language processing.摘要:
文档级关系抽取(DocRE)的目的是识别文档中实体对之间存在的所有关系。针对证据句子和文档信息未能被有效利用以及实体多提及的问题,在使用证据增强上下文特征的基础上,构建一种多特征融合的文档级关系抽取模型EMF(Evidence Multi-feature Fusion)。首先,在实体前后加上实体类型,将关系文本特征与实体提及进行关联,以获得特定于关系的实体特征。其次,通过不同卷积核获得片段表示,并通过注意力机制获得实体对感知的多粒度片段级特征;同时,利用证据分布增强与实体对高度相关的上下文特征。最后,融合以上特征进行关系分类,并在推理时将获得的证据组成伪文档与原文档一起输入分类器进行关系分类。在DocRE数据集DocRED(Document-level Relation Extraction Dataset)上的实验结果表明,使用BERTbase作为预训练语言模型编码器时,相较于先进模型EIDER(EvIDence-Enhanced DocRE),所提模型EMF的Ign F1和F1分别提高了0.42和0.41个百分点,F1达到了62.89%。EMF模型更关注与实体和关系相关的部分,可提高抽取的精度,并具有较好的可解释性。
中图分类号:
颜新月, 杨淑群, 高永彬. 基于证据增强与多特征融合的文档级关系抽取[J]. 计算机应用, 2024, 44(11): 3379-3385.
Xinyue YAN, Shuqun YANG, Yongbin GAO. Document-level relationship extraction based on evidence enhancement and multi-feature fusion[J]. Journal of Computer Applications, 2024, 44(11): 3379-3385.

图1 文档实例
Fig. 1 Document instance
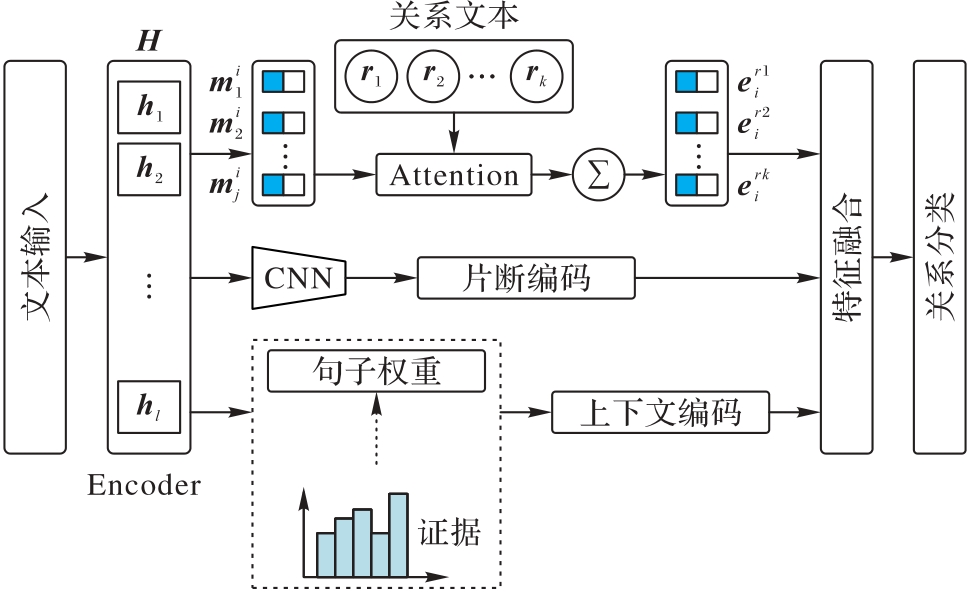
图2 EMF模型结构
Fig. 2 Structure of EMF model
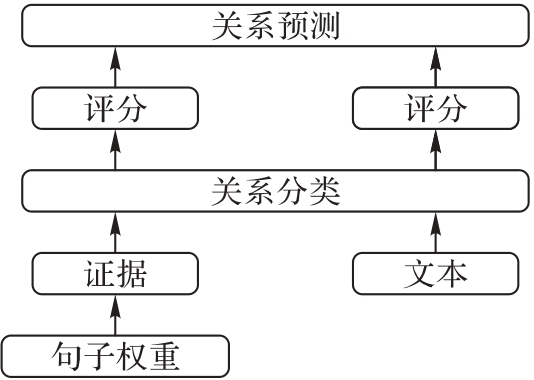
图3 推理结构
Fig. 3 Inference structure
| 模型 | PLM | 开发集 | 测试集 | |||
|---|---|---|---|---|---|---|
| Ign F1 | F1 | Evi F1 | Ign F1 | F1 | ||
| LSR | BERTbase | 52.43 | 59.00 | — | 56.97 | 59.05 |
| GAIN | 59.14 | 61.22 | — | 59.00 | 61.24 | |
| BERT | — | 54.16 | — | — | 53.20 | |
| SSAN | 57.03 | 59.19 | — | 55.84 | 58.16 | |
| ATLOP | 59.22 | 61.09 | — | 59.31 | 61.30 | |
| E2GRE | 55.22 | 58.79 | 47.12 | — | — | |
| DocuNet | 59.86 | 61.83 | — | 59.93 | 61.86 | |
| ERA | 59.72 | 61.80 | 59.08 | 61.36 | ||
| EIDER | 60.51 | 62.48 | 51.27 | 60.96 | 62.77 | |
| EMF | 60.93 | 62.89 | 52.35 | 61.10 | 62.88 | |
| Core | RoBERTalarge | 57.35 | 59.43 | — | 57.90 | 60.25 |
| SSAN | 60.25 | 62.08 | — | 59.47 | 61.42 | |
| ATLOP | 61.32 | 63.18 | — | 61.39 | 63.40 | |
| EMF | 62.30 | 64.20 | 54.12 | 62.12 | 64.42 | |
表 1 DocRED数据集上不同模型的结果对比 ( %)
Tab. 1 Comparison of results of different models on DocRED dataset
| 模型 | PLM | 开发集 | 测试集 | |||
|---|---|---|---|---|---|---|
| Ign F1 | F1 | Evi F1 | Ign F1 | F1 | ||
| LSR | BERTbase | 52.43 | 59.00 | — | 56.97 | 59.05 |
| GAIN | 59.14 | 61.22 | — | 59.00 | 61.24 | |
| BERT | — | 54.16 | — | — | 53.20 | |
| SSAN | 57.03 | 59.19 | — | 55.84 | 58.16 | |
| ATLOP | 59.22 | 61.09 | — | 59.31 | 61.30 | |
| E2GRE | 55.22 | 58.79 | 47.12 | — | — | |
| DocuNet | 59.86 | 61.83 | — | 59.93 | 61.86 | |
| ERA | 59.72 | 61.80 | 59.08 | 61.36 | ||
| EIDER | 60.51 | 62.48 | 51.27 | 60.96 | 62.77 | |
| EMF | 60.93 | 62.89 | 52.35 | 61.10 | 62.88 | |
| Core | RoBERTalarge | 57.35 | 59.43 | — | 57.90 | 60.25 |
| SSAN | 60.25 | 62.08 | — | 59.47 | 61.42 | |
| ATLOP | 61.32 | 63.18 | — | 61.39 | 63.40 | |
| EMF | 62.30 | 64.20 | 54.12 | 62.12 | 64.42 | |
| 模型 | F1 | |
|---|---|---|
| CDR | GDA | |
| BRAN | 62.1 | — |
| EGO | 63.6 | 81.5 |
| LSR | 64.8 | 82.2 |
| ATLOP-SciBERT | 69.4 | 83.9 |
| EMF-SciBERT | 75.8 | 84.9 |
表 2 CDR与GDA上的F1对比 ( %)
Tab. 2 Comparison of F1 on CDR and GDA
| 模型 | F1 | |
|---|---|---|
| CDR | GDA | |
| BRAN | 62.1 | — |
| EGO | 63.6 | 81.5 |
| LSR | 64.8 | 82.2 |
| ATLOP-SciBERT | 69.4 | 83.9 |
| EMF-SciBERT | 75.8 | 84.9 |
| 模型 | Ign F1 | F1 | Evi F1 |
|---|---|---|---|
| EMF | 60.93 | 62.89 | 52.35 |
| -evidence | 59.60 | 61.82 | 42.79 |
| -relation | 58.72 | 61.40 | 42.73 |
| -n-gram | 58.05 | 61.08 | 42.75 |
| -cls | 57.55 | 60.22 | 42.80 |
表 3 消融实验结果 ( %)
Tab. 3 Ablation experimental results
| 模型 | Ign F1 | F1 | Evi F1 |
|---|---|---|---|
| EMF | 60.93 | 62.89 | 52.35 |
| -evidence | 59.60 | 61.82 | 42.79 |
| -relation | 58.72 | 61.40 | 42.73 |
| -n-gram | 58.05 | 61.08 | 42.75 |
| -cls | 57.55 | 60.22 | 42.80 |

图4 关系提及关联前后的对比
Fig. 4 Comparison before and after association of relationship and mentions

图5 多粒度特征信息使用前后的对比
Fig. 5 Comparison before and after using multi-granularity information

图6 证据增强前后的对比
Fig. 6 Comparison before and after evidence enhancement
| 1 | PENG N, POON H, QUIRK C, et al. Cross-sentence n-ary relation extraction with graph LSTMs[J]. Transactions of the Association for Computational Linguistics, 2017, 5: 101-115. |
| 2 | VERGA P, STRUBELL E, McCALLUM A. Simultaneously self-attending to all mentions for full-abstract biological relation extraction[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Stroudsburg, PA: ACL, 2018:872-884. |
| 3 | YAO Y, YE D, LI P, et al. DocRED: a large-scale document-level relation extraction dataset[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2019:764-777. |
| 4 | YE D, LIN Y, DU J, et al. Coreferential reasoning learning for language representation[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 7170- 7186. |
| 5 | XU B, WANG Q, LYU Y, et al. Entity structure within and throughout: modeling mention dependencies for document-level relation extraction[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 14149-14157. |
| 6 | LI J, XU K, LI F, et al. MRN: a locally and globally mention-based reasoning network for document-level relation extraction[C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg, PA: ACL, 2021: 1359-1370. |
| 7 | ZHOU W, HUANG K, MA T, et al. Document-level relation extraction with adaptive thresholding and localized context pooling[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 14612-14620. |
| 8 | CAI R, ZHANG X, WANG H. Bidirectional recurrent convolutional neural network for relation classification[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2016: 756-765. |
| 9 | ZHANG N, DENG S, SUN Z, et al. Relation adversarial network for low resource knowledge graph completion[C]// Proceedings of the Web Conference 2020. New York: ACM, 2020: 1-12. |
| 10 | QUIRK C, POON H. Distant supervision for relation extraction beyond the sentence boundary[C]// Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers. Stroudsburg, PA: ACL, 2017: 1171-1182. |
| 11 | ZENG S, XU R, CHANG B, et al. Double graph based reasoning for document-level relation extraction[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 1630-1640. |
| 12 | XU W, CHEN K, ZHAO T. Document-level relation extraction with reconstruction[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 14167-14175. |
| 13 | ZENG S, WU Y, CHANG B. SIRE: separate intra-and inter-sentential reasoning for document-level relation extraction[C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg, PA: ACL, 2021: 524-534. |
| 14 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017:6000-6010. |
| 15 | ZHANG N, CHEN X, XIE X, et al. Document-level relation extraction as semantic segmentation[C]// Proceedings of the 30th International Joint Conference on Artificial Intelligence. California: IJCAI, 2021: 3999-4006. |
| 16 | 袁泉,徐雲鹏,唐成亮. 基于路径标签的文档级关系抽取方法[J]. 计算机应用, 2023, 43(4):1029-1035. |
| YUAN Q, XU Y P, TANG C L. Document level-relationship extraction method based on path labels[J]. Journal of Computer Applications, 2023, 43(4): 1029-1035. | |
| 17 | HUANG K, QI P, WANG G, et al. Entity and evidence guided document-level relation extraction[C]// Proceedings of the 6th Workshop on Representation Learning for NLP. Stroudsburg, PA: ACL, 2021: 307-315. |
| 18 | HUANG Q, ZHU S, FENG Y, et al. Three sentences are all you need: local path enhanced document relation extraction[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Stroudsburg, PA: ACL, 2021: 998-1004. |
| 19 | TAN Q, HE R, BING L, et al. Document-level relation extraction with adaptive focal loss and knowledge distillation[C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg, PA: ACL, 2022: 1672-1681. |
| 20 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: ACL, 2019: 4171-4186. |
| 21 | XIE Y, SHEN J, LI S, et al. EIDER: empowering document-level relation extraction with efficient evidence extraction and inference-stage fusion[C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg, PA: ACL, 2022: 257-268. |
| 22 | LI J, SUN Y, JOHNSON R J, et al. BioCreative V CDR task corpus: a resource for chemical disease relation extraction[J]. Database, 2016, 2016: No.baw068. |
| 23 | WU Y, LUO R, LEUNG H C M, et al. RENET: a deep learning approach for extracting gene-disease associations from literature[C]// Proceedings of the 2019 International Conference on Research in Computational Molecular Biology, LNCS 11467. Cham: Springer, 2019: 272-284. |
| 24 | WOLF T, DEBUT L, SANH V, et al. Transformers: state-of-the-art natural language processing[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Stroudsburg, PA: ACL, 2020: 38-45. |
| 25 | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. [2023-07-09].. |
| 26 | NAN G, GUO Z, SEKULIĆ I, et al. Reasoning with latent structure refinement for document-level relation extraction[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 1546-1557. |
| 27 | DU Y, MA T, WU L, et al. Improving long tailed document-level relation extraction via easy relation augmentation and contrastive learning[EB/OL]. [2023-08-12].. |
| 28 | CHRISTOPOULOU F, MIWA M, ANANIADOU S. Connecting the dots:document-level neural relation extraction with edge-oriented graphs[C]// Proceedings of 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 4925-4936. |
| 29 | BELTAGY I, LO K, COHAN A. SciBERT: a pretrained language model for scientific text[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 3615-3620. |
| TFoundation:his work is partially supported by Shanghai Local Capacity Building Project (21010501500); Shanghai “Science and Technology Innovation Action Plan” Social Development Science and Technology Research Project (21DZ1204900). |
| [1] | 赵宇博, 张丽萍, 闫盛, 侯敏, 高茂. 基于改进分段卷积神经网络和知识蒸馏的学科知识实体间关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2421-2429. |
| [2] | 毛典辉, 李学博, 刘峻岭, 张登辉, 颜文婧. 基于并行异构图和序列注意力机制的中文实体关系抽取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2018-2025. |
| [3] | 唐媛, 陈艳平, 扈应, 黄瑞章, 秦永彬. 基于多尺度混合注意力卷积神经网络的关系抽取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2011-2017. |
| [4] | 魏超, 陈艳平, 王凯, 秦永彬, 黄瑞章. 基于掩码提示与门控记忆网络校准的关系抽取方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1713-1719. |
| [5] | 袁泉, 陈昌平, 陈泽, 詹林峰. 基于BERT的两次注意力机制远程监督关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1080-1085. |
| [6] | 郭安迪, 贾真, 李天瑞. 基于伪实体数据增强的高精准率医学领域实体关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 393-402. |
| [7] | 邓金科, 段文杰, 张顺香, 汪雨晴, 李书羽, 李嘉伟. 基于提示增强与双图注意力网络的复杂因果关系抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3081-3089. |
| [8] | 田阔, 吴英晗, 胡枫. 基于证据理论的多层超网络影响力节点识别方法[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 182-189. |
| [9] | 陈克正, 郭晓然, 钟勇, 李振平. 基于负训练和迁移学习的关系抽取方法[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2426-2430. |
| [10] | 王思蕊, 程世娟, 袁非梦. 基于改进证据融合的高可靠产品可靠性评估方法[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2140-2146. |
| [11] | 黄梦林, 段磊, 张袁昊, 王培妍, 李仁昊. 基于Prompt学习的无监督关系抽取模型[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2010-2016. |
| [12] | 雷景生, 剌凯俊, 杨胜英, 吴怡. 基于上下文语义增强的实体关系联合抽取[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1438-1444. |
| [13] | 程顺航, 李志华, 魏涛. 融合自举与语义角色标注的威胁情报实体关系抽取方法[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1445-1453. |
| [14] | 袁泉, 徐雲鹏, 唐成亮. 基于路径标签的文档级关系抽取方法[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1029-1035. |
| [15] | 王昱, 范子琳, 任田君, 姬晓飞. 不完备信息下基于切换推理证据网络的空中目标识别方法[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1071-1078. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||