


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (3): 823-831.DOI: 10.11772/j.issn.1001-9081.2024091398
薛振华1, 李强1, 黄超2( )
)
收稿日期:2024-10-07
修回日期:2024-12-01
接受日期:2024-12-03
发布日期:2025-01-14
出版日期:2025-03-10
通讯作者:
黄超
作者简介:薛振华(1983—),男,山西大同人,经济师,硕士,主要研究方向:缺陷检测、高效重载运输基金资助:
Zhenhua XUE1, Qiang LI1, Chao HUANG2()
Received:2024-10-07
Revised:2024-12-01
Accepted:2024-12-03
Online:2025-01-14
Published:2025-03-10
Contact:
Chao HUANG
About author:XUE Zhenhua, born in 1983, M. S., economist. His research interests include defect detection, efficient heavy-duty transportation.Supported by:摘要:
现有的异常检测方法能在特定应用场景下实现高精度检测,然而这些方法难以适用于其他应用场景,且自动化程度有限。因此,提出一种视觉基础模型(VFM)驱动的像素级图像异常检测方法SSMOD-Net(State Space Model driven-Omni Dimensional Net),旨在实现更精确的工业缺陷检测。与现有方法不同,SSMOD-Net实现SAM(Segment Anything Model)的自动化提示且不需要微调SAM,因此特别适用于需要处理大规模工业视觉数据的场景。SSMOD-Net的核心是一个新颖的提示编码器,该编码器由状态空间模型驱动,能够根据SAM的输入图像动态地生成提示。这一设计允许模型在保持SAM架构不变的同时,通过提示编码器引入额外的指导信息,从而提高检测精度。提示编码器内部集成一个残差多尺度模块,该模块基于状态空间模型构建,能够综合利用多尺度信息和全局信息。这一模块通过迭代搜索,在提示空间中寻找最优的提示,并将这些提示以高维张量的形式提供给SAM,从而增强模型对工业异常的识别能力。而且所提方法不需要对SAM进行任何修改,从而避免复杂的对训练计划的微调需求。在多个数据集上的实验结果表明,所提方法展现出了卓越的性能,与AutoSAM和SAM-EG(SAM with Edge Guidance framework for efficient polyp segmentation)等方法相比,所提方法在mE(mean E-measure)和平均绝对误差(MAE)、Dice和交并比(IoU)上都取得了较好的结果。
中图分类号:
薛振华, 李强, 黄超. 视觉基础模型驱动的像素级图像异常检测方法[J]. 计算机应用, 2025, 45(3): 823-831.
Zhenhua XUE, Qiang LI, Chao HUANG. Vision foundation model-driven pixel-level image anomaly detection method[J]. Journal of Computer Applications, 2025, 45(3): 823-831.
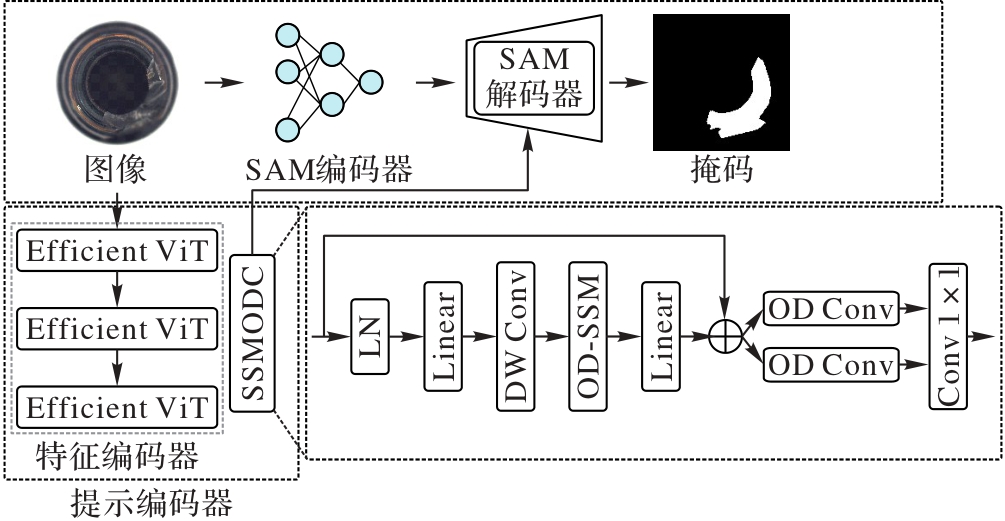
图1 本文方法的框架
Fig. 1 Framework of proposed method
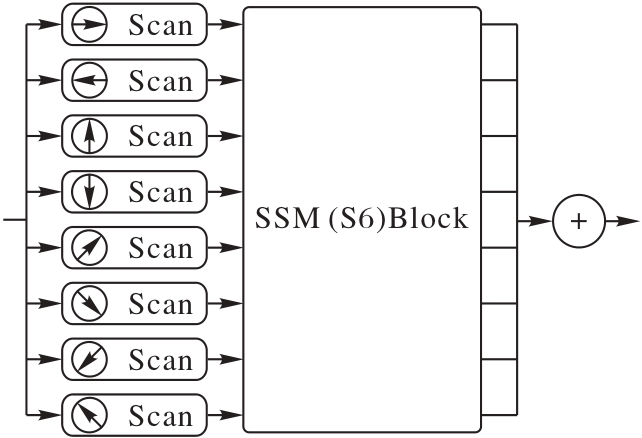
图2 OD-SSM结构
Fig. 2 Structure of OD-SSM
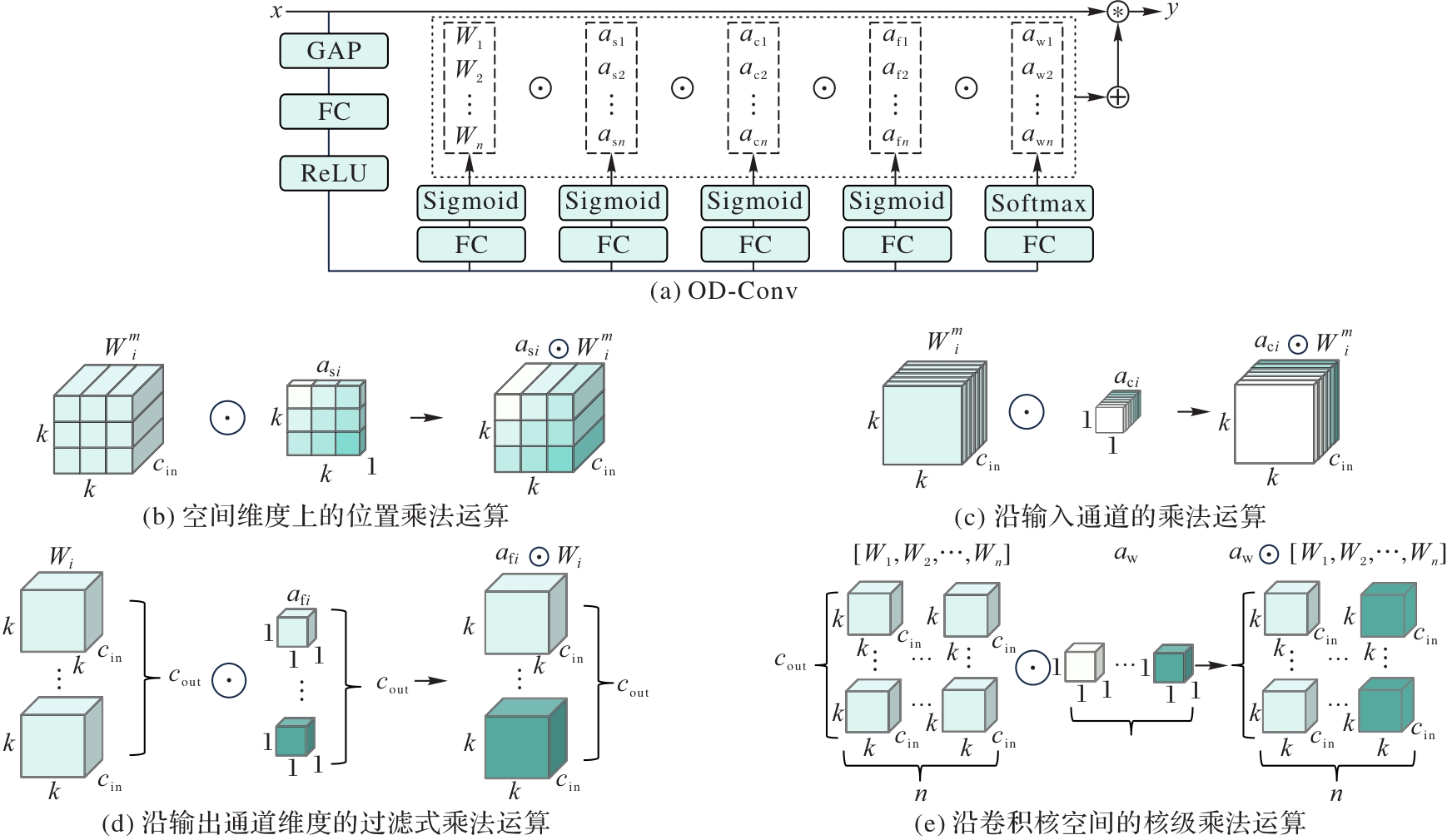
图3 OD Conv的结构与核心运算机制
Fig. 3 Structure and core computing mechanism of OD Conv
| 类别 | SFA[ | ACSNet[ | PraNet[ | 文献[ | AutoSAM[ | I-MedSAM[ | 本文方法 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | mE | MAE | mE | MAE | mE | MAE | mE | MAE | mE | MAE | mE | MAE | mE | |
| 平均 | 0.041 | 0.739 | 0.036 | 0.840 | 0.015 | 0.844 | 0.011 | 0.860 | 0.014 | 0.820 | 0.016 | 0.875 | 0.009 | 0.904 |
| 药片 | 0.031 | 0.735 | 0.022 | 0.772 | 0.010 | 0.826 | 0.006 | 0.850 | 0.004 | 0.900 | 0.006 | 0.878 | 0.004 | 0.947 |
| 电缆 | 0.083 | 0.726 | 0.037 | 0.825 | 0.024 | 0.828 | 0.018 | 0.881 | 0.022 | 0.791 | 0.024 | 0.831 | 0.020 | 0.833 |
| 胶囊 | 0.025 | 0.552 | 0.006 | 0.788 | 0.008 | 0.808 | 0.004 | 0.765 | 0.017 | 0.429 | 0.010 | 0.841 | 0.007 | 0.850 |
| 瓷砖 | 0.062 | 0.768 | 0.016 | 0.961 | 0.024 | 0.907 | 0.012 | 0.924 | 0.014 | 0.954 | 0.012 | 0.954 | 0.011 | 0.968 |
| 晶体管 | 0.133 | 0.596 | 0.758 | 0.189 | 0.034 | 0.616 | 0.032 | 0.838 | 0.063 | 0.390 | 0.105 | 0.590 | 0.023 | 0.913 |
| 地毯 | 0.031 | 0.690 | 0.011 | 0.848 | 0.011 | 0.885 | 0.008 | 0.855 | 0.007 | 0.900 | 0.007 | 0.912 | 0.010 | 0.893 |
| 木材 | 0.031 | 0.832 | 0.013 | 0.938 | 0.018 | 0.899 | 0.013 | 0.900 | 0.016 | 0.860 | 0.017 | 0.880 | 0.012 | 0.892 |
| 榛子 | 0.077 | 0.583 | 0.009 | 0.960 | 0.015 | 0.902 | 0.008 | 0.939 | 0.006 | 0.906 | 0.007 | 0.930 | 0.006 | 0.908 |
| 皮革 | 0.015 | 0.737 | 0.003 | 0.940 | 0.005 | 0.886 | 0.004 | 0.878 | 0.004 | 0.915 | 0.004 | 0.904 | 0.004 | 0.914 |
| 螺丝 | 0.007 | 0.750 | 0.003 | 0.833 | 0.006 | 0.729 | 0.003 | 0.780 | 0.005 | 0.789 | 0.002 | 0.903 | 0.002 | 0.905 |
| 金属螺母 | 0.095 | 0.747 | 0.022 | 0.809 | 0.021 | 0.885 | 0.013 | 0.930 | 0.012 | 0.939 | 0.011 | 0.947 | 0.010 | 0.950 |
| 牙刷 | 0.045 | 0.738 | 0.033 | 0.786 | 0.042 | 0.692 | 0.027 | 0.729 | 0.007 | 0.806 | 0.007 | 0.839 | 0.003 | 0.876 |
| 拉链 | 0.009 | 0.941 | 0.008 | 0.923 | 0.011 | 0.930 | 0.009 | 0.920 | 0.008 | 0.918 | 0.007 | 0.930 | 0.007 | 0.914 |
| 瓶子 | 0.037 | 0.883 | 0.029 | 0.898 | 0.037 | 0.850 | 0.017 | 0.940 | 0.018 | 0.948 | 0.019 | 0.947 | 0.017 | 0.936 |
| 网格 | 0.023 | 0.718 | 0.009 | 0.775 | 0.011 | 0.818 | 0.010 | 0.806 | 0.007 | 0.859 | 0.006 | 0.842 | 0.005 | 0.865 |
表1 不同方法在MVTec AD数据集上的定量结果比较
Tab. 1 Quantitative results comparison of different methods on MVTec AD dataset
| 类别 | SFA[ | ACSNet[ | PraNet[ | 文献[ | AutoSAM[ | I-MedSAM[ | 本文方法 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | mE | MAE | mE | MAE | mE | MAE | mE | MAE | mE | MAE | mE | MAE | mE | |
| 平均 | 0.041 | 0.739 | 0.036 | 0.840 | 0.015 | 0.844 | 0.011 | 0.860 | 0.014 | 0.820 | 0.016 | 0.875 | 0.009 | 0.904 |
| 药片 | 0.031 | 0.735 | 0.022 | 0.772 | 0.010 | 0.826 | 0.006 | 0.850 | 0.004 | 0.900 | 0.006 | 0.878 | 0.004 | 0.947 |
| 电缆 | 0.083 | 0.726 | 0.037 | 0.825 | 0.024 | 0.828 | 0.018 | 0.881 | 0.022 | 0.791 | 0.024 | 0.831 | 0.020 | 0.833 |
| 胶囊 | 0.025 | 0.552 | 0.006 | 0.788 | 0.008 | 0.808 | 0.004 | 0.765 | 0.017 | 0.429 | 0.010 | 0.841 | 0.007 | 0.850 |
| 瓷砖 | 0.062 | 0.768 | 0.016 | 0.961 | 0.024 | 0.907 | 0.012 | 0.924 | 0.014 | 0.954 | 0.012 | 0.954 | 0.011 | 0.968 |
| 晶体管 | 0.133 | 0.596 | 0.758 | 0.189 | 0.034 | 0.616 | 0.032 | 0.838 | 0.063 | 0.390 | 0.105 | 0.590 | 0.023 | 0.913 |
| 地毯 | 0.031 | 0.690 | 0.011 | 0.848 | 0.011 | 0.885 | 0.008 | 0.855 | 0.007 | 0.900 | 0.007 | 0.912 | 0.010 | 0.893 |
| 木材 | 0.031 | 0.832 | 0.013 | 0.938 | 0.018 | 0.899 | 0.013 | 0.900 | 0.016 | 0.860 | 0.017 | 0.880 | 0.012 | 0.892 |
| 榛子 | 0.077 | 0.583 | 0.009 | 0.960 | 0.015 | 0.902 | 0.008 | 0.939 | 0.006 | 0.906 | 0.007 | 0.930 | 0.006 | 0.908 |
| 皮革 | 0.015 | 0.737 | 0.003 | 0.940 | 0.005 | 0.886 | 0.004 | 0.878 | 0.004 | 0.915 | 0.004 | 0.904 | 0.004 | 0.914 |
| 螺丝 | 0.007 | 0.750 | 0.003 | 0.833 | 0.006 | 0.729 | 0.003 | 0.780 | 0.005 | 0.789 | 0.002 | 0.903 | 0.002 | 0.905 |
| 金属螺母 | 0.095 | 0.747 | 0.022 | 0.809 | 0.021 | 0.885 | 0.013 | 0.930 | 0.012 | 0.939 | 0.011 | 0.947 | 0.010 | 0.950 |
| 牙刷 | 0.045 | 0.738 | 0.033 | 0.786 | 0.042 | 0.692 | 0.027 | 0.729 | 0.007 | 0.806 | 0.007 | 0.839 | 0.003 | 0.876 |
| 拉链 | 0.009 | 0.941 | 0.008 | 0.923 | 0.011 | 0.930 | 0.009 | 0.920 | 0.008 | 0.918 | 0.007 | 0.930 | 0.007 | 0.914 |
| 瓶子 | 0.037 | 0.883 | 0.029 | 0.898 | 0.037 | 0.850 | 0.017 | 0.940 | 0.018 | 0.948 | 0.019 | 0.947 | 0.017 | 0.936 |
| 网格 | 0.023 | 0.718 | 0.009 | 0.775 | 0.011 | 0.818 | 0.010 | 0.806 | 0.007 | 0.859 | 0.006 | 0.842 | 0.005 | 0.865 |
| 方法 | Kvasir33 | Clinic | Colon | ETIS | ||||
|---|---|---|---|---|---|---|---|---|
| Dice | IoU | Dice | IoU | Dice | IoU | Dice | IoU | |
| U-Net | 81.80 | 74.60 | 82.30 | 75.50 | 51.20 | 44.40 | 39.80 | 33.50 |
| U-Net++ | 82.10 | 74.30 | 79.40 | 72.90 | 48.30 | 41.00 | 40.10 | 34.40 |
| SFA | 72.30 | 61.10 | 70.00 | 60.70 | 46.90 | 34.70 | 29.70 | 21.70 |
| MSEG | 89.70 | 83.90 | 90.90 | 86.40 | 73.50 | 66.60 | 70.00 | 63.00 |
| DCRNet | 88.60 | 82.50 | 89.60 | 84.40 | 70.40 | 63.10 | 55.60 | 49.60 |
| ACSNet | 89.80 | 83.80 | 88.20 | 82.60 | 71.60 | 64.90 | 57.80 | 50.90 |
| PraNet | 89.80 | 84.00 | 89.90 | 84.90 | 71.20 | 64.00 | 62.80 | 56.70 |
| EU-Net | 90.80 | 85.40 | 90.20 | 84.60 | 75.60 | 68.10 | 68.70 | 60.90 |
| SANet | 90.40 | 84.70 | 91.60 | 85.90 | 75.30 | 67.00 | 75.00 | 65.40 |
| COMMA | 90.40 | 86.00 | 91.60 | 87.10 | 75.40 | 71.10 | 64.80 | |
| SAM-EG | 93.10 | 87.90 | ||||||
| 本文方法 | 92.10 | 87.60 | 79.30 | 71.30 | 78.60 | 71.50 | ||
表2 不同方法在Kvasir33、Clinic、Colon和ETIS数据集上的定量结果比较 (%)
Tab. 2 Quantitative results comparison of different methods on Kvasir33, Clinic, Colon, and ETIS datasets
| 方法 | Kvasir33 | Clinic | Colon | ETIS | ||||
|---|---|---|---|---|---|---|---|---|
| Dice | IoU | Dice | IoU | Dice | IoU | Dice | IoU | |
| U-Net | 81.80 | 74.60 | 82.30 | 75.50 | 51.20 | 44.40 | 39.80 | 33.50 |
| U-Net++ | 82.10 | 74.30 | 79.40 | 72.90 | 48.30 | 41.00 | 40.10 | 34.40 |
| SFA | 72.30 | 61.10 | 70.00 | 60.70 | 46.90 | 34.70 | 29.70 | 21.70 |
| MSEG | 89.70 | 83.90 | 90.90 | 86.40 | 73.50 | 66.60 | 70.00 | 63.00 |
| DCRNet | 88.60 | 82.50 | 89.60 | 84.40 | 70.40 | 63.10 | 55.60 | 49.60 |
| ACSNet | 89.80 | 83.80 | 88.20 | 82.60 | 71.60 | 64.90 | 57.80 | 50.90 |
| PraNet | 89.80 | 84.00 | 89.90 | 84.90 | 71.20 | 64.00 | 62.80 | 56.70 |
| EU-Net | 90.80 | 85.40 | 90.20 | 84.60 | 75.60 | 68.10 | 68.70 | 60.90 |
| SANet | 90.40 | 84.70 | 91.60 | 85.90 | 75.30 | 67.00 | 75.00 | 65.40 |
| COMMA | 90.40 | 86.00 | 91.60 | 87.10 | 75.40 | 71.10 | 64.80 | |
| SAM-EG | 93.10 | 87.90 | ||||||
| 本文方法 | 92.10 | 87.60 | 79.30 | 71.30 | 78.60 | 71.50 | ||
| 方法 | MoNuSeg | GlaS | ||
|---|---|---|---|---|
| Dice | IoU | Dice | IoU | |
| FCN | 28.84 | 28.71 | — | — |
| U-Net | 79.43 | 65.99 | 75.12 | 75.12 |
| U-Net++ | 79.49 | 66.04 | 79.03 | 79.03 |
| Axial Attention | 76.83 | 62.49 | — | — |
| MedT | 79.55 | 66.17 | 88.85 | 78.93 |
| PraNet | 79.62 | 66.14 | 89.69 | 82.19 |
| UCTransNet | 79.87 | 66.68 | 89.84 | 82.24 |
| 文献[ | 80.13 | 67.09 | 91.19 | 84.34 |
| Med-SA | 80.34 | 67.33 | ||
| LViT | 80.15 | 67.00 | 90.02 | 82.68 |
| 文献[ | 91.08 | 84.00 | ||
| 本文方法 | 84.02 | 72.52 | 92.74 | 87.01 |
表3 不同方法在MoNuSeg和GlaS数据集上的定量结果比较 (%)
Tab. 3 Quantitative results comparison of different methods on MoNuSeg and GlaS datasets
| 方法 | MoNuSeg | GlaS | ||
|---|---|---|---|---|
| Dice | IoU | Dice | IoU | |
| FCN | 28.84 | 28.71 | — | — |
| U-Net | 79.43 | 65.99 | 75.12 | 75.12 |
| U-Net++ | 79.49 | 66.04 | 79.03 | 79.03 |
| Axial Attention | 76.83 | 62.49 | — | — |
| MedT | 79.55 | 66.17 | 88.85 | 78.93 |
| PraNet | 79.62 | 66.14 | 89.69 | 82.19 |
| UCTransNet | 79.87 | 66.68 | 89.84 | 82.24 |
| 文献[ | 80.13 | 67.09 | 91.19 | 84.34 |
| Med-SA | 80.34 | 67.33 | ||
| LViT | 80.15 | 67.00 | 90.02 | 82.68 |
| 文献[ | 91.08 | 84.00 | ||
| 本文方法 | 84.02 | 72.52 | 92.74 | 87.01 |
| SAM | OD-SSM | OD Conv | MoNuSeg | GlaS | ||
|---|---|---|---|---|---|---|
| Dice | IoU | Dice | IoU | |||
| √ | 82.43 | 70.17 | 92.10 | 86.02 | ||
| √ | √ | 82.99 | 71.01 | 92.58 | 86.62 | |
| √ | √ | 83.36 | 71.59 | 92.60 | 86.81 | |
| √ | √ | √ | 84.02 | 72.52 | 92.74 | 87.01 |
表4 消融实验结果 (%)
Tab. 4 Ablation experiment results
| SAM | OD-SSM | OD Conv | MoNuSeg | GlaS | ||
|---|---|---|---|---|---|---|
| Dice | IoU | Dice | IoU | |||
| √ | 82.43 | 70.17 | 92.10 | 86.02 | ||
| √ | √ | 82.99 | 71.01 | 92.58 | 86.62 | |
| √ | √ | 83.36 | 71.59 | 92.60 | 86.81 | |
| √ | √ | √ | 84.02 | 72.52 | 92.74 | 87.01 |
| OD Conv数 | MoNuSeg | GlaS | ||
|---|---|---|---|---|
| Dice/% | IoU/% | Dice/% | IoU/% | |
| 1 | 83.63 | 71.97 | 92.37 | 86.38 |
| 2 | 84.02 | 72.52 | 92.74 | 87.01 |
| 3 | 82.52 | 70.32 | 92.63 | 86.93 |
表5 OD Conv 数对模型性能的影响
Tab. 5 Influence of OD Conv number on model performance
| OD Conv数 | MoNuSeg | GlaS | ||
|---|---|---|---|---|
| Dice/% | IoU/% | Dice/% | IoU/% | |
| 1 | 83.63 | 71.97 | 92.37 | 86.38 |
| 2 | 84.02 | 72.52 | 92.74 | 87.01 |
| 3 | 82.52 | 70.32 | 92.63 | 86.93 |
| OD-SSM数 | MoNuSeg | GlaS | ||
|---|---|---|---|---|
| Dice/% | IoU/% | Dice/% | IoU/% | |
| 1 | 84.02 | 72.52 | 92.74 | 87.01 |
| 2 | 83.21 | 71.35 | 92.61 | 86.77 |
| 3 | 83.14 | 71.22 | 92.53 | 86.66 |
表6 OD-SSM数对模型性能的影响
Tab. 6 Influence of OD-SSM number on model performance
| OD-SSM数 | MoNuSeg | GlaS | ||
|---|---|---|---|---|
| Dice/% | IoU/% | Dice/% | IoU/% | |
| 1 | 84.02 | 72.52 | 92.74 | 87.01 |
| 2 | 83.21 | 71.35 | 92.61 | 86.77 |
| 3 | 83.14 | 71.22 | 92.53 | 86.66 |
| 卷积机制 | MoNuSeg | GlaS | ||
|---|---|---|---|---|
| Dice | IoU | Dice | IoU | |
| DW Conv | 84.02 | 72.52 | 92.74 | 87.01 |
| Conv | 83.78 | 72.00 | 92.56 | 86.69 |
表7 不同卷积机制对模型性能的影响 (%)
Tab. 7 Influence of different Conv mechanisms on model performance
| 卷积机制 | MoNuSeg | GlaS | ||
|---|---|---|---|---|
| Dice | IoU | Dice | IoU | |
| DW Conv | 84.02 | 72.52 | 92.74 | 87.01 |
| Conv | 83.78 | 72.00 | 92.56 | 86.69 |
| 卷积机制 | MoNuSeg | GlaS | ||
|---|---|---|---|---|
| Dice | IoU | Dice | IoU | |
| OD Conv | 84.02 | 72.52 | 92.74 | 87.01 |
| Conv | 82.76 | 70.69 | 92.16 | 86.09 |
表8 OD Conv和标准卷积对模型性能的影响 (%)
Tab. 8 Influence of OD Conv and standard convolution on model performance
| 卷积机制 | MoNuSeg | GlaS | ||
|---|---|---|---|---|
| Dice | IoU | Dice | IoU | |
| OD Conv | 84.02 | 72.52 | 92.74 | 87.01 |
| Conv | 82.76 | 70.69 | 92.16 | 86.09 |
| 方法 | 计算量/GFLOPs | 参数量/106 |
|---|---|---|
| AutoSAM | 80.314 | 88.569 |
| I-MedSAM | 648.060 | 92.520 |
| 本文方法 | 53.902 | 53.687 |
表9 不同方法的时间复杂度和空间复杂度对比
Tab. 9 Time and space complexity comparison of different methods
| 方法 | 计算量/GFLOPs | 参数量/106 |
|---|---|---|
| AutoSAM | 80.314 | 88.569 |
| I-MedSAM | 648.060 | 92.520 |
| 本文方法 | 53.902 | 53.687 |

图4 MVTec AD数据集上不同模型的可视化结果
Fig. 4 Visualization results of different models on MVTec dataset

图5 MoNuSeg、GlaS和Kvasir33数据集上不同模型的可视化结果
Fig. 5 Visualization results of different models on MoNuSeg, GlaS, and Kvasir33 datasets
| 1 | HUANG C, WEN J, XU Y, et al. Self-supervised attentive generative adversarial networks for video anomaly detection [J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(11): 9389-9403. |
| 2 | KIM T, LEE H, KIM D. UACANet: uncertainty augmented context attention for polyp segmentation [C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 2167-2175. |
| 3 | HUANG C, LIU C, ZHANG Z, et al. Pixel-level anomaly detection via uncertainty-aware prototypical Transformer [C]// Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 521-530. |
| 4 | MAMONOV A V, FIGUEIREDO I N, FIGUEIREDO P N, et al. Automated polyp detection in colon capsule endoscopy [J]. IEEE Transactions on Medical Imaging, 2014, 33(7): 1488-1502. |
| 5 | TAJBAKHSH N, GURUDU S R, LIANG J. Automated polyp detection in colonoscopy videos using shape and context information[J]. IEEE Transactions on Medical Imaging, 2016, 35(2): 630-644. |
| 6 | KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything [C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 3992-4003. |
| 7 | LI J, CHEN T, WANG X, et al. Adapting the segment anything model for multi-modal retinal anomaly detection and localization[J]. Information Fusion, 2025, 113: No.102631. |
| 8 | LIU J, WU K, NIE Q, et al. Unsupervised continual anomaly detection with contrastively-learned prompt [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 3639-3647. |
| 9 | CAI W, HUANG W, TIAN L, et al. Multiscale global attention for abnormal geological hazard segmentation [J]. IEEE Sensors Journal, 2024, 24(10): 16961-16971. |
| 10 | XIE B, TANG H, DUAN B, et al. MaskSAM: towards auto-prompt SAM with mask classification for medical image segmentation [EB/OL]. [2024-05-14]. . |
| 11 | SHAHARABANY T, DAHAN A, GIRYES R, et al. AutoSAM: adapting SAM to medical images by overloading the prompt encoder[C]// Proceedings of the 2023 British Machine Vision Conference. Durham: BMVA Press, 2023: No.530. |
| 12 | BAE S H, YOON K J. Polyp detection via imbalanced learning and discriminative feature learning [J]. IEEE Transactions on Medical Imaging, 2015, 34(11): 2379-2393. |
| 13 | REISS T, COHEN N, BERGMAN L, et al. PANDA: adapting pretrained features for anomaly detection and segmentation [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 2805-2813. |
| 14 | CHEN Z, LI J, LUO Y, et al. CANZSL: cycle-consistent adversarial networks for zero-shot learning from natural language [C]// Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2020: 863-872. |
| 15 | CHEN Z, LUO Y, QIU R, et al. Semantics disentangling for generalized zero-shot learning [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 8692-8700. |
| 16 | LIU A A, TIAN H, XU N, et al. Toward region-aware attention learning for scene graph generation [J]. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(12): 7655-7666. |
| 17 | RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241. |
| 18 | ZHOU Z, RAHMAN SIDDIQUEE M M, TAJBAKHSH N, et al. UNet++: a nested U-Net architecture for medical image segmentation [C]// Proceedings of the 4th International Workshop on Deep Learning in Medical Image Analysis and 8th International Workshop on Multimodal Learning for Clinical Decision Support, LNCS 11045. Cham: Springer, 2018: 3-11. |
| 19 | FANG Y, CHEN C, YUAN Y, et al. Selective feature aggregation network with area-boundary constraints for polyp segmentation[C]// Proceedings of the 2019 International Conference on Medical Image Computing and Computer Assisted Intervention, LNCS 11764. Cham: Springer, 2019: 302-310. |
| 20 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. [2024-08-10]. . |
| 21 | WEI X, CAO J, JIN Y, et al. I-MedSAM: implicit medical image segmentation with segment anything [C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15068. Cham: Springer, 2025: 90-107. |
| 22 | XIE Z, GUAN B, JIANG W, et al. PA-SAM: prompt adapter SAM for high-quality image segmentation[EB/OL]. [2024-08-19]. . |
| 23 | GU A, DAO T. Mamba: linear-time sequence modeling with selective state spaces [EB/OL]. [2024-04-03]. . |
| 24 | ZHAO S, CHEN H, ZHANG X, et al. RS-Mamba for large remote sensing image dense prediction[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: No.5633314. |
| 25 | LI C, ZHOU A, YAO A. Omni-dimensional dynamic convolution[EB/OL]. [2024-09-23]. . |
| 26 | BERGMANN P, FAUSER M, SATTLEGGER D, et al. Uninformed students: student-teacher anomaly detection with discriminative latent embeddings [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 4182-4191. |
| 27 | KUMAR N, VERMA R, SHARMA S, et al. A dataset and a technique for generalized nuclear segmentation for computational pathology [J]. IEEE Transactions on Medical Imaging, 2017, 36(7): 1550-1560. |
| 28 | SIRINUKUNWATTANA K, PLUIM J P W, CHEN H, et al. Gland segmentation in colon histology images: the GlaS challenge contest [J]. Medical Image Analysis, 2017, 35: 489-502. |
| 29 | JHA D, SMEDSRUD P H, RIEGLER M A, et al. Kvasir-SEG: a segmented polyp dataset [C]// Proceedings of the 2020 International Conference on MultiMedia Modeling, LNCS 11962. Cham: Springer, 2020: 451-462. |
| 30 | BERNAL J, SÁNCHEZ F J, FERNÁNDEZ-ESPARRACH G, et al. WM-DOVA maps for accurate polyp highlighting in colonoscopy: validation vs. saliency maps from physicians [J]. Computerized Medical Imaging and Graphics, 2015, 43: 99-111. |
| 31 | SILVA J, HISTACE A, ROMAIN O, et al. Toward embedded detection of polyps in WCE images for early diagnosis of colorectal cancer [J]. International Journal of Computer Assisted Radiology and Surgery, 2014, 9(2): 283-293. |
| 32 | FAN D P, JI G P, ZHOU T, et al. PraNet: parallel reverse attention network for polyp segmentation [C]// Proceedings of the 2020 International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2020: 263-273. |
| 33 | KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL]. [2024-08-10]. . |
| 34 | 范登平,季葛鹏,秦雪彬,等. 认知规律启发的物体分割评价标准及损失函数[J]. 中国科学:信息科学, 2021, 51(9):1475-1489. |
| FAN D P, JI G P, QIN X B, et al. Cognitive vision inspired object segmentation metric and loss function [J]. SCIENTIA SINICA Informationis, 2021, 51(9): 1475-1489. | |
| 35 | LI Z, LI Y, LI Q, et al. LViT: language meets vision Transformer in medical image segmentation [J]. IEEE Transactions on Medical Imaging, 2024, 43(1): 96-107. |
| 36 | ZHANG R, LI G, LI Z, et al. Adaptive context selection for polyp segmentation [C]// Proceedings of the 2020 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 12266. Cham: Springer, 2020: 253-262. |
| 37 | TRINH Q H, NGUYEN H D, NGOC B T N, et al. SAM-EG: segment anything model with edge guidance framework for efficient polyp segmentation [C]// Proceedings of the 2024 British Machine Vision Conference. Durham: BMVA Press, 2024: No.472. |
| 38 | HUANG C H, WU H Y, LIN Y L. HarDNet-MSEG: a simple encoder-decoder polyp segmentation neural network that achieves over 0.9 mean Dice and 86 FPS [EB/OL]. [2024-03-04]. . |
| 39 | YIN Z, LIANG K, MA Z, et al. Duplex contextual relation network for polyp segmentation [C]// Proceedings of the IEEE 19th International Symposium on Biomedical Imaging. Piscataway: IEEE, 2022: 1-5. |
| 40 | PATEL K, BUR A M, WANG G. Enhanced U-Net: a feature enhancement network for polyp segmentation [C]// Proceedings of the 18th Conference on Robots and Vision. Piscataway: IEEE, 2021: 181-188. |
| 41 | WEI J, HU Y, ZHANG R, et al. Shallow attention network for polyp segmentation [C]// Proceedings of the 2021 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 12901. Cham: Springer, 2021: 699-708. |
| 42 | SHIN W, LEE M S, HAN S W. COMMA: propagating complementary multi-level aggregation network for polyp segmentation [J]. Applied Sciences, 2022, 12(4): No.2114. |
| 43 | BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495. |
| 44 | WANG H, ZHU Y, GREEN B, et al. Axial-DeepLab: stand-alone axial-attention for panoptic segmentation [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12349. Cham: Springer, 2020: 108-126. |
| 45 | VALANARASU J M J, OZA P, HACIHALILOGLU I, et al. Medical Transformer: gated axial-attention for medical image segmentation [C]// Proceedings of the 2021 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 12901. Cham: Springer, 2021: 36-46. |
| 46 | WANG H, CAO P, WANG J, et al. UCTransNet: rethinking the skip connections in U-Net from a channel-wise perspective with Transformer [C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 2441-2449. |
| 47 | SHAHARABANY T, WOLF L. End-to-end segmentation of medical images via patch-wise polygons prediction [C]// Proceedings of the 2022 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 13435. Cham: Springer, 2022: 308-318. |
| 48 | WU J, JI W, LIU Y, et al. Medical SAM Adapter: adapting segment anything model for medical image segmentation [EB/OL]. [2024-09-03]. . |
| 49 | HUANG C, CAI W, JIANG Q, et al. Multimodal representation distribution learning for medical image segmentation [C]// Proceedings of the 33rd International Joint Conference on Artificial Intelligence. California: IJCAI.org, 2024: 4156-4164. |
| [1] | 邓淼磊, 阚雨培, 孙川川, 徐海航, 樊少珺, 周鑫. 基于深度学习的网络入侵检测系统综述[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 453-466. |
| [2] | 余松森, 林智凡, 薛国鹏, 徐建宇. 基于改进YOLOv8的轻量级大幅面瓷砖缺陷检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 647-654. |
| [3] | 丁丹妮, 彭博, 吴锡. 受腹侧通路启发的脂肪肝超声图像分类方法VPNet[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 662-669. |
| [4] | 张天骐, 谭霜, 沈夕文, 唐娟. 融合注意力机制和多尺度特征的图像水印方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 616-623. |
| [5] | 洪梓榕, 包广清. 基于集成学习的雷达自动目标识别综述[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 371-382. |
| [6] | 张众维, 王俊, 刘树东, 王志恒. 多尺度特征融合与加权框融合的遥感图像目标检测[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 633-639. |
| [7] | 李严, 叶冠华, 李雅文, 梁美玉. 基于丰度协调技术的企业ESG指标预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 670-676. |
| [8] | 张思齐, 张金俊, 王天一, 秦小林. 基于信号时态逻辑的深度时序事件检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 90-97. |
| [9] | 郑宗生, 杜嘉, 成雨荷, 赵泽骋, 张月维, 王绪龙. 用于红外-可见光图像分类的跨模态双流交替交互网络[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 275-283. |
| [10] | 徐欣然, 张绍兵, 成苗, 张洋, 曾尚. 基于多路层次化混合专家模型的轴承故障诊断方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 59-68. |
| [11] | 梁杰涛, 罗兵, 付兰慧, 常青玲, 李楠楠, 易宁波, 冯其, 何鑫, 邓辅秦. 基于坐标几何采样的点云配准方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 214-222. |
| [12] | 晏燕, 钱星颖, 闫鹏斌, 杨杰. 位置大数据的联邦学习统计预测与差分隐私保护方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 127-135. |
| [13] | 李顺勇, 李师毅, 胥瑞, 赵兴旺. 基于自注意力融合的不完整多视图聚类算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2696-2703. |
| [14] | 黄云川, 江永全, 黄骏涛, 杨燕. 基于元图同构网络的分子毒性预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2964-2969. |
| [15] | 潘烨新, 杨哲. 基于多级特征双向融合的小目标检测优化模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2871-2877. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||