


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (5): 1408-1415.DOI: 10.11772/j.issn.1001-9081.2025050595
• 人工智能 • 上一篇
邢长征, 郑鑫( ), 贾迪, 梁浚锋
), 贾迪, 梁浚锋
收稿日期:2025-06-03
修回日期:2025-08-29
接受日期:2025-09-09
发布日期:2025-09-15
出版日期:2026-05-10
通讯作者:
郑鑫
作者简介:邢长征(1967—),男,辽宁阜新人,教授,博士,CCF会员,主要研究方向:人工智能、信息处理基金资助:
Changzheng XING, Xin ZHENG(), Di JIA, Junfeng LIANG
Received:2025-06-03
Revised:2025-08-29
Accepted:2025-09-09
Online:2025-09-15
Published:2026-05-10
Contact:
Xin ZHENG
About author:XING Changzheng, born in 1967, Ph. D.,professor. His research interests include artificial intelligence, information processing.Supported by:摘要:
针对DeepLabV3+模型因使用不同膨胀率空洞卷积导致复杂度高及部分类别分割精度低的问题,提出一种融合进化式嵌套感受野(ENRF)模块与自适应类别通道注意力(ACCA)机制的改进方法。该方法将原有空洞空间卷积池化金字塔(ASPP)模块替换为ENRF模块,并在融合特征中引入ACCA机制,实现了感受野的连续拓展与更精细化的特征表达,同时降低了参数量和计算开销,提升了模型的轻量化水平。首先,ACCA机制通过融合通道自适应注意力与类别自适应2种注意力机制,挖掘通道间和类别间的特征依赖关系,提升特征图中关键信息的表达能力;其次,ENRF模块引入不同大小和不同膨胀率的卷积核,构建了一种基于嵌套感受野演化的网络结构,以扩大特征图的感受野,捕捉多尺度的上下文信息及细粒度的边缘特征。与全卷积网络(FCN8s)、金字塔场景解析网络(PSPNet)、统一感知解析网络(UPerNet)、双向分割网络(BiSeNet V2)、深度特征聚合网络(DFANet)以及原始DeepLabV3+在浮点运算次数(FLOPs)、参数量、均值交并比(mIoU)、推理速度和内存占用5个指标上进行对比实验的结果表明,改进后的DeepLabV3+方法在减少参数量和FLOPs的同时,也提高了推理速度并改善了图像分割性能。
中图分类号:
邢长征, 郑鑫, 贾迪, 梁浚锋. 基于自适应注意力与嵌套感受野改进DeepLabV3+方法[J]. 计算机应用, 2026, 46(5): 1408-1415.
Changzheng XING, Xin ZHENG, Di JIA, Junfeng LIANG. Improved DeepLabV3+ method based on adaptive attention and nested receptive field[J]. Journal of Computer Applications, 2026, 46(5): 1408-1415.
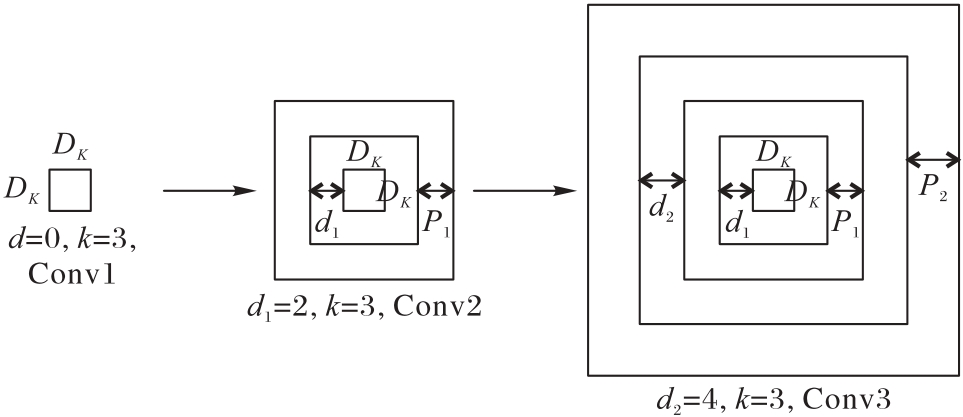
图1 基于卷积核的填充嵌套感受野结构
Fig. 1 Structure of filled nested receptive field based on convolution kernel
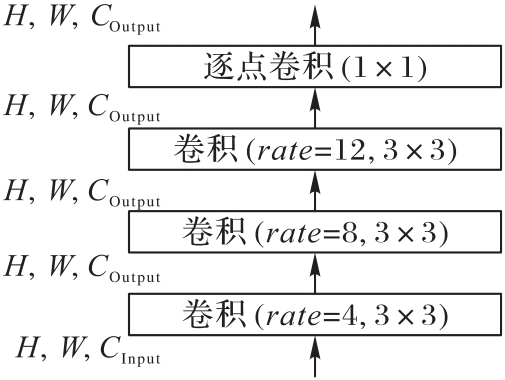
图2 ENRF模块结构
Fig. 2 ENRF module structure

图3 基于类别引导与通道加权的ACCA模块结构
Fig. 3 ACCA module structure based on class guidance and channel weighting
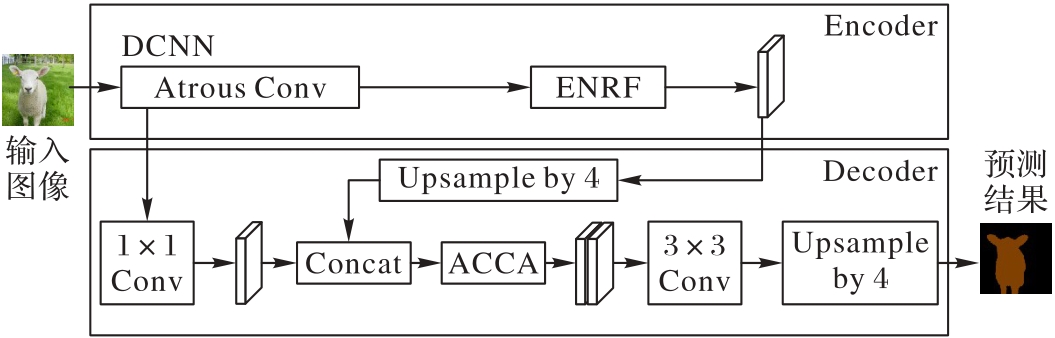
图4 引入ENRF与ACCA的改进型DeepLabV3+架构
Fig. 4 Improved DeepLabV3+ structure with ENRF and ACCA
| 算法 | 骨干 | VOC 2012 | Cityscapes | ||||
|---|---|---|---|---|---|---|---|
| GFLOPs | Params/106 | mIoU | GFLOPs | Params/106 | mIoU | ||
| FCN8s | VGG16 | 1 843.42 | 134.36 | 0.428 8 | 1 953.42 | 134.36 | 0.431 0 |
| PSPNet | ResNet101 | 2 102.23 | 65.00 | 0.573 0 | 2 299.80 | 65.00 | 0.579 4 |
| UPerNet | Resnet50 | 1 464.55 | 126.58 | 0.546 0 | 1 583.99 | 126.58 | 0.551 1 |
| BiSeNet V2 | — | 58.68 | 49.00 | 0.586 7 | 55.36 | 49.00 | 0.592 5 |
| DFANet | — | 3.67 | 7.80 | 0.571 9 | 3.48 | 7.80 | 0.580 1 |
| DeepLabV3+ | MobileNetV2 | 15.89 | 6.00 | 0.596 6 | 5.66 | 6.00 | 0.602 8 |
| DeepLabV3+ENRF+ACCA | MobileNetV2 | 13.08 | 5.22 | 0.611 2 | 4.04 | 5.22 | 0.628 3 |
表1 不同算法在VOC 2012和Cityscapes数据集上的语义分割性能对比
Tab. 1 Comparison of semantic segmentation performance of different algorithms on VOC 2012 and Cityscapes datasets
| 算法 | 骨干 | VOC 2012 | Cityscapes | ||||
|---|---|---|---|---|---|---|---|
| GFLOPs | Params/106 | mIoU | GFLOPs | Params/106 | mIoU | ||
| FCN8s | VGG16 | 1 843.42 | 134.36 | 0.428 8 | 1 953.42 | 134.36 | 0.431 0 |
| PSPNet | ResNet101 | 2 102.23 | 65.00 | 0.573 0 | 2 299.80 | 65.00 | 0.579 4 |
| UPerNet | Resnet50 | 1 464.55 | 126.58 | 0.546 0 | 1 583.99 | 126.58 | 0.551 1 |
| BiSeNet V2 | — | 58.68 | 49.00 | 0.586 7 | 55.36 | 49.00 | 0.592 5 |
| DFANet | — | 3.67 | 7.80 | 0.571 9 | 3.48 | 7.80 | 0.580 1 |
| DeepLabV3+ | MobileNetV2 | 15.89 | 6.00 | 0.596 6 | 5.66 | 6.00 | 0.602 8 |
| DeepLabV3+ENRF+ACCA | MobileNetV2 | 13.08 | 5.22 | 0.611 2 | 4.04 | 5.22 | 0.628 3 |
| 算法 | 骨干 | GTX 1050 | GTX 1660 Ti | ||
|---|---|---|---|---|---|
| 推理时间/ms | 内存占用/MB | 推理时间/ms | 内存占用/MB | ||
| FCN8s | VGG16 | 1.834 0 | 2 678.086 0 | 0.946 4 | 3 488.108 6 |
| PSPNet | ResNet101 | 10.045 0 | 4 557.440 3 | 1.002 0 | 4 557.440 8 |
| UPerNet | Resnet50 | 1.956 6 | 2 131.594 8 | 0.658 6 | 3 235.591 5 |
| DeepLabV3+ | MobileNetV2 | 0.394 4 | 811.024 5 | 0.091 4 | 1 953.716 8 |
| DeepLabV3+ENRF+ACCA | MobileNetV2 | 0.287 0 | 809.990 3 | 0.088 0 | 1 950.961 3 |
表2 VOC 2012数据集上轻量化模型性能对比
Tab. 2 Performance comparison of lightweight models on VOC 2012 Dataset
| 算法 | 骨干 | GTX 1050 | GTX 1660 Ti | ||
|---|---|---|---|---|---|
| 推理时间/ms | 内存占用/MB | 推理时间/ms | 内存占用/MB | ||
| FCN8s | VGG16 | 1.834 0 | 2 678.086 0 | 0.946 4 | 3 488.108 6 |
| PSPNet | ResNet101 | 10.045 0 | 4 557.440 3 | 1.002 0 | 4 557.440 8 |
| UPerNet | Resnet50 | 1.956 6 | 2 131.594 8 | 0.658 6 | 3 235.591 5 |
| DeepLabV3+ | MobileNetV2 | 0.394 4 | 811.024 5 | 0.091 4 | 1 953.716 8 |
| DeepLabV3+ENRF+ACCA | MobileNetV2 | 0.287 0 | 809.990 3 | 0.088 0 | 1 950.961 3 |

图5 不同模型在VOC 2012上的分割结果可视化对比
Fig. 5 Visual comparison of segmentation results of different model on VOC 2012 dataset
| 算法 | 骨干 | VOC 2012 | Cityscapes | ||||
|---|---|---|---|---|---|---|---|
| GFLOPs | Params/106 | mIoU | GFLOPs | Params/106 | mIoU | ||
| DeepLabV3+ ACCA | MobileNetV2 | 16.78 | 6.38 | 0.602 3 | 5.98 | 6.38 | 0.617 2 |
| DeepLabV3+ ENRF | MobileNetV2 | 12.64 | 5.84 | 0.582 2 | 3.64 | 5.84 | 0.596 3 |
| DeepLabV3+ | Xception | 40.56 | 37.05 | 0.631 7 | 10.70 | 37.05 | 0.623 2 |
| DeepLabV3+ENRF+ACCA | Xception | 34.89 | 28.48 | 0.649 8 | 9.40 | 28.48 | 0.631 1 |
| DeepLabV3+ | ResNet101 | 66.74 | 58.75 | 0.692 0 | 15.34 | 58.75 | 0.673 1 |
| DeepLabV3+ENRF+ACCA | ResNet101 | 58.85 | 49.19 | 0.708 4 | 14.28 | 49.19 | 0.695 1 |
表3 VOC 2012和Cityscapes数据集上消融实验的语义分割性能对比
Tab. 3 Semantic segmentation performance comparison of ablation experiments on VOC 2012 dataset
| 算法 | 骨干 | VOC 2012 | Cityscapes | ||||
|---|---|---|---|---|---|---|---|
| GFLOPs | Params/106 | mIoU | GFLOPs | Params/106 | mIoU | ||
| DeepLabV3+ ACCA | MobileNetV2 | 16.78 | 6.38 | 0.602 3 | 5.98 | 6.38 | 0.617 2 |
| DeepLabV3+ ENRF | MobileNetV2 | 12.64 | 5.84 | 0.582 2 | 3.64 | 5.84 | 0.596 3 |
| DeepLabV3+ | Xception | 40.56 | 37.05 | 0.631 7 | 10.70 | 37.05 | 0.623 2 |
| DeepLabV3+ENRF+ACCA | Xception | 34.89 | 28.48 | 0.649 8 | 9.40 | 28.48 | 0.631 1 |
| DeepLabV3+ | ResNet101 | 66.74 | 58.75 | 0.692 0 | 15.34 | 58.75 | 0.673 1 |
| DeepLabV3+ENRF+ACCA | ResNet101 | 58.85 | 49.19 | 0.708 4 | 14.28 | 49.19 | 0.695 1 |
| 算法 | 骨干 | GTX 1050 | GTX 1660 Ti | ||
|---|---|---|---|---|---|
| 推理时间/ms | 内存占用/MB | 推理时间/ms | 内存占用/MB | ||
| DeepLabV3+ ACCA | MobileNetV2 | 0.425 8 | 812.208 6 | 0.098 9 | 1 954.867 2 |
| DeepLabV3+ | Xception | 0.765 4 | 1 234.495 3 | 0.236 8 | 2 160.974 8 |
| DeepLabV3+ | ResNet101 | 1.050 1 | 1 197.440 1 | 0.385 0 | 2 423.231 0 |
| DeepLabV3+ENRF+ACCA | Xception | 0.656 2 | 1 213.571 2 | 0.215 8 | 2 123.925 6 |
| DeepLabV3+ENRF+ACCA | ResNet101 | 0.960 9 | 1 182.038 1 | 0.343 6 | 2 386.553 9 |
表4 VOC 2012数据集上轻量化模型消融实验性能对比
Tab. 4 Performance comparison of ablation experiments for lightweight models on VOC 2012 dataset
| 算法 | 骨干 | GTX 1050 | GTX 1660 Ti | ||
|---|---|---|---|---|---|
| 推理时间/ms | 内存占用/MB | 推理时间/ms | 内存占用/MB | ||
| DeepLabV3+ ACCA | MobileNetV2 | 0.425 8 | 812.208 6 | 0.098 9 | 1 954.867 2 |
| DeepLabV3+ | Xception | 0.765 4 | 1 234.495 3 | 0.236 8 | 2 160.974 8 |
| DeepLabV3+ | ResNet101 | 1.050 1 | 1 197.440 1 | 0.385 0 | 2 423.231 0 |
| DeepLabV3+ENRF+ACCA | Xception | 0.656 2 | 1 213.571 2 | 0.215 8 | 2 123.925 6 |
| DeepLabV3+ENRF+ACCA | ResNet101 | 0.960 9 | 1 182.038 1 | 0.343 6 | 2 386.553 9 |
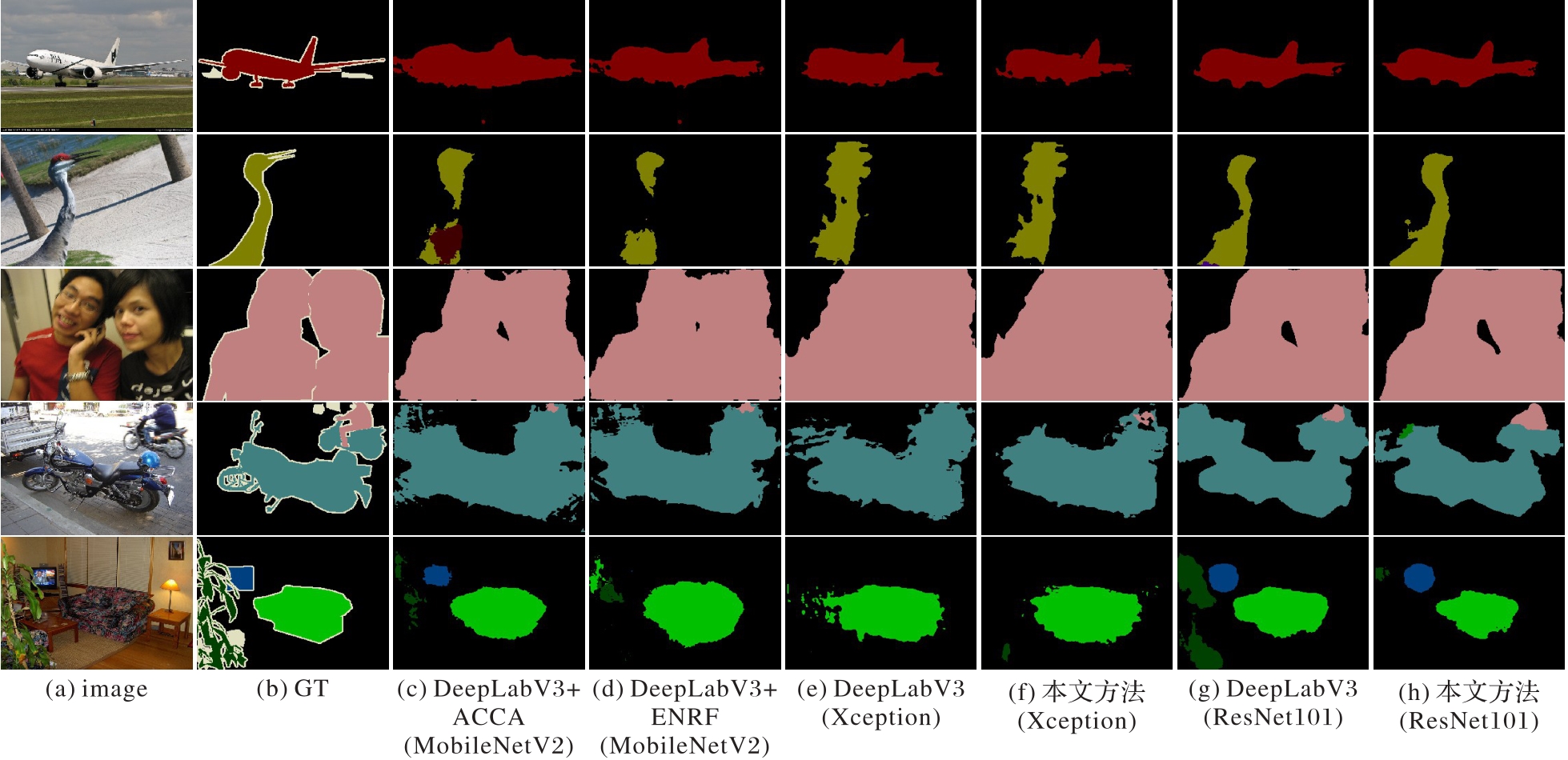
图6 VOC 2012数据集上消融实验的分割结果可视化对比
Fig. 6 Visual comparison of segmentation results for ablation experiments on VOC 2012 dataset
| [1] | 王碧瑶,韩毅,崔航滨,等.基于图像的道路语义分割检测方法[J].山东大学学报(工学版),2023,53(5):37-47. |
| WANG B Y, HAN Y, CUI H B, et al. Road semantic segmentation detection method based on image[J]. Journal of Shandong University (Engineering Science), 2023, 53(5): 37-47. | |
| [2] | 刘云翔,管钎汛,石艳娇.基于语义分割的复杂驾驶场景障碍物检测[J].计算机仿真,2023,40(12):167-171. |
| LIU Y X, GUAN Q X, SHI Y J. Obstacle detection in complex driving scenarios based on semantic segmentation[J]. Computer Simulation, 2023, 40(12): 167-171. | |
| [3] | 宋建丽,吕晓琪,谷宇.语义流引导采样结合注意力机制的脑肿瘤图像分割[J].光学精密工程,2024,32(4):565-577. |
| SONG J L, LYU X Q, GU Y. Brain tumor image segmentation based on semantic flow guided sampling and attention mechanism[J]. Optics and Precision Engineering, 2024, 32(4): 565-577. | |
| [4] | 汪华登,王雪馨,黎兵兵,等.GZMH:用于有丝分裂细胞核检测和分割的乳腺癌病理图像数据集[J].中国图象图形学报,2024,29(3):608-619. |
| WANG H D, WANG X X, LI B B, et al. GZMH: a dataset of breast cancer pathological images for mitosis nuclei detection and segmentation[J]. Journal of Image and Graphics, 2024, 29(3): 608-619. | |
| [5] | 王雅丽.基于改进Swin-Unet腹部多器官图像分割方法研究[J].现代计算机,2023,29(3):81-84. |
| WANG Y L. Research on abdominal multi organ image segmentation based on improved Swin-Unet[J]. Modern Computer, 2023, 29(3): 81-84. | |
| [6] | 彭明,丁汉泽,刘艳芳,等.解耦融合机制的金属表面缺陷小样本分割网络[J].闽南师范大学学报(自然科学版),2024,37(3): 57-70. |
| PENG M, DING H Z, LIU Y F, et al. Decoupling fusion mechanism-based network for metal surface defect few-shot segmentation[J]. Journal of Minnan Normal University (Natural Science), 2024, 37(3): 57-70. | |
| [7] | LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3431-3440. |
| [8] | YEGNANARAYANA B. Artificial neural networks[M]. Delhi: PHI Learning Pvt. Ltd., 2004: 1-2. |
| [9] | RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241. |
| [10] | ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6230-6239. |
| [11] | CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. |
| [12] | KRÄHENBÜHL P, KOLTUN V. Efficient inference in fully connected CRFs with Gaussian edge potentials[C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2011: 109-117. |
| [13] | CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 833-851. |
| [14] | LIU R, TAO F, LIU X, et al. RAANet: a residual ASPP with attention framework for semantic segmentation of high-resolution remote sensing images[J]. Remote Sensing, 2022, 14(13): No.3109. |
| [15] | SUN X, ZHANG Y, CHEN C, et al. High-order paired-ASPP for deep semantic segmentation networks[J]. Information Sciences, 2023, 646: No.119364. |
| [16] | XI Y, LI S, XU Z, et al. LapUNet: a novel approach to monocular depth estimation using dynamic Laplacian residual U‑shape networks[J]. Scientific Reports, 2024, 14: No.23544. |
| [17] | DING P, QIAN H, ZHOU Y, et al. Real-time efficient semantic segmentation network based on improved ASPP and parallel fusion module in complex scenes[J]. Journal of Real-Time Image Processing, 2023, 20(3): No.41. |
| [18] | LI Y, YUAN G, WEN Y, et al. EfficientFormer: Vision Transformers at MobileNet speed[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 12934-12949. |
| [19] | LIDA T, KOMATSU T, KANEDA K, et al. Visual explanation generation based on lambda attention branch networks[C]// Proceedings of the 2022 Asian Conference on Computer Vision, LNCS 13842. Cham: Springer, 2023: 475-490. |
| [20] | SHAKER A, MAAZ M, RASHEED H, et al. SwiftFormer: efficient additive attention for Transformer-based real-time mobile vision applications[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 17379-17390. |
| [21] | FENG X, DU H, FAN H, et al. SEFormer: structure embedding Transformer for 3D object detection[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 632-640. |
| [22] | HENDRYCKS D, GIMPEL K. Gaussian Error Linear Units (GELUs)[EB/OL]. [2025-04-11].. |
| [23] | EVERINGHAM M, ESLAMI S M A, VAN GOOL L, et al. The PASCAL visual object classes challenge: a retrospective[J]. International Journal of Computer Vision, 2015, 111(1): 98-136. |
| [24] | CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 3213-3223. |
| [25] | XIAO T, LIU Y, ZHOU B, et al. Unified perceptual parsing for scene understanding[C]// Proceedings of the 2018 European Conference on Computer Vision. Berlin: Springer, 2018: 418-434. |
| [26] | YU C, GAO C, WANG J, et al. BiSeNet V2: bilateral network with guided aggregation for real-time semantic segmentation[J]. International Journal of Computer Vision, 2021, 129: 3051-3068. |
| [27] | LI H, XIONG P, FAN H, et al. Dfanet: Deep feature aggregation for real-time semantic segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 9522-9531. |
| [28] | CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1800-1807. |
| [29] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [1] | 于银山, 唐旭, 丁明鉴, 黄文凯, 毕嘉文, 谭国辰. 基于YOLOv10的实时车辆检测算法[J]. 《计算机应用》唯一官方网站, 2026, 46(3): 950-958. |
| [2] | 黄萍, 李清, 邱海枫, 王程斯, 黄安子, 张翔. 基于头部骨骼点检测的实时人脸打码方法[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 596-603. |
| [3] | 曹柠, 温昕, 郝雁嵘, 曹锐. 多域特征融合的轻量化运动想象脑电信号解码神经网络[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 289-296. |
| [4] | 崔家礼, 刘永基, 李子贺, 郑瀚. 轻量且高精度增强的姿态检测网络HG-YOLO[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 4004-4011. |
| [5] | 邓酩, 徐锦凡, 肖洪祥, 谢晓兰. 改进TransUNet的高效通道注意力医学图像分割网络[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 4037-4044. |
| [6] | 文连庆, 陶冶, 田云龙, 牛丽, 孙宏霞. 基于流的轻量化高质量文本到语音转换方法[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3277-3283. |
| [7] | 李卓然, 李华, 王桐, 蒋朝哲. 基于融合特征状态空间模型的轻量化人体姿态估计[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3179-3186. |
| [8] | 张勇进, 徐健, 张明星. 面向轻量化的改进YOLOv7棉杂检测算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2271-2278. |
| [9] | 程小辉, 黄云天, 张瑞芳. 基于多尺度和加权坐标注意力的轻量化红外道路场景检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1927-1934. |
| [10] | 宋霄罡, 张冬冬, 张鹏飞, 梁莉, 黑新宏. 面向复杂施工环境的实时目标检测算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1605-1612. |
| [11] | 耿焕同, 刘振宇, 蒋骏, 范子辰, 李嘉兴. 基于改进YOLOv8的嵌入式道路裂缝检测算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1613-1618. |
| [12] | 黄子杰, 欧阳, 江德港, 郭彩玲, 李柏林. 面向牵引座焊缝表面质量检测的轻量型深度学习算法[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 983-988. |
| [13] | 张成涵宇, 林钰哲, 谭程珂, 王俊帆, 顾烨婷, 董哲康, 高明煜. 基于轻量化YOLOv5的新型菜品识别网络[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 638-644. |
| [14] | 陈姿芊, 牛科迪, 姚中原, 斯雪明. 适用于物联网的区块链轻量化技术综述[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3688-3698. |
| [15] | 赵欣, 李鑫杰, 徐健, 刘步云, 毕祥. 基于卷积神经网络与Transformer并行的医学图像配准模型[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3915-3921. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||