


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (10): 3018-3024.DOI: 10.11772/j.issn.1001-9081.2021091622
所属专题: 人工智能
刘长红1, 曾胜1, 张斌1, 陈勇2
收稿日期:2021-09-14
修回日期:2021-12-20
接受日期:2021-12-30
发布日期:2022-10-14
出版日期:2022-10-10
通讯作者:
刘长红
作者简介:第一联系人:刘长红(1977—),女,江西南丰人,副教授,博士,CCF会员,主要研究方向:计算机视觉、跨模态信息检索、高光谱图像处理; liuch@jxnu.edu.cn基金资助:Changhong LIU1, Sheng ZENG1, Bin ZHANG1, Yong CHEN2
Received:2021-09-14
Revised:2021-12-20
Accepted:2021-12-30
Online:2022-10-14
Published:2022-10-10
Contact:
Changhong LIU
About author:LIU Changhong, born in 1977, Ph. D. , associate professor. Her research interests include computer vision, cross-modal information retrieval, hyper-spectral image processing.Supported by:摘要:
跨模态图像文本检索的难点是如何有效地学习图像和文本间的语义相关性。现有的大多数方法都是学习图像区域特征和文本特征的全局语义相关性或模态间对象间的局部语义相关性,而忽略了模态内对象之间的关系和模态间对象关系的关联。针对上述问题,提出了一种基于语义关系图的跨模态张量融合网络(CMTFN-SRG)的图像文本检索方法。首先,采用图卷积网络(GCN)学习图像区域间的关系并使用双向门控循环单元(Bi-GRU)构建文本单词间的关系;然后,将所学习到的图像区域和文本单词间的语义关系图通过张量融合网络进行匹配以学习两种不同模态数据间的细粒度语义关联;同时,采用门控循环单元(GRU)学习图像的全局特征,并将图像和文本的全局特征进行匹配以捕获模态间的全局语义相关性。将所提方法在Flickr30K和MS-COCO两个基准数据集上与多模态交叉注意力(MMCA)方法进行了对比分析。实验结果表明,所提方法在Flickr30K测试集、MS-COCO1K测试集以及MS-COCO5K测试集上文本检索图像任务的Recall@1分别提升了2.6%、9.0%和4.1%,召回率均值(mR)分别提升了0.4、1.3和0.1个百分点,可见该方法能有效提升图像文本检索的精度。
中图分类号:
刘长红, 曾胜, 张斌, 陈勇. 基于语义关系图的跨模态张量融合网络的图像文本检索[J]. 计算机应用, 2022, 42(10): 3018-3024.
Changhong LIU, Sheng ZENG, Bin ZHANG, Yong CHEN. Cross-modal tensor fusion network based on semantic relation graph for image-text retrieval[J]. Journal of Computer Applications, 2022, 42(10): 3018-3024.

图1 两种不同细粒度匹配方法示意图
Fig. 1 Schematic diagrams of two fine-grained matching methods

图2 本文模型架构
Fig. 2 Architecture of the proposed model
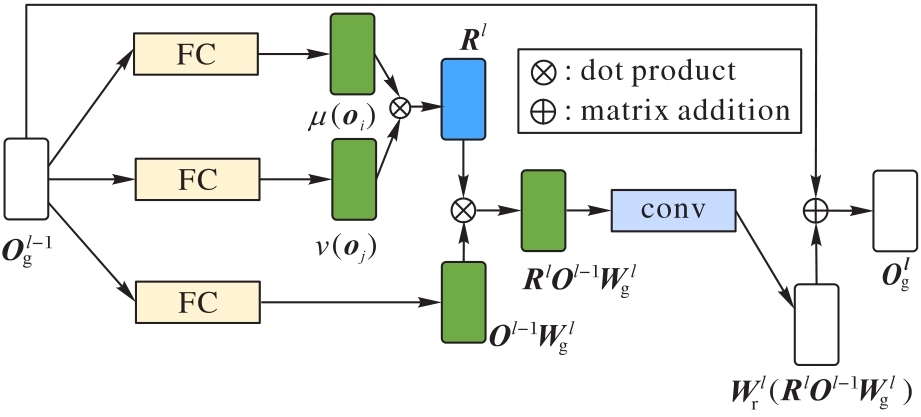
图3 带有残差连接的GCN结构
Fig. 3 Structure of GCN with residual connection

图4 Bi-GRU词向量处理流程
Fig. 4 Processing flow of Bi-GRU word vector
| 数据集 | 样本数 | 总样本数 | ||
|---|---|---|---|---|
| 训练集数 | 验证集数 | 测试集数 | ||
| MS-COCO | 113 287 | 5 000 | 5 000 | 123 287 |
| Flickr30K | 28 000 | 1 000 | 1 000 | 31 783 |
表1 两个常用的基准数据集
Tab. 1 Two commonly used benchmark datasets
| 数据集 | 样本数 | 总样本数 | ||
|---|---|---|---|---|
| 训练集数 | 验证集数 | 测试集数 | ||
| MS-COCO | 113 287 | 5 000 | 5 000 | 123 287 |
| Flickr30K | 28 000 | 1 000 | 1 000 | 31 783 |
| 方法 | 图像检索文本 | 文本检索图像 | mR | ||||
|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| RRF[ | 47.6 | 77.4 | 87.1 | 35.4 | 68.3 | 79.9 | 65.9 |
| VSE++[ | 52.9 | 79.1 | 87.2 | 39.6 | 69.6 | 79.5 | 67.9 |
| DPC[ | 55.6 | 81.9 | 89.5 | 39.1 | 69.2 | 80.9 | 69.3 |
| SCO[ | 55.5 | 82.0 | 89.3 | 41.1 | 70.5 | 88.1 | 71.0 |
| SCAN[ | 67.4 | 90.3 | 95.8 | 48.6 | 77.7 | 85.2 | 77.5 |
| MTFN[ | 65.3 | 88.3 | 93.3 | 52.0 | 80.1 | 86.1 | 77.5 |
| VSRN[ | 71.3 | 90.6 | 96.0 | 54.7 | 81.8 | 88.2 | 80.4 |
| MMCA[ | 74.2 | 92.8 | 96.4 | 54.8 | 81.4 | 87.8 | 81.2 |
| CMTFN-SRG | 73.6 | 91.7 | 96.3 | 56.2 | 82.5 | 89.4 | 81.6 |
表2 Flickr30K测试集上的召回率对比结果 (%)
Tab. 2 Recall comparison results on Flickr30K test set
| 方法 | 图像检索文本 | 文本检索图像 | mR | ||||
|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| RRF[ | 47.6 | 77.4 | 87.1 | 35.4 | 68.3 | 79.9 | 65.9 |
| VSE++[ | 52.9 | 79.1 | 87.2 | 39.6 | 69.6 | 79.5 | 67.9 |
| DPC[ | 55.6 | 81.9 | 89.5 | 39.1 | 69.2 | 80.9 | 69.3 |
| SCO[ | 55.5 | 82.0 | 89.3 | 41.1 | 70.5 | 88.1 | 71.0 |
| SCAN[ | 67.4 | 90.3 | 95.8 | 48.6 | 77.7 | 85.2 | 77.5 |
| MTFN[ | 65.3 | 88.3 | 93.3 | 52.0 | 80.1 | 86.1 | 77.5 |
| VSRN[ | 71.3 | 90.6 | 96.0 | 54.7 | 81.8 | 88.2 | 80.4 |
| MMCA[ | 74.2 | 92.8 | 96.4 | 54.8 | 81.4 | 87.8 | 81.2 |
| CMTFN-SRG | 73.6 | 91.7 | 96.3 | 56.2 | 82.5 | 89.4 | 81.6 |
| 方法 | 图像检索文本 | 文本检索图像 | mR | ||||
|---|---|---|---|---|---|---|---|
| R @1 | R @5 | R@10 | R @1 | R @5 | R @10 | ||
| VSE++[ | 41.3 | 69.2 | 81.2 | 30.3 | 59.1 | 72.4 | 58.9 |
| DPC[ | 41.2 | 70.5 | 81.1 | 25.3 | 53.4 | 66.4 | 56.3 |
| SCO[ | 42.8 | 72.3 | 83.0 | 33.1 | 62.9 | 75.5 | 61.6 |
| SCAN[ | 50.4 | 82.2 | 90.0 | 38.6 | 69.3 | 80.4 | 68.4 |
| MTFN[ | 48.3 | 77.6 | 87.3 | 35.9 | 66.1 | 76.1 | 65.2 |
| VSRN[ | 53.0 | 81.1 | 89.4 | 40.5 | 70.6 | 81.1 | 69.2 |
| MMCA[ | 54.0 | 82.5 | 90.7 | 38.7 | 69.7 | 80.8 | 69.4 |
| CMTFN-SRG | 53.0 | 81.5 | 89.7 | 40.3 | 71.0 | 81.7 | 69.5 |
表3 在MS-COCO5K 测试集上的召回率对比结果 (%)
Tab. 3 Recall comparison results on MS-COCO5K test set
| 方法 | 图像检索文本 | 文本检索图像 | mR | ||||
|---|---|---|---|---|---|---|---|
| R @1 | R @5 | R@10 | R @1 | R @5 | R @10 | ||
| VSE++[ | 41.3 | 69.2 | 81.2 | 30.3 | 59.1 | 72.4 | 58.9 |
| DPC[ | 41.2 | 70.5 | 81.1 | 25.3 | 53.4 | 66.4 | 56.3 |
| SCO[ | 42.8 | 72.3 | 83.0 | 33.1 | 62.9 | 75.5 | 61.6 |
| SCAN[ | 50.4 | 82.2 | 90.0 | 38.6 | 69.3 | 80.4 | 68.4 |
| MTFN[ | 48.3 | 77.6 | 87.3 | 35.9 | 66.1 | 76.1 | 65.2 |
| VSRN[ | 53.0 | 81.1 | 89.4 | 40.5 | 70.6 | 81.1 | 69.2 |
| MMCA[ | 54.0 | 82.5 | 90.7 | 38.7 | 69.7 | 80.8 | 69.4 |
| CMTFN-SRG | 53.0 | 81.5 | 89.7 | 40.3 | 71.0 | 81.7 | 69.5 |
| 方法 | 图像检索文本 | 文本检索图像 | mR | ||||
|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| RRF[ | 56.4 | 85.3 | 91.5 | 43.9 | 78.1 | 88.6 | 73.9 |
| VSE++[ | 64.6 | 89.1 | 95.7 | 52.0 | 83.1 | 92.0 | 79.4 |
| DPC[ | 65.6 | 89.8 | 95.5 | 47.1 | 79.9 | 90.0 | 77.9 |
| SCO[ | 69.9 | 92.9 | 97.5 | 56.7 | 87.5 | 94.8 | 83.2 |
| SCAN[ | 72.7 | 94.8 | 98.2 | 58.8 | 88.4 | 94.8 | 84.6 |
| MTFN[ | 74.3 | 94.9 | 97.9 | 60.1 | 89.1 | 95.0 | 85.2 |
| VSRN[ | 76.2 | 94.8 | 98.2 | 62.8 | 89.7 | 95.1 | 86.1 |
| MMCA[ | 74.8 | 95.6 | 97.7 | 57.8 | 88.6 | 94.9 | 84.9 |
| CMTFN-SRG | 75.6 | 95.2 | 98.3 | 63.0 | 90.0 | 95.4 | 86.2 |
表4 MS-COCO1K测试集上的召回率对比结果 (%)
Tab. 4 Recall comparison results on MS-COCO1K test set
| 方法 | 图像检索文本 | 文本检索图像 | mR | ||||
|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| RRF[ | 56.4 | 85.3 | 91.5 | 43.9 | 78.1 | 88.6 | 73.9 |
| VSE++[ | 64.6 | 89.1 | 95.7 | 52.0 | 83.1 | 92.0 | 79.4 |
| DPC[ | 65.6 | 89.8 | 95.5 | 47.1 | 79.9 | 90.0 | 77.9 |
| SCO[ | 69.9 | 92.9 | 97.5 | 56.7 | 87.5 | 94.8 | 83.2 |
| SCAN[ | 72.7 | 94.8 | 98.2 | 58.8 | 88.4 | 94.8 | 84.6 |
| MTFN[ | 74.3 | 94.9 | 97.9 | 60.1 | 89.1 | 95.0 | 85.2 |
| VSRN[ | 76.2 | 94.8 | 98.2 | 62.8 | 89.7 | 95.1 | 86.1 |
| MMCA[ | 74.8 | 95.6 | 97.7 | 57.8 | 88.6 | 94.9 | 84.9 |
| CMTFN-SRG | 75.6 | 95.2 | 98.3 | 63.0 | 90.0 | 95.4 | 86.2 |
| 方法 | 图像检索文本 | 文本检索图像 | ||
|---|---|---|---|---|
| R@1 | R@10 | R@1 | R@10 | |
| Avg-pool(基线模型) | 64.3 | 90.5 | 49.2 | 83.4 |
| IR | 74.0 | 94.2 | 61.3 | 89.8 |
| 10TF+IR | 74.4 | 94.6 | 61.4 | 90.0 |
| 20TF+IR | 75.6 | 95.2 | 63.0 | 90.0 |
| 30TF+IR | 74.2 | 94.4 | 61.8 | 89.9 |
表5 在MS-COCO1K测试集上进行消融实验的结果 (%)
Tab. 5 Ablation experimental results on MS-COCO1K test set
| 方法 | 图像检索文本 | 文本检索图像 | ||
|---|---|---|---|---|
| R@1 | R@10 | R@1 | R@10 | |
| Avg-pool(基线模型) | 64.3 | 90.5 | 49.2 | 83.4 |
| IR | 74.0 | 94.2 | 61.3 | 89.8 |
| 10TF+IR | 74.4 | 94.6 | 61.4 | 90.0 |
| 20TF+IR | 75.6 | 95.2 | 63.0 | 90.0 |
| 30TF+IR | 74.2 | 94.4 | 61.8 | 89.9 |

图5 文本检索图像的结果
Fig. 5 Image retrieval results by using texts

图6 图像检索文本的结果
Fig. 6 Text retrieval results by using images
| 1 | HUANG Y, WANG W, WANG L. Instance-aware image and sentence matching with selective multimodal LSTM[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 7254-7262. 10.1109/cvpr.2017.767 |
| 2 | KIROS R, SALAKHUTDINOV R, ZEMEL R S. Unifying visual-semantic embeddings with multimodal neural language models[EB/OL]. (2014-11-10) [2021-08-03].. |
| 3 | 邓一姣,张凤荔,陈学勤,等. 面向跨模态检索的协同注意力网络模型[J]. 计算机科学, 2020, 47(4): 54-59. 10.11896/jsjkx.190600181 |
| DENG Y J, ZHANG F L, CHEN X Q, et al. Collaborative attention network modal for cross-modal retrieval[J]. Computer Science, 2020, 47(4): 54-59. 10.11896/jsjkx.190600181 | |
| 4 | FAGHRI F, FLEET D J, KIROS J R, et al. VSE++: improving visual-semantic embeddings with hard negatives[C]// Proceedings of the 2018 British Machine Vision Conference. Durham: BMVA Press, 2018: No.344. |
| 5 | FROME A, CORRADO G S, SHLENS J, et al. DeViSE: a deep visual-semantic embedding model[C]// Proceedings of the 26th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2013: 2121-2129. |
| 6 | GU J X, CAI J F, JOTY S, et al. Look, imagine and match: improving textual-visual cross-modal retrieval with generative models[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7181-7189. 10.1109/cvpr.2018.00750 |
| 7 | KLEIN B, LEV G, SADEH G, et al. Associating neural word embeddings with deep image representations using Fisher vectors[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 4437-4446. 10.1109/cvpr.2015.7299073 |
| 8 | PENG Y X, QI J E. CM-GANs: cross-modal generative adversarial networks for common representation learning[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2019, 15(1): No.22. 10.1145/3284750 |
| 9 | YAN F, MIKOLAJCZYK K. Deep correlation for matching images and text[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3441-3450. 10.1109/cvpr.2015.7298966 |
| 10 | 黄育,张鸿. 基于潜语义主题加强的跨媒体检索算法[J]. 计算机应用, 2017, 37(4): 1061-1064, 1110. 10.11772/j.issn.1001-9081.2017.04.1061 |
| HUANG Y, ZHANG H. Cross-media retrieval based on latent semantic topic reinforce[J]. Journal of Computer Applications, 2017, 37(4): 1061-1064, 1110. 10.11772/j.issn.1001-9081.2017.04.1061 | |
| 11 | 严双咏,刘长红,江爱文,等. 语义耦合相关的判别式跨模态哈希学习算法[J]. 计算机学报, 2019, 42(1): 164-175. 10.11897/SP.J.1016.2019.00164 |
| YAN S Y, LIU C H, JIANG A W, et al. Discriminative cross-modal hashing with coupled semantic correlation[J]. Chinese Journal of Computers, 2019, 42(1): 164-175. 10.11897/SP.J.1016.2019.00164 | |
| 12 | KARPATHY A, LI F F. Deep visual-semantic alignments for generating image descriptions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3128-3137. 10.1109/cvpr.2015.7298932 |
| 13 | NIU Z X, ZHOU M, WANG L, et al. Hierarchical multimodal LSTM for dense visual-semantic embedding[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 1899-1907. 10.1109/iccv.2017.208 |
| 14 | NAM H, HA J W, KIM J. Dual attention networks for multimodal reasoning and matching[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2156-2164. 10.1109/cvpr.2017.232 |
| 15 | LEE K H, CHEN X, HUA G, et al. Stacked cross attention for image-text matching[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11208. Cham: Springer, 2018: 212-228. |
| 16 | LI K P, ZHANG Y L, LI K, et al. Visual semantic reasoning for image-text matching[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 4653-4661. 10.1109/iccv.2019.00475 |
| 17 | KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. (2017-02-22) [2021-06-20].. 10.48550/arXiv.1609.02907 |
| 18 | WEI X, ZHANG T Z, LI Y, et al. Multi-modality cross attention network for image and sentence matching[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10938-10947. 10.1109/cvpr42600.2020.01095 |
| 19 | CHUNG J, GULCEHRE C, CHO K, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[EB/OL]. (2014-12-11) [2021-06-20].. 10.1007/978-3-030-89929-5_3 |
| 20 | CHEN H, DING G G, LIU X D, et al. IMRAM: iterative matching with recurrent attention memory for cross-modal image-text retrieval[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 12652-12660. 10.1109/cvpr42600.2020.01267 |
| 21 | WANG L W, LI Y, LAZEBNIK S. Learning deep structure-preserving image-text embeddings[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 5005-5013. 10.1109/cvpr.2016.541 |
| 22 | LIU Y, GUO Y M, BAKKER E M, et al. Learning a recurrent residual fusion network for multimodal matching[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 4127-4136. 10.1109/iccv.2017.442 |
| 23 | REN S Q, HE K M, GIRSHICK R. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. 10.1109/tpami.2016.2577031 |
| 24 | ANDERSON P, HE X D, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6077-6086. 10.1109/cvpr.2018.00636 |
| 25 | KRISHNA R, ZHU Y, GROTH O, et al. Visual Genome: connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123(1): 32-73. 10.1007/s11263-016-0981-7 |
| 26 | VENUGOPALAN S, ROHRBACH M, DONAHUE J, et al. Sequence to sequence - video to text[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 4534-4542. 10.1109/iccv.2015.515 |
| 27 | ZHENG Z D, ZHENG L, GARRETT M, et al. Dual-path convolutional image-text embedding with instance loss[J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2020, 16(2): No.51. 10.1145/3383184 |
| 28 | HUANG Y, WU Q, SONG C F, et al. Learning semantic concepts and order for image and sentence matching[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6163-6171. 10.1109/cvpr.2018.00645 |
| 29 | WANG T, XU X, YANG Y, et al. Matching images and text with multi-modal tensor fusion and re-ranking[C]// Proceedings of the 27th ACM International Conference on Multimedia. New York: ACM, 2019: 12-20. 10.1145/3343031.3350875 |
| 30 | KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. (2017-01-30) [2021-08-03].. |
| [1] | 庞川林, 唐睿, 张睿智, 刘川, 刘佳, 岳士博. D2D通信系统中基于图卷积网络的分布式功率控制算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2855-2862. |
| [2] | 薛桂香, 王辉, 周卫峰, 刘瑜, 李岩. 基于知识图谱和时空扩散图卷积网络的港口交通流量预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2952-2957. |
| [3] | 刘禹含, 吉根林, 张红苹. 基于骨架图与混合注意力的视频行人异常检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2551-2557. |
| [4] | 李欢欢, 黄添强, 丁雪梅, 罗海峰, 黄丽清. 基于多尺度时空图卷积网络的交通出行需求预测[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2065-2072. |
| [5] | 吕锡婷, 赵敬华, 荣海迎, 赵嘉乐. 基于Transformer和关系图卷积网络的信息传播预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1760-1766. |
| [6] | 黎施彬, 龚俊, 汤圣君. 基于Graph Transformer的半监督异配图表示学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1816-1823. |
| [7] | 高龙涛, 李娜娜. 基于方面感知注意力增强的方面情感三元组抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1049-1057. |
| [8] | 杨先凤, 汤依磊, 李自强. 基于交替注意力机制和图卷积网络的方面级情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(4): 1058-1064. |
| [9] | 王楷天, 叶青, 程春雷. 基于异构图表示的中医电子病历分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 411-417. |
| [10] | 吴祖成, 吴小俊, 徐天阳. 基于模态内细粒度特征关系提取的图像文本检索模型[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3776-3783. |
| [11] | 梁睿衍, 杨慧. 基于RPEpose和XJ-GCN的轻量级跌倒检测算法框架[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3639-3646. |
| [12] | 王利琴, 张特, 许智宏, 董永峰, 杨国伟. 融合实体语义及结构信息的知识图谱推理[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3371-3378. |
| [13] | 胡新荣, 陈静雪, 黄子键, 王帮超, 姚迅, 刘军平, 朱强, 杨捷. 基于图卷积网络的掩码数据增强[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3335-3344. |
| [14] | 项能强, 朱小飞, 高肇泽. 原型感知双通道图卷积神经网络的信息传播预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3260-3266. |
| [15] | 李言博, 何庆, 陆顺意. 融合语义和句法信息的方面情感三元组抽取[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3275-3280. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||