


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (3): 815-822.DOI: 10.11772/j.issn.1001-9081.2024010013
鲁超峰1, 陶冶1( ), 文连庆1, 孟菲2, 秦修功3, 杜永杰4, 田云龙4
), 文连庆1, 孟菲2, 秦修功3, 杜永杰4, 田云龙4
收稿日期:2024-01-11
修回日期:2024-03-22
接受日期:2024-03-22
发布日期:2024-05-09
出版日期:2025-03-10
通讯作者:
陶冶
作者简介:鲁超峰(1999—),男,山东菏泽人,硕士,主要研究方向:语音合成、自然语言处理基金资助:
Chaofeng LU1, Ye TAO1(), Lianqing WEN1, Fei MENG2, Xiugong QIN3, Yongjie DU4, Yunlong TIAN4
Received:2024-01-11
Revised:2024-03-22
Accepted:2024-03-22
Online:2024-05-09
Published:2025-03-10
Contact:
Ye TAO
About author:LU Chaofeng, born in 1999, M. S. His research interests include speech synthesis, neural language processing.Supported by:摘要:
针对很少有人将说话人转换和情感转换结合起来研究,且实际场景中的目标说话人情感语料通常很少,不足以从头训练一个强泛化性模型的问题,提出一种融合大语言模型和预训练情感语音合成模型的少量语料说话人-情感语音转换(LSEVC)方法。首先,使用大语言模型生成带有所需情感标签的文本;其次,使用目标说话人语料微调预训练情感语音合成模型以嵌入目标说话人;然后,将生成的文本合成情感语音,以达到数据增强的目的;再次,使用合成语音与源目标语音共同训练说话人-情感语音转换模型;最后,为了进一步提升转换语音的说话人相似度和情感相似度,使用源目标说话人情感语音微调模型。在公共语料库和一个中文小说语料库上的实验结果表明,综合考虑评价指标情感相似度平均得分(EMOS)、说话人相似度平均意见得分(SMOS)、梅尔倒谱失真(MCD)和词错误率(WER)时,所提方法优于CycleGAN-EVC、Seq2Seq-EVC-WA2和SMAL-ET2等方法。
中图分类号:
鲁超峰, 陶冶, 文连庆, 孟菲, 秦修功, 杜永杰, 田云龙. 融合大语言模型和预训练模型的少量语料说话人-情感语音转换方法[J]. 计算机应用, 2025, 45(3): 815-822.
Chaofeng LU, Ye TAO, Lianqing WEN, Fei MENG, Xiugong QIN, Yongjie DU, Yunlong TIAN. Speaker-emotion voice conversion method with limited corpus based on large language model and pre-trained model[J]. Journal of Computer Applications, 2025, 45(3): 815-822.

图1 本文方法的流程
Fig. 1 Flow of proposed method

图2 数据增强实例
Fig. 2 Examples of data augmentation

图3 说话人-情感语音转换模型的结构
Fig. 3 Structure of speaker-emotion voice conversion model
| 语料库 | 语言 | 情感类别数 | 情感名称 | 训练集样本数 | 验证集样本数 | 测试集样本数 | 说话人数 |
|---|---|---|---|---|---|---|---|
| AISHELL-3 | 中文 | 1 | 中性 | 79 235 | 4 400 | 4 400 | 218 |
| LibriTTS | 英文 | 1 | 中性 | 26 590 | 3 323 | 3 323 | 251 |
| ESD | 中英混合 | 5 | 中性、快乐、愤怒、悲伤、惊喜 | 30 000 | 3 000 | 2 000 | 20 |
| EMONANA | 中文 | 5 | 中性、快乐、愤怒、悲伤、惊喜 | 150 | 15 | 15 | 1 |
表1 实验中使用的语料库
Tab. 1 Corpora used in experiments
| 语料库 | 语言 | 情感类别数 | 情感名称 | 训练集样本数 | 验证集样本数 | 测试集样本数 | 说话人数 |
|---|---|---|---|---|---|---|---|
| AISHELL-3 | 中文 | 1 | 中性 | 79 235 | 4 400 | 4 400 | 218 |
| LibriTTS | 英文 | 1 | 中性 | 26 590 | 3 323 | 3 323 | 251 |
| ESD | 中英混合 | 5 | 中性、快乐、愤怒、悲伤、惊喜 | 30 000 | 3 000 | 2 000 | 20 |
| EMONANA | 中文 | 5 | 中性、快乐、愤怒、悲伤、惊喜 | 150 | 15 | 15 | 1 |
| 分数 | SMOS标准 | EMOS标准 |
|---|---|---|
| [0,1) | 未知的说话人相似度 | 未知的情感相似度 |
| [1,2) | 模糊的说话人相似度 | 模糊的情感相似度 |
| [2,3) | 可接受的说话人相似度 | 可接受的情感相似度 |
| [3,4) | 乐意接受的说话人相似度 | 乐意接受的情感相似度 |
| [ | 理想的说话人相似度 | 理想的情感相似度 |
表2 SMOS和EMOS的评分标准
Tab. 2 Scoring criteria of SMOS and EMOS
| 分数 | SMOS标准 | EMOS标准 |
|---|---|---|
| [0,1) | 未知的说话人相似度 | 未知的情感相似度 |
| [1,2) | 模糊的说话人相似度 | 模糊的情感相似度 |
| [2,3) | 可接受的说话人相似度 | 可接受的情感相似度 |
| [3,4) | 乐意接受的说话人相似度 | 乐意接受的情感相似度 |
| [ | 理想的说话人相似度 | 理想的情感相似度 |
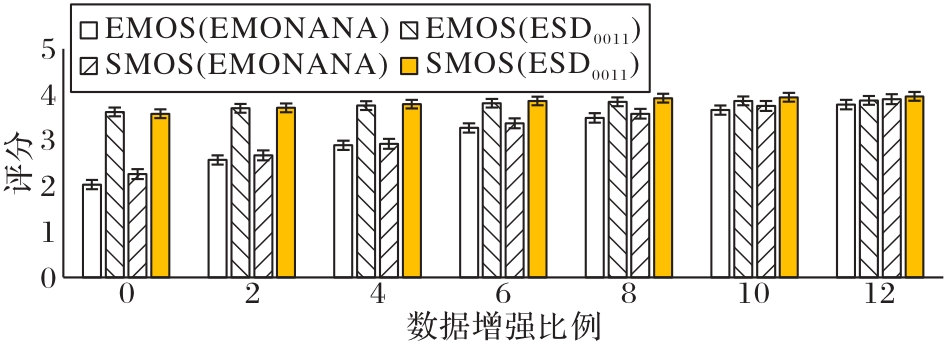
图4 数据增强比例对转换语音的影响
Fig. 4 Influence of data augmentation ratio on converted speech
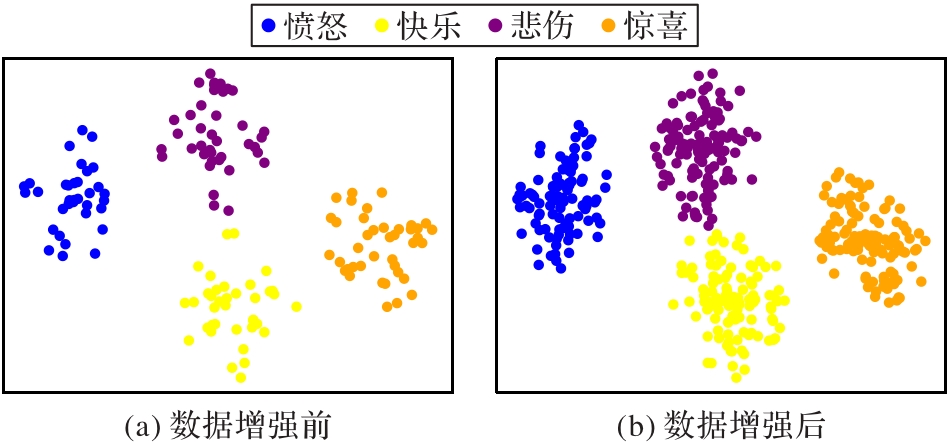
图5 数据增强前后的向量可视化
Fig. 5 Vector visualization before and after data augmentation
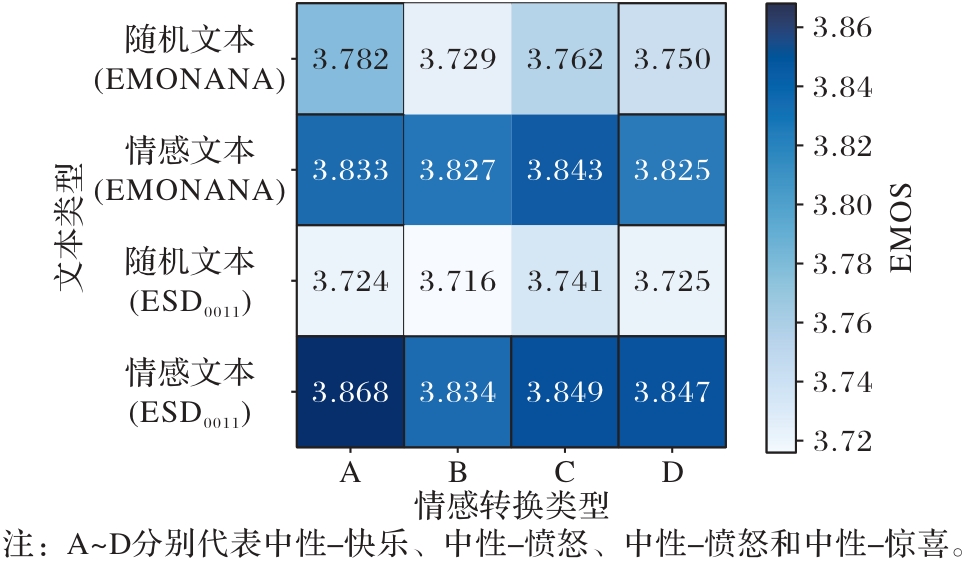
图6 增强数据文本情感对转换语音EMOS的影响
Fig. 6 Influence of augmented data’s text sentiment on EMOS of converted speech
| 方法 | SMOS | EMOS | MCD | WER/% | ||||
|---|---|---|---|---|---|---|---|---|
| EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | |
| B | 2.64±0.12 | 2.96±0.14 | 3.61±0.10 | 3.64±0.11 | 4.03 | 4.06 | 6 | 5 |
| B+MP | 2.63±0.11 | 2.96±0.13 | 3.77±0.10 | 3.76±0.12 | 4.02 | 4.06 | ||
| B+DA | 3.95±0.13 | 3.97±0.11 | 3.84±0.12 | 3.85±0.11 | 3.98 | 3.96 | 1 | 1 |
| B+DA+FN | 4.03±0.11 | 3.85 | 1 | 1 | ||||
| B+MP+DA | 3.97±0.14 | 3.96±0.12 | 4.01±0.12 | 3.77 | 1 | 1 | ||
| B+MP+DA+FN | 4.19±0.11 | 4.16±0.13 | 4.17±0.12 | 4.20±0.11 | 3.77 | 3.78 | 1 | 1 |
表3 各模块组合的SMOS、EMOS、MCD、WER评分
Tab. 3 SMOS, EMOS, MCD, WER scores of different module combinations
| 方法 | SMOS | EMOS | MCD | WER/% | ||||
|---|---|---|---|---|---|---|---|---|
| EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | |
| B | 2.64±0.12 | 2.96±0.14 | 3.61±0.10 | 3.64±0.11 | 4.03 | 4.06 | 6 | 5 |
| B+MP | 2.63±0.11 | 2.96±0.13 | 3.77±0.10 | 3.76±0.12 | 4.02 | 4.06 | ||
| B+DA | 3.95±0.13 | 3.97±0.11 | 3.84±0.12 | 3.85±0.11 | 3.98 | 3.96 | 1 | 1 |
| B+DA+FN | 4.03±0.11 | 3.85 | 1 | 1 | ||||
| B+MP+DA | 3.97±0.14 | 3.96±0.12 | 4.01±0.12 | 3.77 | 1 | 1 | ||
| B+MP+DA+FN | 4.19±0.11 | 4.16±0.13 | 4.17±0.12 | 4.20±0.11 | 3.77 | 3.78 | 1 | 1 |
| 方法 | SMOS | EMOS | MCD | WER/% | ||||
|---|---|---|---|---|---|---|---|---|
| EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | |
| CycleGAN-EVC | 2.86±0.13 | 3.58±0.12 | 3.51±0.12 | 3.53±0.14 | 4.56 | 4.51 | 5 | 5 |
| StarGAN-EVC | 2.88±0.11 | 3.59±0.13 | 3.56±0.11 | 3.59±0.13 | 4.39 | 4.36 | 6 | 5 |
| Seq2Seq-EVC | 2.93±0.11 | 3.83±0.13 | 3.85±0.11 | 3.83±0.13 | 3.94 | 3.92 | 4 | 4 |
| Seq2Seq-EVC-WA2 | 3.89±0.14 | 3.96±0.12 | 3.75 | 3.74 | 3 | |||
| SMAL-ET2 | 4.06±0.13 | 4.08±0.12 | 3.80 | 3.81 | 1 | |||
| LSEVC | 4.19±0.11 | 4.16±0.13 | 4.17±0.12 | 4.20±0.11 | 1 | 0 | ||
表4 实验中不同方法性能的对比
Tab. 4 Performance comparison of different methods in experiments
| 方法 | SMOS | EMOS | MCD | WER/% | ||||
|---|---|---|---|---|---|---|---|---|
| EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | |
| CycleGAN-EVC | 2.86±0.13 | 3.58±0.12 | 3.51±0.12 | 3.53±0.14 | 4.56 | 4.51 | 5 | 5 |
| StarGAN-EVC | 2.88±0.11 | 3.59±0.13 | 3.56±0.11 | 3.59±0.13 | 4.39 | 4.36 | 6 | 5 |
| Seq2Seq-EVC | 2.93±0.11 | 3.83±0.13 | 3.85±0.11 | 3.83±0.13 | 3.94 | 3.92 | 4 | 4 |
| Seq2Seq-EVC-WA2 | 3.89±0.14 | 3.96±0.12 | 3.75 | 3.74 | 3 | |||
| SMAL-ET2 | 4.06±0.13 | 4.08±0.12 | 3.80 | 3.81 | 1 | |||
| LSEVC | 4.19±0.11 | 4.16±0.13 | 4.17±0.12 | 4.20±0.11 | 1 | 0 | ||
| 1 | 张小峰,谢钧,罗健欣,等. 深度学习语音合成技术综述[J]. 计算机工程与应用, 2021, 57(9): 50-59. |
| ZHANG X F, XIE J, LUO J X, et al. Overview of deep learning speech synthesis technology [J]. Computer Engineering and Applications, 2021, 57(9): 50-59. | |
| 2 | TAN X, CHEN J, LIU H, et al. NaturalSpeech: end-to-end text to speech synthesis with human-level quality [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(6): 4234-4245. |
| 3 | HUANG R, ZHAO Z, LIU H, et al. ProDiff: progressive fast diffusion model for high-quality text-to-speech [C]// Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 2595-2605. |
| 4 | SHEN J, PANG R, WEISS R J. Natural TTS synthesis by conditioning WaveNet on Mel spectrogram predictions [C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 4779-4783. |
| 5 | REN Y, HU C, TAN X, et al. FastSpeech 2: fast and high-quality end-to-end text to speech [EB/OL]. [2023-02-21]. . |
| 6 | 姚文翰,柯登峰,黄良杰,等. 基于多领域条件生成的语音情感转换[J]. 郑州大学学报(理学版), 2023, 55(5): 67-72. |
| YAO W H, KE D F, HUANG L J, et al. Emotional voice conversion based on multiple domain conditional generation [J]. Journal of Zhengzhou University (Natural Science Edition), 2023, 55(5): 67-72. | |
| 7 | YANG Z, JING X, TRIANTAFYLLOPOULOS A, et al. An overview & analysis of sequence-to-sequence emotional voice conversion [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 4915-4919. |
| 8 | SHAH N, SINGH M, TAKAHASHI N, et al. Nonparallel emotional voice conversion for unseen speaker-emotion pairs using dual domain adversarial network & virtual domain pairing [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| 9 | 陈乐乐,张雄伟,孙蒙,等. 融合梅尔谱增强与特征解耦的噪声鲁棒语音转换[J]. 声学学报, 2023, 48(5): 1070-1080. |
| CHEN L L, ZHANG X W, SUN M, et al. Noise robust voice conversion with the fusion of Mel-spectrum enhancement and feature disentanglement [J]. Acta Acustica, 2023, 48(5):1070-1080. | |
| 10 | 王翠英. 基于深度学习的合成语音转换问题研究[J]. 自动化与仪器仪表, 2023(7): 196-200. |
| WANG C J. Research on synthetic speech conversion based on deep learning [J]. Automation and Instrumentation, 2023(7):196-200. | |
| 11 | WALCZYNA T, PIOTROWSKI Z. Overview of voice conversion methods based on deep learning [J]. Applied Sciences, 2023, 13(5): No.3100. |
| 12 | ZHU X, LEI Y, SONG K, et al. Multi-speaker expressive speech synthesis via multiple factors decoupling [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| 13 | 李晨光,张波,赵骞,等. 基于迁移学习的文本共情预测[J]. 计算机应用, 2022, 42(11):3603-3609. |
| LI C G, ZHANG B, ZHAO Q, et al. Empathy prediction from texts based on transfer learning [J]. Journal of Computer Applications, 2022, 42(11): 3603-3609. | |
| 14 | LEI Y, YANG S, WANG X, et al. MsEmoTTS: multi-scale emotion transfer, prediction, and control for emotional speech synthesis [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 853-864. |
| 15 | ZHOU K, SISMAN B, LI H. Limited data emotional voice conversion leveraging text-to-speech: two-stage sequence-to-sequence training [C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 811-815. |
| 16 | ZHOU K, SISMAN B, LIU R, et al. Seen and unseen emotional style transfer for voice conversion with a new emotional speech dataset [C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 920-924. |
| 17 | DU Z, QIAN Y, LIU X, et al. GLM: general language model pretraining with autoregressive blank infilling [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 320-335. |
| 18 | STYLIANOU Y, CAPPÉ O, MOULINES É. Continuous probabilistic transform for voice conversion [J]. IEEE Transactions on Speech and Audio Processing, 1998, 6(2): 131-142. |
| 19 | YE H, YOUNG S. Voice conversion for unknown speakers[C]// Proceedings of the INTERSPEECH 2004. [S.l.]: International Speech Communication Association, 2004:1161-1164. |
| 20 | ZHOU K, SISMAN B, LI H. Transforming spectrum and prosody for emotional voice conversion with non-parallel training data [C]// Proceedings of the 2020 Speaker and Language Recognition Workshop. [S.l.]: International Speech Communication Association, 2020: 230-237. |
| 21 | KIM T H, CHO S, CHOI S, et al. Emotional voice conversion using multitask learning with Text-To-Speech [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 7774-7778. |
| 22 | ZHAO Z, LIANG J, ZHENG Z, et al. Improving model stability and training efficiency in fast, high quality expressive voice conversion system [C]// Companion Publication of the 2021 International Conference on Multimodal Interaction. New York: ACM, 2021: 75-79. |
| 23 | ABBAS A, ABDELSAMEA M M, GABER M M. 4S-DT: self-supervised super sample decomposition for transfer learning with application to COVID-19 detection [J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(7): 2798-2808. |
| 24 | PAN J, LIN Z, ZHU X, et al. St-Adapter: parameter-efficient image-to-video transfer learning [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 26462-26477. |
| 25 | QASIM R, BANGYAL W H, ALQARNI M A, et al. A fine-tuned BERT-based transfer learning approach for text classification [J]. Journal of Healthcare Engineering, 2022, 2022: No.3498123. |
| 26 | LIU Y, SUN H, CHEN G, et al. Multi-level knowledge distillation for speech emotion recognition in noisy conditions [C]// Proceedings of the INTERSPEECH 2023. [S.l.]: International Speech Communication Association, 2023: 1893-1897. |
| 27 | SUN H, ZHAO S, WANG X, et al. Fine-grained disentangled representation learning for multimodal emotion recognition [C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 11051-11055. |
| 28 | LI Y A, HAN C, MESGARANI N. StyleTTS-VC: one-shot voice conversion by knowledge transfer from style-based tts models [C]// Proceedings of the 2022 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2023: 920-927. |
| 29 | HUANG W C, HAYASHI T, WU Y C, et al. Pretraining techniques for sequence-to-sequence voice conversion [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 745-755. |
| 30 | DU Z, SISMAN B, ZHOU K, et al. Disentanglement of emotional style and speaker identity for expressive voice conversion [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 2603-2607. |
| 31 | WANG D, DENG L, YEUNG Y T, et al. VQMIVC: vector quantization and mutual information-based unsupervised speech representation disentanglement for one-shot voice conversion [C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 1344-1348. |
| 32 | KLAPSAS K, ELLINAS N, SUNG J S, et al. Word-level style control for expressive, non-attentive speech synthesis [C]// Proceedings of the 2021 International Conference on Speech and Computer, LNCS 12997. Cham: Springer, 2021: 336-347. |
| 33 | LUO Z, CHEN J, TAKIGUCHI T, et al. Emotional voice conversion using dual supervised adversarial networks with continuous wavelet transform F0 features [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(10): 1535-1548. |
| 34 | XUE L, SOONG F K, ZHANG S, et al. ParaTTS: learning linguistic and prosodic cross-sentence information in paragraph-based TTS [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 2854-2864. |
| 35 | WU N Q, LIU Z C, LING Z H, et al. Discourse-level prosody modeling with a variational autoencoder for non-autoregressive expressive speech synthesis [C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7592-7596. |
| 36 | SUN G, ZHANG Y, WEISS R J, et al. Generating diverse and natural Text-To-Speech samples using a quantized fine-grained VAE and autoregressive prosody prior [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 6699-6703. |
| 37 | CHIEN C M, LEE H Y. Hierarchical prosody modeling for non-autoregressive speech synthesis [C]// Proceedings of the 2021 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2021: 446-453. |
| 38 | CHAN W, JAITLY N, LE Q, et al. Listen, attend and spell: a neural network for large vocabulary conversational speech recognition [C]// Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2016: 4960-4964. |
| 39 | SHI Y, BU H, XU X, et al. AISHELL-3: a multi-speaker mandarin TTS corpus[C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 2756-2760. |
| 40 | ZEN H, DANG V, CLARK R, et al. LibriTTS: a corpus derived from LibriSpeech for Text-To-Speech [C]// Proceedings of the INTERSPEECH 2019. [S.l.]: International Speech Communication Association, 2019: 1526-1530. |
| 41 | ZHOU K, SISMAN B, LIU R, et al. Emotional voice conversion: theory, databases and ESD [J]. Speech Communication, 2022, 137: 1-18. |
| 42 | VAN DER MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2605. |
| 43 | ZHANG J X, LING Z H, DAI L R. Non-parallel sequence-to-sequence voice conversion with disentangled linguistic and speaker representations [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 540-552. |
| 44 | ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2242-2251. |
| 45 | MORISE M, YOKOMORI F, OZAWA K. WORLD: a vocoder-based high-quality speech synthesis system for real-time applications [J]. IEICE Transactions on Information and Systems, 2016, E99-D(7): 1877-1884. |
| 46 | MORITANI A, SAKAMOTO S, OZAKI R, et al. StarGAN-based emotional voice conversion for Japanese phrases [C]// Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway: IEEE, 2021: 836-840. |
| 47 | CHOI Y, CHOI M, KIM M, et al. StarGAN: unified generative adversarial networks for multi-domain image-to-image translation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8789-8797. |
| 48 | ZHANG J, WUSHOUER M, TUERHONG G, et al. Semi-supervised learning for robust emotional speech synthesis with limited data [J]. Applied Sciences, 2023, 13(9): No.5724. |
| 49 | KONG J, KIM J, BAE J. Hifi-GAN: generative adversarial networks for efficient and high fidelity speech synthesis [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 17022-17033. |
| [1] | 曹鹏, 温广琪, 杨金柱, 陈刚, 刘歆一, 季学纯. 面向测试用例生成的大模型高效微调方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 725-731. |
| [2] | 孙晨伟, 侯俊利, 刘祥根, 吕建成. 面向工程图纸理解的大语言模型提示生成方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 801-807. |
| [3] | 董艳民, 林佳佳, 张征, 程程, 吴金泽, 王士进, 黄振亚, 刘淇, 陈恩红. 个性化学情感知的智慧助教算法设计与实践[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 765-772. |
| [4] | 盛坤, 王中卿. 基于大语言模型和数据增强的通感隐喻分析[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 794-800. |
| [5] | 秦小林, 古徐, 李弟诚, 徐海文. 大语言模型综述与展望[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 685-696. |
| [6] | 袁成哲, 陈国华, 李丁丁, 朱源, 林荣华, 钟昊, 汤庸. ScholatGPT:面向学术社交网络的大语言模型及智能应用[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 755-764. |
| [7] | 张学飞, 张丽萍, 闫盛, 侯敏, 赵宇博. 知识图谱与大语言模型协同的个性化学习推荐[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 773-784. |
| [8] | 徐月梅, 叶宇齐, 何雪怡. 大语言模型的偏见挑战:识别、评估与去除[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 697-708. |
| [9] | 杨燕, 叶枫, 许栋, 张雪洁, 徐津. 融合大语言模型和提示学习的数字孪生水利知识图谱构建[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 785-793. |
| [10] | 曾辉, 熊诗雨, 狄永正, 史红周. 基于剪枝的大模型联邦参数高效微调技术[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 715-724. |
| [11] | 何静, 沈阳, 谢润锋. 大语言模型幻觉现象的识别与优化[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 709-714. |
| [12] | 刘弘业, 陈锡爱, 曾涛. 基于选择状态空间的三模态适配器[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 411-420. |
| [13] | 孙焕良, 王思懿, 刘俊岭, 许景科. 社交媒体数据中水灾事件求助信息提取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2437-2445. |
| [14] | 徐月梅, 胡玲, 赵佳艺, 杜宛泽, 王文清. 大语言模型的技术应用前景与风险挑战[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1655-1662. |
| [15] | 李雪, 姚光乐, 王洪辉, 李军, 周皓然, 叶绍泽. 基于样本增量学习的遥感影像分类[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 732-736. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||