


Journal of Computer Applications ›› 2022, Vol. 42 ›› Issue (8): 2361-2368.DOI: 10.11772/j.issn.1001-9081.2021061012
Special Issue: 人工智能
• Artificial intelligence • Previous Articles Next Articles
Received:2021-06-10
Revised:2021-10-13
Accepted:2021-10-29
Online:2022-01-25
Published:2022-08-10
Contact:
Fei LUO
About author:LUO Fei, born in 1978, Ph. D., associate professor. His research interests include cognitive computing, reinforcement learning.Supported by:
罗飞( ), 白梦伟
), 白梦伟
通讯作者:
罗飞
作者简介:罗飞(1978—),男,湖北武汉人,副教授,博士,CCF会员,主要研究方向:认知计算、强化学习;基金资助:CLC Number:
Fei LUO, Mengwei BAI. Decision optimization of traffic scenario problem based on reinforcement learning[J]. Journal of Computer Applications, 2022, 42(8): 2361-2368.
罗飞, 白梦伟. 基于强化学习的交通情景问题决策优化[J]. 《计算机应用》唯一官方网站, 2022, 42(8): 2361-2368.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2021061012

Fig. 1 Schematic diagram of interaction between agent and environment

Fig. 2 Structure of GSQL-DSEP algorithm

Fig. 3 Performance of GSQL-DSEP algorithm under different sampling numbers

Fig. 4 Performance of GSQL-DSEP algorithm under different experience pool sizes
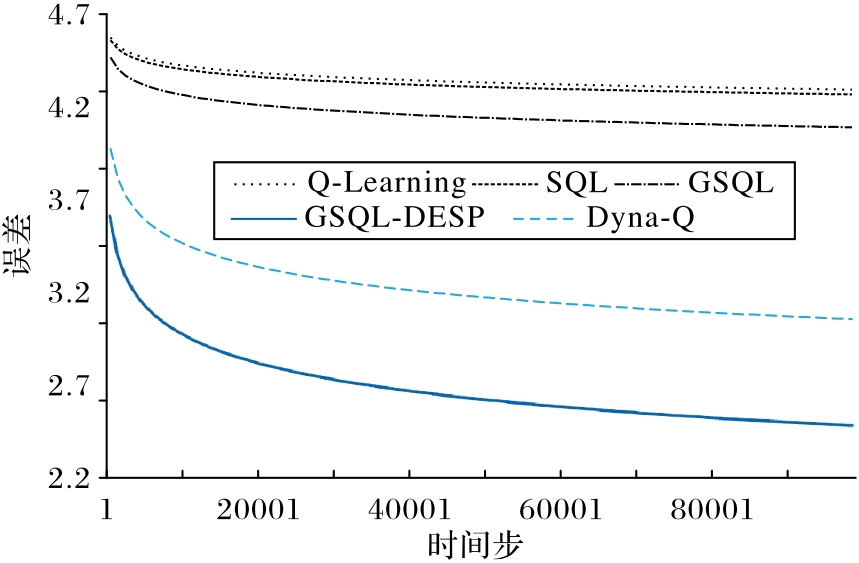
Fig. 5 Mean square error comparison of different reinforcement learning algorithms

Fig. 6 Driving environment for taxi drivers
| 动作值 | 含义 |
|---|---|
| 0 | 出租车向北行驶 |
| 1 | 出租车向南行驶 |
| 2 | 出租车向东行驶 |
| 3 | 出租车向西行驶 |
| 4 | 出租车载客操作 |
| 5 | 出租车卸客操作 |
Tab. 1 Definition of taxi action space
| 动作值 | 含义 |
|---|---|
| 0 | 出租车向北行驶 |
| 1 | 出租车向南行驶 |
| 2 | 出租车向东行驶 |
| 3 | 出租车向西行驶 |
| 4 | 出租车载客操作 |
| 5 | 出租车卸客操作 |
| 奖励项 | 奖励值 |
|---|---|
| 每个时间步 | -1 |
| 完成任务 | 20 |
| 错误载客 | -10 |
| 错误卸客 | -10 |
Tab. 2 Definition of taxi reward function
| 奖励项 | 奖励值 |
|---|---|
| 每个时间步 | -1 |
| 完成任务 | 20 |
| 错误载客 | -10 |
| 错误卸客 | -10 |
| 参数 | 值 |
|---|---|
| 学习率 | 0.6 |
| 衰减因子 | 0.9 |
| 迭代回合 | 600 |
Tab. 3 Hyperparameter setting for taxis
| 参数 | 值 |
|---|---|
| 学习率 | 0.6 |
| 衰减因子 | 0.9 |
| 迭代回合 | 600 |

Fig. 7 Influence of experience pool sizes on decision path length

Fig. 8 Influence of sampling numbers on decision path length

Fig. 9 Comparison of cumulative reward among different algorithms in taxi path planning

Fig. 10 Comparison of decision path length amongdifferent algorithms

Fig. 11 Traffic light control environment
| 参数 | 值 |
|---|---|
| 每条公路长度 | 300 m |
| 车辆起始停放长度 | 10 m |
| 仿真时间 | 600 s |
| 每分钟东西方向车辆数 | 40 |
| 每分钟南北方向车辆数 | 4 |
| 车辆长度 | 5 m |
| 车辆最小间距 | 2 m |
| 最大车速 | 16.67 m/s |
Tab. 4 Traffic environmental parameters
| 参数 | 值 |
|---|---|
| 每条公路长度 | 300 m |
| 车辆起始停放长度 | 10 m |
| 仿真时间 | 600 s |
| 每分钟东西方向车辆数 | 40 |
| 每分钟南北方向车辆数 | 4 |
| 车辆长度 | 5 m |
| 车辆最小间距 | 2 m |
| 最大车速 | 16.67 m/s |
| 动作值 | 对应动作内容 |
|---|---|
| 0 | GGGGRRGRRGRR |
| 1 | GGRGRGGRRGRR |
| 2 | GGRGRRGGRGRR |
| 3 | GRGGRRGRGGRR |
| 4 | GRGGRRGRRGGR |
| 5 | GRRGGGGRRGRR |
| 6 | GRRGGRGRGGRR |
| 7 | GRRGGRGRRGGR |
| 8 | GRRGRGGRRGRG |
| 9 | GRRGRRGGGGRR |
| 10 | GRRGRRGGRGRG |
| 11 | GRRGRRGRRGGG |
Tab. 5 Definition of traffic signal action space
| 动作值 | 对应动作内容 |
|---|---|
| 0 | GGGGRRGRRGRR |
| 1 | GGRGRGGRRGRR |
| 2 | GGRGRRGGRGRR |
| 3 | GRGGRRGRGGRR |
| 4 | GRGGRRGRRGGR |
| 5 | GRRGGGGRRGRR |
| 6 | GRRGGRGRGGRR |
| 7 | GRRGGRGRRGGR |
| 8 | GRRGRGGRRGRG |
| 9 | GRRGRRGGGGRR |
| 10 | GRRGRRGGRGRG |
| 11 | GRRGRRGRRGGG |
| 奖励项 | 奖励值 |
|---|---|
| 当前车道上车辆平均等待时间 | - |
| 当前发生碰撞情况的车辆个数 | - |
| 每个时间步 | -0.1 |
| 当前发生到达终点的车辆数 | 0.1 |
| 信号灯发生改变 | -0.1 |
Tab. 6 Definition of reward function for traffic signal control
| 奖励项 | 奖励值 |
|---|---|
| 当前车道上车辆平均等待时间 | - |
| 当前发生碰撞情况的车辆个数 | - |
| 每个时间步 | -0.1 |
| 当前发生到达终点的车辆数 | 0.1 |
| 信号灯发生改变 | -0.1 |
| 强化学习算法 | 得到的累积奖励 |
|---|---|
| Q-Learning | -95.248 |
| SQL | -95.248 |
| GSQL | -27.592 |
| Dyna-Q | -32.144 |
| GSQL-DSEP | -27.392 |
Tab. 7 Final cumulative rewards of traffic signal control obtained by different algorithms
| 强化学习算法 | 得到的累积奖励 |
|---|---|
| Q-Learning | -95.248 |
| SQL | -95.248 |
| GSQL | -27.592 |
| Dyna-Q | -32.144 |
| GSQL-DSEP | -27.392 |
| 强化学习算法 | 车辆总等待时间 |
|---|---|
| Q-Learning | 2 769 |
| SQL | 2 769 |
| GSQL | 1 344 |
| Dyna-Q | 1 392 |
| GSQL-DSEP | 1 344 |
Tab. 8 Total waiting time of vehicles obtained by different algorithms
| 强化学习算法 | 车辆总等待时间 |
|---|---|
| Q-Learning | 2 769 |
| SQL | 2 769 |
| GSQL | 1 344 |
| Dyna-Q | 1 392 |
| GSQL-DSEP | 1 344 |
| 1 | RINGHAND M, MARK V. Effect of complex traffic situations on route choice behaviour and driver stress in residential areas[J]. Transportation Research Part F: Traffic Psychology and Behaviour, 2019, 60: 274-287. 10.1016/j.trf.2018.10.023 |
| 2 | LI Y, ZHANG H Y, ZHU H Z, et al. IBAS: index based A-star[J]. IEEE Access, 2018, 6: 11707-11715. 10.1109/access.2018.2808407 |
| 3 | ZHANG Y, TANG J F, LV S M, et al. Floyd-A∗ algorithm solving the least-time itinerary planning problem in urban scheduled public transport network[J]. Mathematical Problems in Engineering, 2014, 2014: No.185383. 10.1155/2014/185383 |
| 4 | YU Z Q, YU X H, KOUDAS N, et al. Distributed processing of k shortest path queries over dynamic road networks [C]// Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2020: 665-679. 10.1145/3318464.3389735 |
| 5 | HART P E, NILSSON N J, RAPHAEL B. A formal basis for the heuristic determination of minimum cost paths[J]. IEEE Transactions on Systems Science and Cybernetics, 1968, 4(2): 100-107. 10.1109/tssc.1968.300136 |
| 6 | FLOYD R W. Algorithm 97: shortest path[J]. Communications of the ACM, 1962, 5(6): 345-345. 10.1145/367766.368168 |
| 7 | HOFFMAN W, PAVLEY R. A method for the solution of the nth best path problem[J]. Journal of the ACM, 1959, 6(4): 506-514. 10.1145/320998.321004 |
| 8 | 刘思嘉,童向荣.基于强化学习的城市交通路径规划[J].计算机应用, 2021, 41(1): 185-190. 10.11772/j.issn.1001-9081.2020060949 |
| LIU S J, TONG X R. Urban transportation path planning based on reinforcement learning[J]. Journal of Computer Applications, 2021, 41(1): 185-190. 10.11772/j.issn.1001-9081.2020060949 | |
| 9 | COOLS S B, GERSHENSON C, D’HOOGHE B. Self-organizing traffic lights: a realistic simulation[M]// PROKOPENKO M. Advances in Applied Self-Organizing Systems. London: Springer, 2013: 45-55. 10.1007/978-1-4471-5113-5_3 |
| 10 | VARAIYA P. The max-pressure controller for arbitrary networks of signalized intersections[M]// UKKUSURI S V, OZBAY K. Advances in Dynamic Network Modeling in Complex Transportation Systems. New York: Springer, 2013: 27-66. 10.1007/978-1-4614-6243-9_2 |
| 11 | MAITI N, CHILUKURI B R. Traffic signal control for an isolated intersection using reinforcement learning [C]// Proceedings of the 2021 International Conference on Communication Systems and Networks. Piscataway: IEEE, 2021: 629-633. 10.1109/comsnets51098.2021.9352834 |
| 12 | SUTTON R S. Dyna, an integrated architecture for learning, planning, and reacting[J]. ACM SIGART Bulletin, 1991, 2(4): 160-163. 10.1145/122344.122377 |
| 13 | 封硕,舒红,谢步庆.基于改进深度强化学习的三维环境路径规划[J].计算机应用与软件, 2021, 38(1): 250-255. 10.3969/j.issn.1000-386x.2021.01.042 |
| FENG S, SHU H, XIE B Q. 3D environment path planning based on improved deep reinforcement learning[J]. Computer Applications and Software, 2021, 38(1): 250-255. 10.3969/j.issn.1000-386x.2021.01.042 | |
| 14 | EL-TANTAWY S, ABDULHAI B, ABDELGAWAD H. MultiAgent Reinforcement Learning for Integrated Network of Adaptive Traffic Signal Controllers (MARLIN-ATSC): methodology and large-scale application on downtown Toronto[J]. IEEE Transactions on Intelligent Transportation Systems, 2013, 14(3): 1140-1150. 10.1109/tits.2013.2255286 |
| 15 | CHEN C C, WEI H, XU N, et al. Toward a thousand lights: decentralized deep reinforcement learning for large-scale traffic signal control [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 3414-3421. 10.1609/aaai.v34i04.5744 |
| 16 | SUTTON R S, BARTO A G. Reinforcement Learning: an Introduction[M]. 2nd ed. Cambridge: MIT Press, 2018: 23-194. |
| 17 | AZAR M G, MUNOS R, GHAVAMZADEH M, et al. Speedy Q-learning [C]// Proceedings of the 24th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2011: 2411-2419. |
| 18 | KAMANCHI C, DIDDIGI R B, BHATNAGAR S. Successive over-relaxation Q-learning[J]. IEEE Control Systems Letters, 2020, 4(1): 55-60. 10.1109/lcsys.2019.2921158 |
| 19 | JOHN I, KAMANCHI C, BHATNAGAR S. Generalized speedy Q-learning[J]. IEEE Control Systems Letters, 2020, 4(3): 524-529. 10.1109/lcsys.2020.2970555 |
| 20 | DIETTERICH T G. The MAXQ method for hierarchical reinforcement learning [C]// Proceedings of the 15th International Conference on Machine Learning, San Francisco: Morgan Kaufmann Publishers Inc., 1998: 118-126. 10.1613/jair.639 |
| [1] | Hailin XIAO, Tianyi HUANG, Qiuxiang DAI, Yuejun ZHANG, Zhongshan ZHANG. Safe reinforcement learning method for decision making of autonomous lane changing based on trajectory prediction [J]. Journal of Computer Applications, 2024, 44(9): 2958-2963. |
| [2] | Haodong HE, Hao FU, Qiang WANG, Shuai ZHOU, Wei LIU. Multi-robot path following and formation based on deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(8): 2626-2633. |
| [3] | Yi ZHOU, Hua GAO, Yongshen TIAN. Proximal policy optimization algorithm based on clipping optimization and policy guidance [J]. Journal of Computer Applications, 2024, 44(8): 2334-2341. |
| [4] | Tian MA, Runtao XI, Jiahao LYU, Yijie ZENG, Jiayi YANG, Jiehui ZHANG. Mobile robot 3D space path planning method based on deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(7): 2055-2064. |
| [5] | Xiaoyan ZHAO, Wei HAN, Junna ZHANG, Peiyan YUAN. Collaborative offloading strategy in internet of vehicles based on asynchronous deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(5): 1501-1510. |
| [6] | Rui TANG, Chuanlin PANG, Ruizhi ZHANG, Chuan LIU, Shibo YUE. DDPG-based resource allocation in D2D communication-empowered cellular network [J]. Journal of Computer Applications, 2024, 44(5): 1562-1569. |
| [7] | Fatang CHEN, Miao HUANG, Yufeng JIN. Resource allocation algorithm for low earth orbit satellites oriented to user demand [J]. Journal of Computer Applications, 2024, 44(4): 1242-1247. |
| [8] | Xintong QIN, Zhengyu SONG, Tianwei HOU, Feiyue WANG, Xin SUN, Wei LI. Channel access and resource allocation algorithm for adaptive p-persistent mobile ad hoc network [J]. Journal of Computer Applications, 2024, 44(3): 863-868. |
| [9] | Ziyang SONG, Junhuai LI, Huaijun WANG, Xin SU, Lei YU. Path planning algorithm of manipulator based on path imitation and SAC reinforcement learning [J]. Journal of Computer Applications, 2024, 44(2): 439-444. |
| [10] | Yuanchao LI, Chongben TAO, Chen WANG. Gait control method based on maximum entropy deep reinforcement learning for biped robot [J]. Journal of Computer Applications, 2024, 44(2): 445-451. |
| [11] | Fuqin DENG, Huifeng GUAN, Chaoen TAN, Lanhui FU, Hongmin WANG, Tinlun LAM, Jianmin ZHANG. Multi-robot reinforcement learning path planning method based on request-response communication mechanism and local attention mechanism [J]. Journal of Computer Applications, 2024, 44(2): 432-438. |
| [12] | Jiachen YU, Ye YANG. Irregular object grasping by soft robotic arm based on clipped proximal policy optimization algorithm [J]. Journal of Computer Applications, 2024, 44(11): 3629-3638. |
| [13] | Yu WANG, Zhihui GUAN, Yuanpeng LI. Distributed UAV cluster pursuit decision-making based on trajectory prediction and MADDPG [J]. Journal of Computer Applications, 2024, 44(11): 3623-3628. |
| [14] | Jie LONG, Liang XIE, Haijiao XU. Integrated deep reinforcement learning portfolio model [J]. Journal of Computer Applications, 2024, 44(1): 300-310. |
| [15] | Yu WANG, Tianjun REN, Zilin FAN. Air combat maneuver decision-making of unmanned aerial vehicle based on guided Minimax-DDQN [J]. Journal of Computer Applications, 2023, 43(8): 2636-2643. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||