


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (8): 2572-2581.DOI: 10.11772/j.issn.1001-9081.2024071063
• 数据科学与技术 • 上一篇
吴军( ), 欧阳艾嘉, 王亚
), 欧阳艾嘉, 王亚
收稿日期:2024-07-30
修回日期:2024-10-14
接受日期:2024-10-15
发布日期:2024-11-19
出版日期:2025-08-10
通讯作者:
吴军
作者简介:欧阳艾嘉(1975—),男,湖南娄底人,教授,博士,主要研究方向:智能计算、并行计算基金资助:
Jun WU(), Aijia OUYANG, Ya WANG
Received:2024-07-30
Revised:2024-10-14
Accepted:2024-10-15
Online:2024-11-19
Published:2025-08-10
Contact:
Jun WU
About author:OUYANG Aijia, born in 1975, Ph. D., professor. His research interests include intelligent computing, parallel computing.Supported by:摘要:
针对高效用模式挖掘任务中假阳性模式和冗余模式的判别问题,提出一种基于无限制检验和独立成长率的判别高效用模式挖掘算法UTDHU(Unlimited Testing for Discriminative High Utility pattern mining)。首先,找到目标事务集合中满足效用阈值和差异阈值的判别高效用模式;其次,建立前缀项共享树以快速计算每个模式的独立成长率,并基于独立成长率筛除未超过独立阈值的冗余判别高效用模式;最后,使用无限制检验计算余下每个模式的统计显著性度量p值,并根据错误率判断族过滤整体结果中的假阳性判别高效用模式。在4个基准事务集合和2个仿真事务集合上的实验结果表明,相较于Hamm和YBHU (Yekutieli-Benjamini resampling for High Utility pattern mining)等算法,所提算法在模式数量方面输出最少,过滤了至少97.8%的被检验模式;在模式质量方面,所提算法的假阳性判别高效用模式占比低于5.2%,且构造特征的分类准确率高于对比算法至少1.5个百分点;虽然所提算法在运行时间方面慢于Hamm算法,但快于其余3个基于统计显著性检验的算法。可见,所提算法能够有效剔除一定数量的假阳性和冗余判别高效用模式,在挖掘性能上更优,且运行效率更高。
中图分类号:
吴军, 欧阳艾嘉, 王亚. 非冗余统计显著判别高效用模式挖掘算法[J]. 计算机应用, 2025, 45(8): 2572-2581.
Jun WU, Aijia OUYANG, Ya WANG. Non-redundant and statistically significant discriminative high utility pattern mining algorithm[J]. Journal of Computer Applications, 2025, 45(8): 2572-2581.
| 编号 | 事务 | 标签 | u(Tj,D) |
|---|---|---|---|
| T1 | (i1,2), (i3,4), (i5,1) | a1 | 17 |
| T2 | (i1,1), (i2,3), (i3,2), (i5,5) | a1 | 16 |
| T3 | (i1,4), (i5,3) | a1 | 11 |
| T4 | (i2,2), (i3 2), (i4,1), (i5,1) | a2 | 14 |
| T5 | (i2,2), (i3,3), (i4,4) | a2 | 31 |
| T6 | (i1,1), (i2,3), (i3,1), (i4,2), (i5,4) | a2 | 22 |
表1 事务集合D样例
Tab. 1 Example of transaction set D
| 编号 | 事务 | 标签 | u(Tj,D) |
|---|---|---|---|
| T1 | (i1,2), (i3,4), (i5,1) | a1 | 17 |
| T2 | (i1,1), (i2,3), (i3,2), (i5,5) | a1 | 16 |
| T3 | (i1,4), (i5,3) | a1 | 11 |
| T4 | (i2,2), (i3 2), (i4,1), (i5,1) | a2 | 14 |
| T5 | (i2,2), (i3,3), (i4,4) | a2 | 31 |
| T6 | (i1,1), (i2,3), (i3,1), (i4,2), (i5,4) | a2 | 22 |
| 度量 | 外部效用 | 度量 | 外部效用 |
|---|---|---|---|
| i1 | 2 | i4 | 5 |
| i2 | 1 | i5 | 1 |
| i3 | 3 |
表2 D中每个项的外部效用
Tab. 2 External utility of each item in D
| 度量 | 外部效用 | 度量 | 外部效用 |
|---|---|---|---|
| i1 | 2 | i4 | 5 |
| i2 | 1 | i5 | 1 |
| i3 | 3 |
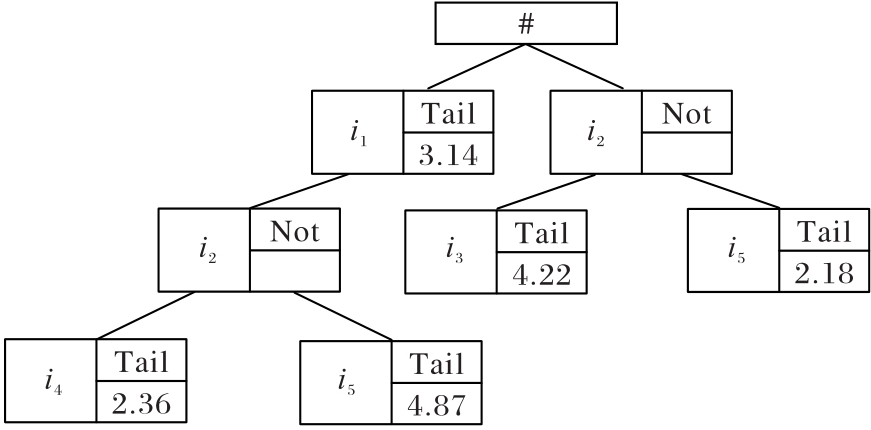
图1 前缀项共享树样例
Fig. 1 Example of shared tree of prefix-items
| 集合 | 事务数 | ||
|---|---|---|---|
| 事务数包含X | 不包含X | 合计 | |
| D1 | sup(X,D1) | ||
| D2 | sup(X,D2) | ||
表3 X在D1和D2中的分布列表
Tab. 3 The distribution of X in D1 and D2
| 集合 | 事务数 | ||
|---|---|---|---|
| 事务数包含X | 不包含X | 合计 | |
| D1 | sup(X,D1) | ||
| D2 | sup(X,D2) | ||
| 名称 | |I| | |D| | 平均长度 | |A| |
|---|---|---|---|---|
| Connect | 129 | 67 557 | 42.0 | 2 |
| Covtype | 54 | 581 012 | 11.9 | 2 |
| Phishing | 68 | 11 055 | 31.0 | 2 |
| Phospep | 310 | 13 278 | 19.6 | 2 |
| Synden | 60 | 20 000 | 20.0 | 2 |
| Synspa | 600 | 20 000 | 20.0 | 2 |
表4 实验事务集合信息
Tab. 4 Details of experimental transaction sets
| 名称 | |I| | |D| | 平均长度 | |A| |
|---|---|---|---|---|
| Connect | 129 | 67 557 | 42.0 | 2 |
| Covtype | 54 | 581 012 | 11.9 | 2 |
| Phishing | 68 | 11 055 | 31.0 | 2 |
| Phospep | 310 | 13 278 | 19.6 | 2 |
| Synden | 60 | 20 000 | 20.0 | 2 |
| Synspa | 600 | 20 000 | 20.0 | 2 |
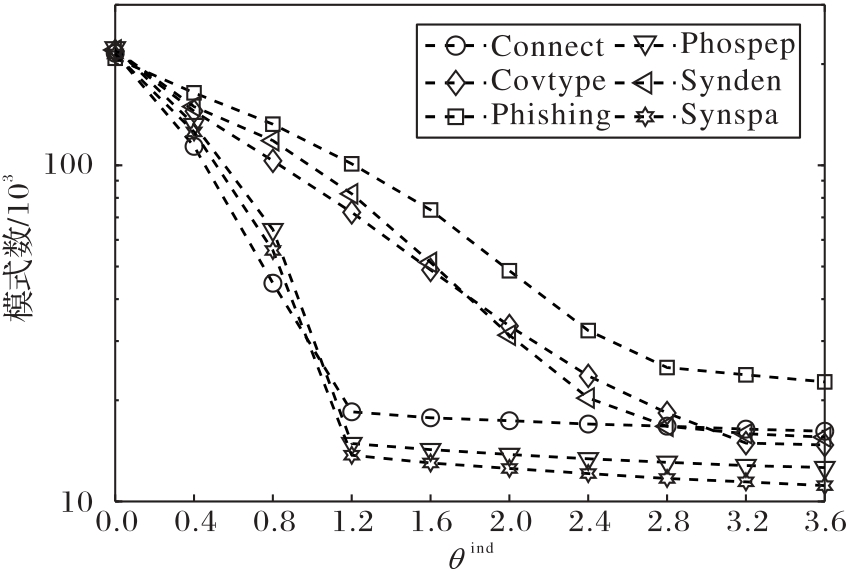
图2 UTDHU_r算法在每个事务集合上输出的非冗余模式数
Fig. 2 Number of non-redundant patterns outputted by UTDHU_r algorithm on each transaction set
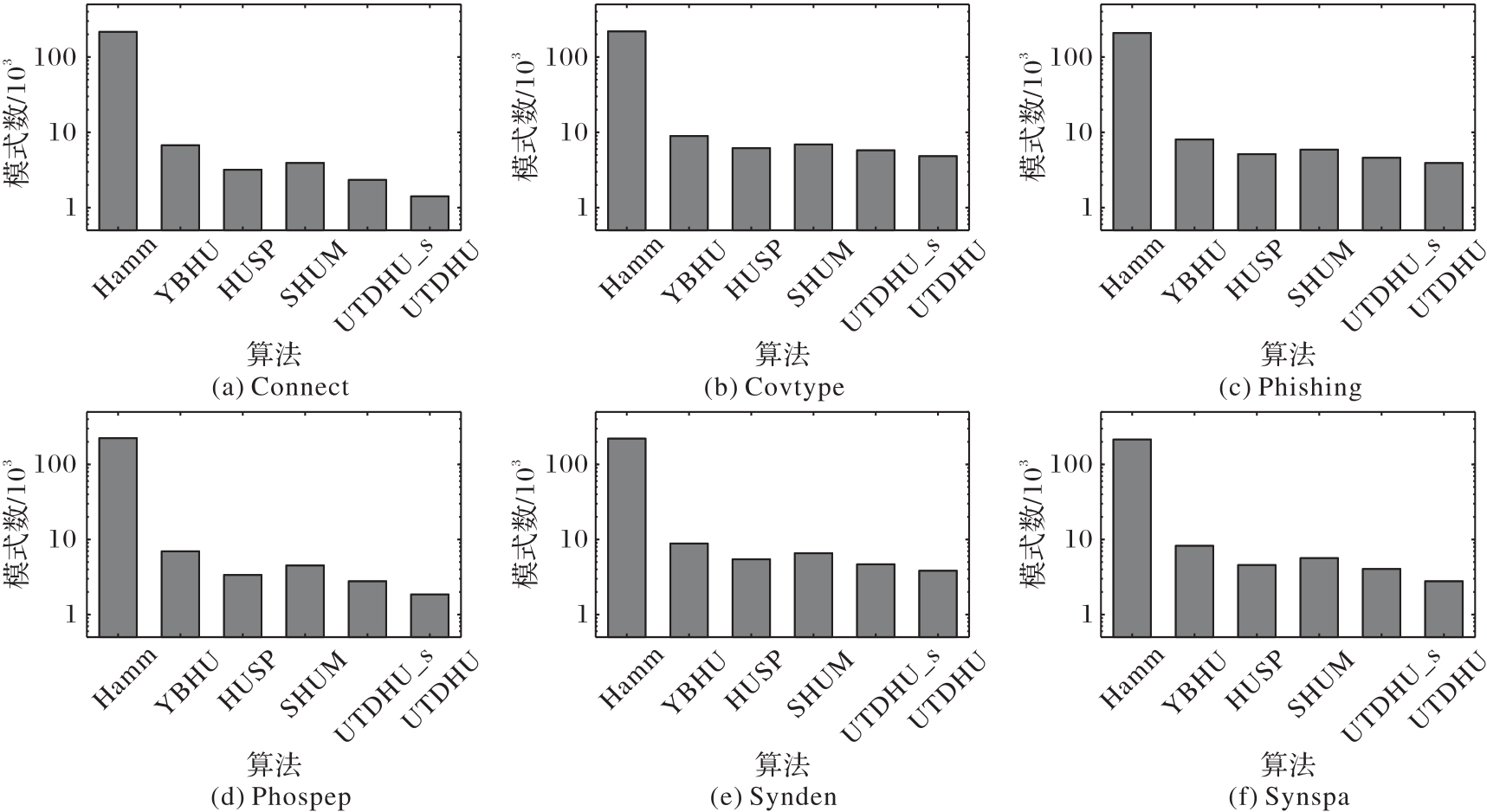
图3 各个算法在每个事务集合上输出的判别高效用模式数
Fig. 3 Number of patterns outputted by each algorithm on each transaction set
| 集合 | 算法 | |R| | |Rfap| | |Rfap|/% | |Rsig| | |Rsig|/% |
|---|---|---|---|---|---|---|
| Synden | Hamm[ | 22 016 | 13 243 | 60.2 | 8 773 | 39.8 |
| YBHU[ | 891 | 65 | 7.3 | 826 | 92.7 | |
| HUSP[ | 544 | 36 | 6.6 | 508 | 93.4 | |
| SHUM[ | 656 | 47 | 7.2 | 609 | 92.8 | |
| UTDHU_s | 466 | 24 | 5.1 | 442 | 94.9 | |
| UTDHU | 382 | 20 | 5.2 | 362 | 94.8 | |
| Synspa | Hamm[ | 21 421 | 11 045 | 51.6 | 10 376 | 48.4 |
| YBHU[ | 821 | 56 | 6.8 | 765 | 93.2 | |
| HUSP[ | 456 | 27 | 5.9 | 429 | 94.1 | |
| SHUM[ | 563 | 38 | 6.7 | 525 | 93.3 | |
| UTDHU_s | 404 | 14 | 3.5 | 390 | 96.5 | |
| UTDHU | 277 | 11 | 4.0 | 266 | 96.0 |
表5 仿真事务集合上各个算法输出的判别高效用模式信息
Tab. 5 Details of discriminative high utility patterns outputted by each algorithm on synthetic transaction sets
| 集合 | 算法 | |R| | |Rfap| | |Rfap|/% | |Rsig| | |Rsig|/% |
|---|---|---|---|---|---|---|
| Synden | Hamm[ | 22 016 | 13 243 | 60.2 | 8 773 | 39.8 |
| YBHU[ | 891 | 65 | 7.3 | 826 | 92.7 | |
| HUSP[ | 544 | 36 | 6.6 | 508 | 93.4 | |
| SHUM[ | 656 | 47 | 7.2 | 609 | 92.8 | |
| UTDHU_s | 466 | 24 | 5.1 | 442 | 94.9 | |
| UTDHU | 382 | 20 | 5.2 | 362 | 94.8 | |
| Synspa | Hamm[ | 21 421 | 11 045 | 51.6 | 10 376 | 48.4 |
| YBHU[ | 821 | 56 | 6.8 | 765 | 93.2 | |
| HUSP[ | 456 | 27 | 5.9 | 429 | 94.1 | |
| SHUM[ | 563 | 38 | 6.7 | 525 | 93.3 | |
| UTDHU_s | 404 | 14 | 3.5 | 390 | 96.5 | |
| UTDHU | 277 | 11 | 4.0 | 266 | 96.0 |
| 模型 | 算法 | Connect | Covtype | Phishing | Phospep |
|---|---|---|---|---|---|
支持 向量机 | Hamm[ | 0.746 | 0.763 | 0.803 | 0.756 |
| YBHU[ | 0.845 | 0.933 | 0.907 | 0.824 | |
| HUSP[ | 0.824 | 0.925 | 0.892 | 0.818 | |
| SHUM[ | 0.816 | 0.919 | 0.883 | 0.811 | |
| UTDHU_s | 0.853 | 0.940 | 0.914 | 0.836 | |
| UTDHU | 0.867 | 0.948 | 0.923 | 0.846 | |
| 决策树 | Hamm[ | 0.724 | 0.742 | 0.824 | 0.737 |
| YBHU[ | 0.795 | 0.890 | 0.938 | 0.803 | |
| HUSP[ | 0.786 | 0.881 | 0.922 | 0.796 | |
| SHUM[ | 0.779 | 0.876 | 0.908 | 0.788 | |
| UTDHU_s | 0.802 | 0.896 | 0.943 | 0.815 | |
| UTDHU | 0.814 | 0.907 | 0.956 | 0.823 |
表6 基准事务集合上各个算法构造特征的分类准确率
Tab. 6 Classification accuracies of constructed features by each algorithm on benchmark transaction sets
| 模型 | 算法 | Connect | Covtype | Phishing | Phospep |
|---|---|---|---|---|---|
支持 向量机 | Hamm[ | 0.746 | 0.763 | 0.803 | 0.756 |
| YBHU[ | 0.845 | 0.933 | 0.907 | 0.824 | |
| HUSP[ | 0.824 | 0.925 | 0.892 | 0.818 | |
| SHUM[ | 0.816 | 0.919 | 0.883 | 0.811 | |
| UTDHU_s | 0.853 | 0.940 | 0.914 | 0.836 | |
| UTDHU | 0.867 | 0.948 | 0.923 | 0.846 | |
| 决策树 | Hamm[ | 0.724 | 0.742 | 0.824 | 0.737 |
| YBHU[ | 0.795 | 0.890 | 0.938 | 0.803 | |
| HUSP[ | 0.786 | 0.881 | 0.922 | 0.796 | |
| SHUM[ | 0.779 | 0.876 | 0.908 | 0.788 | |
| UTDHU_s | 0.802 | 0.896 | 0.943 | 0.815 | |
| UTDHU | 0.814 | 0.907 | 0.956 | 0.823 |
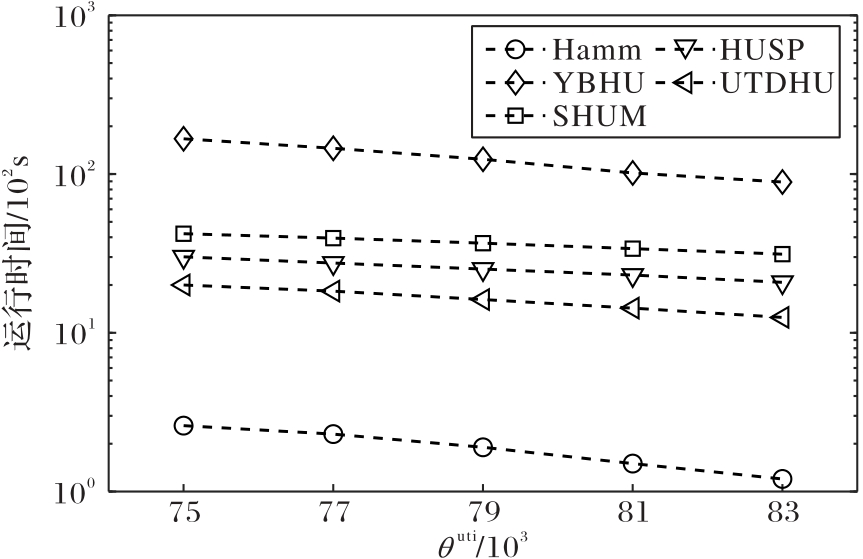
图4 各个算法在Phospep事务集合上的运行时间(θdis=2)
Fig. 4 Running time of each algorithm on Phospep transaction set (θdis=2)
| [1] | SINGH K, BISWAS B. Mining top-k high on-shelf utility itemsets using novel threshold raising strategies[J]. ACM Transactions on Knowledge Discovery from Data, 2024, 18(5): No.131. |
| [2] | ISLAM M A, RAFI M R, AZAD A A, et al. Weighted frequent sequential pattern mining[J]. Applied Intelligence, 2022, 52(1): 254-281. |
| [3] | KUMAR R, SINGH K. A survey on soft computing-based high-utility itemsets mining[J]. Soft Computing, 2022, 26(13): 6347-6392. |
| [4] | JENKINS S, WALZER-GOLDFELD S, RIONDATO M. SPEck: mining statistically-significant sequential patterns efficiently with exact sampling[J]. Data Mining and Knowledge Discovery, 2022, 36(4): 1575-1599. |
| [5] | LI Y, ZHANG C, LI J, et al. MCoR-Miner: maximal co-occurrence nonoverlapping sequential rule mining[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(9): 9531-9546. |
| [6] | 吴军,魏丹丹,欧阳艾嘉,等. 基于统计显著性检验的高效用项集挖掘算法[J]. 计算机应用研究, 2024, 41(10): 2970-2977. |
| WU J, WEI D D, OUYANG A J, et al. Mining high utility itemsets based on statistical significance testing[J]. Application Research of Computers, 2024, 41(10): 2970-2977. | |
| [7] | QU J F, FOURNIER-VIGER P, LIU M, et al. Mining high utility itemsets using prefix trees and utility vectors[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(10): 10224-10236. |
| [8] | WU Y, MENG Y, LI Y, et al. COPP-Miner: top-k contrast order-preserving pattern mining for time series classification[J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(6): 2372-2387. |
| [9] | DALLEIGER S, VREEKEN J. Discovering significant patterns under sequential false discovery control[C]// Proceedings of the 28th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2022: 263-272. |
| [10] | ABUISSA M, LEE A, RIONDATO M. ROhAN: row-order agnostic null models for statistically-sound knowledge discovery[J]. Data Mining and Knowledge Discovery, 2023, 37(4): 1692-1718. |
| [11] | 吴军,欧阳艾嘉,张琳. 基于影响度的统计显著序列模式挖掘算法[J]. 计算机应用, 2022, 42(9): 2713-2721. |
| WU J, OUYANG A J, ZHANG L. Statistically significant sequential patterns mining algorithm under influence degree[J]. Journal of Computer Applications, 2022, 42(9): 2713-2721. | |
| [12] | DAI C, LIN B, XING X, et al. False discovery rate control via data splitting[J]. Journal of the American Statistical Association, 2023, 118(544): 2503-2520. |
| [13] | PELLIZZONI P, BORGWARDT K. FASM and FAST-YB: significant pattern mining with false discovery rate control[C]// Proceedings of the 2023 IEEE International Conference on Data Mining. Piscataway: IEEE, 2023: 1265-1270. |
| [14] | TANG H J, QIAN J B, LIU Y G, et al. Mining statistically significant patterns with high utility[J]. International Journal of Computational Intelligence Systems, 2022, 15(1): No.88. |
| [15] | WANG J F, TANG H J, WANG L. Mining significant utility discriminative patterns in quantitative databases[J]. Mathematics, 2023, 11(4): No.950. |
| [16] | PELLEGRINA L. Efficient centrality maximization with Rademacher averages[C]// Proceedings of the 29th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2023: 1872-1884. |
| [17] | HAN M, GAO Z, LI A, et al. An overview of high utility itemsets mining methods based on intelligent optimization algorithms[J]. Knowledge and Information Systems, 2022, 64(11): 2945-2984. |
| [18] | 高智慧,韩萌,刘淑娟,等. 基于智能优化算法的高效用项集挖掘方法综述[J]. 计算机应用, 2023, 43(6): 1676-1686. |
| GAO Z H, HAN M, LIU S J, et al. Survey of high utility itemset mining methods based on intelligent optimization algorithm[J]. Journal of Computer Applications, 2023, 43(6): 1676-1686. | |
| [19] | 张妮,韩萌,王乐,等. 基于正负效用划分的高效用模式挖掘方法综述[J]. 计算机应用, 2022, 42(4): 999-1010. |
| ZHANG N, HAN M, WANG L, et al. Survey of high utility pattern mining methods based on positive and negative utility division[J]. Journal of Computer Applications, 2022, 42(4): 999-1010. | |
| [20] | KUMAR R, SINGH K. High utility itemsets mining from transactional databases: a survey[J]. Applied Intelligence, 2023, 53(22): 27655-27703. |
| [21] | FOURNIER-VIGER P, GAN W, WU Y, et al. Pattern mining: current challenges and opportunities[C]// Proceedings of the 2022 International Conference on Database Systems for Advanced Applications, LNCS 13248. Cham: Springer, 2022: 34-49. |
| [22] | MATHONAT R, NURBAKOVA D, BOULICAUT J F, et al. Anytime mining of sequential discriminative patterns in labeled sequences[J]. Knowledge and Information Systems, 2021, 63(2): 439-476. |
| [23] | WU Y, WANG Y, LI Y, et al. Top-k self-adaptive contrast sequential pattern mining[J]. IEEE Transactions on Cybernetics, 2022, 52(11): 11819-11833. |
| [24] | RIONDATO M. Statistically-sound knowledge discovery from data: challenges and directions[C]// Proceedings of the IEEE 5th International Conference on Cognitive Machine Intelligence. Piscataway: IEEE, 2023: 97-102. |
| [25] | LIU X, ZHAO Y, XU T, et al. Efficient false positive control algorithms in big data mining[J]. Applied Sciences, 2023, 13(8): No.5006. |
| [26] | PRETI G, DE FRANCISCI MORALES G, RIONDATO M. ALICE and the caterpillar: a more descriptive null model for assessing data mining results[J]. Knowledge and Information Systems, 2024, 66(3): 1917-1954. |
| [27] | TRAN T Q, FUKUCHI K, AKIMOTO Y, et al. Statistically significant pattern mining with ordinal utility[C]// Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2020: 1645-1655. |
| [28] | KIM H, YUN U, BAEK Y, et al. Efficient list based mining of high average utility patterns with maximum average pruning strategies[J]. Information Sciences, 2021, 543: 85-105. |
| [29] | PELLEGRINA L, COUSINS C, VANDIN F, et al. MCRapper: Monte-Carlo Rademacher averages for poset families and approximate pattern mining[J]. ACM Transactions on Knowledge Discovery from Data, 2022, 16(6): No.124. |
| [30] | COUSINS C, WOHLGEMUTH C, RIONDATO M. Bavarian: betweenness centrality approximation with variance-aware Rademacher averages[J]. ACM Transactions on Knowledge Discovery from Data, 2023, 17(6): No.78. |
| [31] | FOURNIER-VIGER P, GOMARIZ A, GUENICHE T, et al. SPMF: a Java open-source pattern mining library[J]. Journal of Machine Learning Research, 2014, 15: 3369-3373. |
| [32] | PINXTEREN S, CALDERS T. Efficient permutation testing for significant sequential patterns[C]// Proceedings of the 2021 SIAM International Conference on Data Mining. Philadelphia, PA: SIAM, 2021: 19-27. |
| [33] | ESMAILI F, POURMIRZAEI M, RAMAZI S, et al. A review of machine learning and algorithmic methods for protein phosphorylation sites prediction[J]. Genomics, Proteomics and Bioinformatics, 2023, 21(6): 1266-1285. |
| [1] | 李岚皓, 严皓钧, 周号益, 孙庆赟, 李建欣. 基于神经网络的多尺度信息融合时间序列长期预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1776-1783. |
| [2] | 李严, 叶冠华, 李雅文, 梁美玉. 基于丰度协调技术的企业ESG指标预测模型[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 670-676. |
| [3] | 李欢欢, 黄添强, 丁雪梅, 罗海峰, 黄丽清. 基于多尺度时空图卷积网络的交通出行需求预测[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2065-2072. |
| [4] | 董瑶, 付怡雪, 董永峰, 史进, 陈晨. 不完整多视图聚类综述[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1673-1682. |
| [5] | 杨克帅, 武优西, 耿萌, 刘靖宇, 李艳. 一次性条件下top-k高平均效用序列模式挖掘算法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 477-484. |
| [6] | 郑浩东, 马华, 谢颖超, 唐文胜. 融合遗忘因素与记忆门的图神经网络知识追踪模型[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2747-2752. |
| [7] | 蒋华, 李星, 王慧娇, 韦静海. 基于数据索引结构的跨级高效用项集挖掘算法[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2200-2208. |
| [8] | 黄硕, 李艳辉, 曹建秋. 本地化差分隐私下的频繁序列模式挖掘算法PrivSPM[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2057-2064. |
| [9] | 祁超帅, 何文思, 焦毅, 马英红, 蔡伟, 任素萍. 无人机飞行数据异常检测算法综述[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1833-1841. |
| [10] | 李元江, 权金升, 谭阳奕, 杨田. 基于相似和差异双视角的高维数据属性约简[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1467-1472. |
| [11] | 邵小萌, 张猛. 融合注意力机制的时间卷积知识追踪模型[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 343-348. |
| [12] | 李文全, 毛伊敏, 彭新东. 基于犹豫模糊集的凝聚式层次聚类算法[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3755-3763. |
| [13] | 吴军, 欧阳艾嘉, 张琳. 基于影响度的统计显著序列模式挖掘算法[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2713-2721. |
| [14] | 余顺坤, 闫泓序. 基于确定性因子的启发式属性值约简模型[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 469-474. |
| [15] | 刘世泽, 秦艳君, 王晨星, 苏琳, 柯其学, 罗海勇, 孙艺, 王宝会. 基于深度残差长短记忆网络交通流量预测算法[J]. 计算机应用, 2021, 41(6): 1566-1572. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||