


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (12): 3829-3838.DOI: 10.11772/j.issn.1001-9081.2024121797
郑天龙1,2,3, 董瑞1,2,3( ), 杨雅婷1,2,3, 马博1,2,3, 王磊1,2,3, 周喜1,2,3
), 杨雅婷1,2,3, 马博1,2,3, 王磊1,2,3, 周喜1,2,3
收稿日期:2024-12-23
修回日期:2025-03-06
接受日期:2025-03-13
发布日期:2025-03-24
出版日期:2025-12-10
通讯作者:
董瑞
作者简介:郑天龙(2002—),男,安徽阜阳人,硕士研究生,主要研究方向:隐喻检测基金资助:
Tianlong ZHENG1,2,3, Rui DONG1,2,3(), Yating YANG1,2,3, Bo MA1,2,3, Lei WANG1,2,3, Xi ZHOU1,2,3
Received:2024-12-23
Revised:2025-03-06
Accepted:2025-03-13
Online:2025-03-24
Published:2025-12-10
Contact:
Rui DONG
About author:ZHENG Tianlong, born in 2002, M. S. candidate. His research interests include metaphor detection.Supported by:摘要:
针对现有隐喻检测研究忽略了目标词在特定语境中存在多种语义(一词多义)时目标语句句义和目标词基本义不一致引起的隐喻发生问题,提出一种基于语言学多重不一致性的隐喻检测模型。首先,在特征编码模块,使用2个独立的编码器编码目标语句句义、目标词基本义和语境义等特征信息;其次,在多重不一致性建模模块,使用选择偏好违背(SPV)、隐喻识别程序(MIP)和语义用法对比(SUC)这3个语言学方法对多重不一致性特征进行统一建模;最后,利用隐喻识别模块进行隐喻检测。此外,通过LoRA(Low-Rank Adaptation)微调的大语言模型(LLM)和人工矫正结合的数据标注方法构建一个中文词级隐喻检测数据集META-ZH,以验证中文隐喻检测性能。实验结果表明,所提模型在VUA All、VUA Verb、MOH-X和META-ZH隐喻检测数据集上,对比最优基线模型,F1值分别提升了0.8、1.3、1.5和2.3个百分点。可见,该模型能够充分利用语言学多重不一致性有效提高隐喻检测性能。
中图分类号:
郑天龙, 董瑞, 杨雅婷, 马博, 王磊, 周喜. 基于语言学多重不一致性的隐喻检测模型[J]. 计算机应用, 2025, 45(12): 3829-3838.
Tianlong ZHENG, Rui DONG, Yating YANG, Bo MA, Lei WANG, Xi ZHOU. Metaphor detection model based on linguistic multi-incongruity[J]. Journal of Computer Applications, 2025, 45(12): 3829-3838.
| 隐喻发生情况 | 隐喻示例 | 适用方法 |
|---|---|---|
| 句法不一致 | 1)她吞下了他的谎言。 | SPV |
| 语境义与基本义不一致 | 2)他在这场讨论中占据了高地。 | MIP |
| 一词多义 | 3)在生活的雪坡上滑雪 一定要慢点,小心地滑。 | SUC |
表1 隐喻示例
Tab. 1 Examples of metaphor
| 隐喻发生情况 | 隐喻示例 | 适用方法 |
|---|---|---|
| 句法不一致 | 1)她吞下了他的谎言。 | SPV |
| 语境义与基本义不一致 | 2)他在这场讨论中占据了高地。 | MIP |
| 一词多义 | 3)在生活的雪坡上滑雪 一定要慢点,小心地滑。 | SUC |
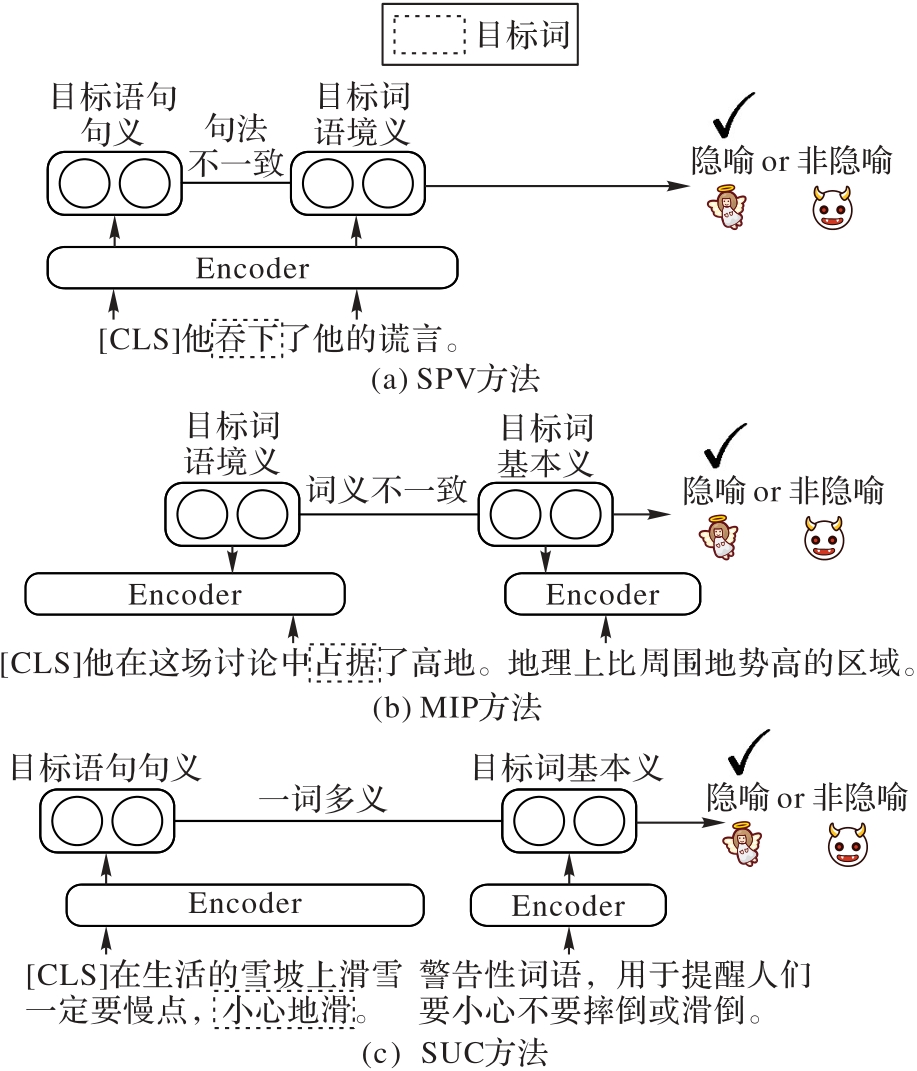
图1 SPV、MIP和SUC语言学方法
Fig. 1 SPV, MIP and SUC linguistic methods
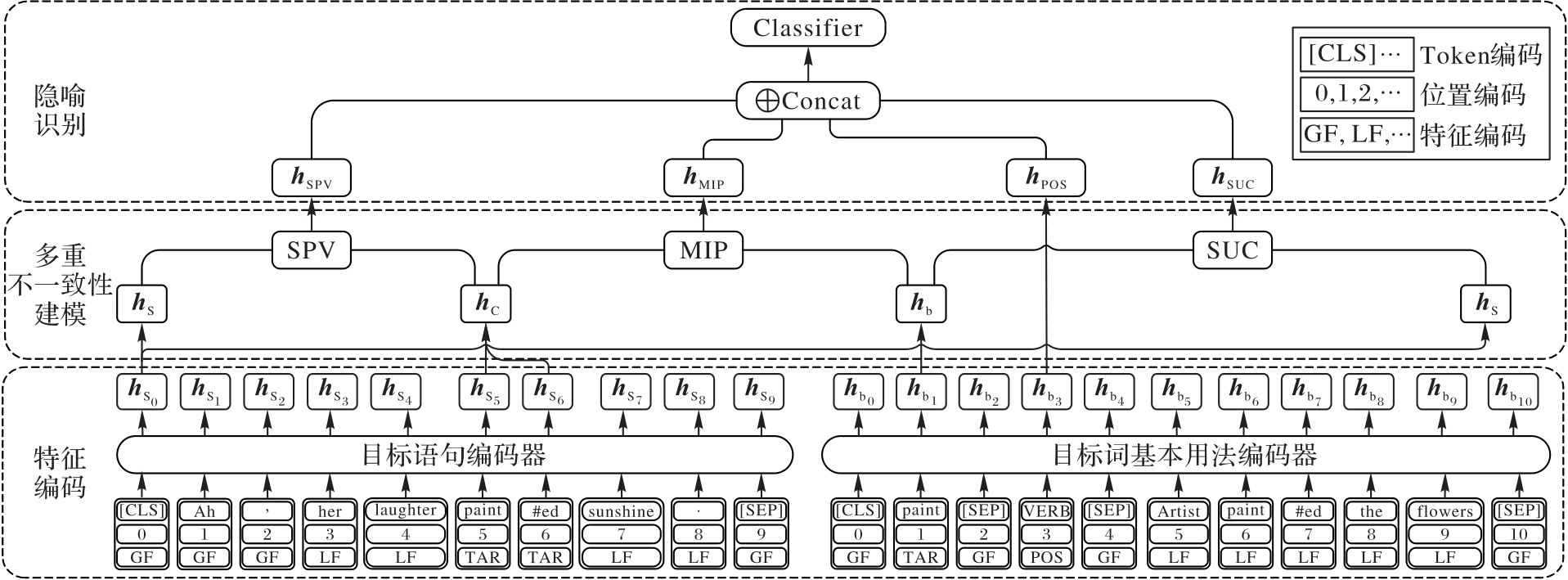
图2 MulNet模型的结构
Fig. 2 Structure of MulNet model
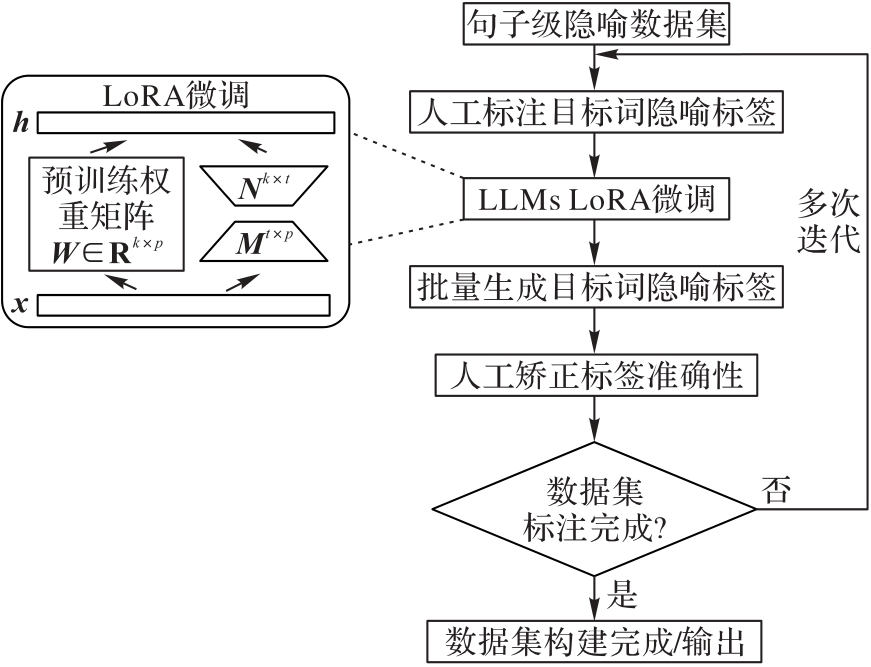
图3 META-ZH数据集的构造流程
Fig. 3 Flow of META-ZH dataset construction
| 数据集 | 目标语句数 | 目标词数 | 隐喻样本 占比/% | 目标语句 平均长度(词数) |
|---|---|---|---|---|
| MOH-X | 647 | 647 | 48.69 | 8.00 |
| VUA All | 10 488 | 205 425 | 11.58 | 19.55 |
| VUA Verb | 11 699 | 23 113 | 28.36 | 20.52 |
| TroFi | 3 737 | 3 737 | 43.54 | 28.30 |
| VUA All_Genre | 2 679 | 50 175 | 12.44 | 18.71 |
| VUA All_POS | 8 065 | 25 818 | 15.35 | 21.39 |
| META-ZH | 5 491 | 5 496 | 92.78 | 18.64 |
表2 数据集的描述性统计信息
Tab. 2 Descriptive statistics of datasets
| 数据集 | 目标语句数 | 目标词数 | 隐喻样本 占比/% | 目标语句 平均长度(词数) |
|---|---|---|---|---|
| MOH-X | 647 | 647 | 48.69 | 8.00 |
| VUA All | 10 488 | 205 425 | 11.58 | 19.55 |
| VUA Verb | 11 699 | 23 113 | 28.36 | 20.52 |
| TroFi | 3 737 | 3 737 | 43.54 | 28.30 |
| VUA All_Genre | 2 679 | 50 175 | 12.44 | 18.71 |
| VUA All_POS | 8 065 | 25 818 | 15.35 | 21.39 |
| META-ZH | 5 491 | 5 496 | 92.78 | 18.64 |
| 模型 | MOH-X | VUA All | VUA Verb | META-ZH | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | |
| RNN_ELMo | 75.6 | 77.2 | 79.1 | 73.5 | 72.6 | 93.1 | 71.6 | 73.6 | 69.7 | 81.4 | 68.2 | 71.3 | — | — | — | — |
| RNN_BERT | 78.2 | 78.1 | 75.1 | 81.8 | 71.7 | 92.9 | 71.5 | 71.9 | 69.0 | 80.7 | 66.7 | 71.5 | 76.5 | 93.9 | 77.0 | 76.0 |
| RNN_HG | 79.8 | 79.7 | 79.7 | 79.8 | 74.0 | 93.6 | 71.8 | 76.3 | 70.8 | 82.1 | 69.3 | 72.3 | — | — | — | — |
| RNN_MHCA | 80.0 | 79.8 | 77.5 | 83.1 | 74.3 | 93.8 | 73.0 | 73.0 | 70.5 | 81.8 | 66.3 | 75.2 | — | — | — | — |
| MUL_GCN | 79.6 | 79.9 | 79.7 | 80.5 | 75.1 | 93.8 | 74.8 | 75.5 | 71.7 | 83.2 | 72.5 | 70.9 | — | — | — | — |
| MelBERT | 81.1 | 81.6 | 79.7 | 82.7 | 78.4 | 94.0 | 80.5 | 76.4 | 71.0 | 80.7 | 64.6 | 78.8 | 76.4 | 94.9 | 84.4 | 71.8 |
| MisNet | 82.5 | 83.1 | 83.2 | 82.5 | 77.5 | 94.7 | 82.4 | 73.2 | 72.4 | 84.4 | 77.0 | 68.3 | 80.4 | 95.3 | 83.6 | 77.9 |
| MisNetDeBERTa | 85.0 | 85.6 | 86.2 | 84.6 | 70.3 | 91.7 | 63.2 | 79.1 | 70.4 | 82.2 | 70.3 | 70.5 | 80.0 | 95.0 | 81.8 | 78.4 |
| CLCL | 83.4 | 84.3 | 84.0 | 82.7 | 78.4 | 94.5 | 80.8 | 76.1 | 74.4 | 84.7 | 74.9 | 73.9 | 78.2 | 95.1 | 84.3 | 74.3 |
| QMM | 86.0 | 86.0 | 83.8 | 88.6 | 78.1 | 94.6 | 78.9 | 77.3 | 72.6 | 84.9 | 79.8 | 66.6 | — | — | — | — |
| QMMDeBERTa | 85.7 | 86.2 | 85.5 | 86.3 | 78.8 | 94.7 | 77.9 | 79.8 | 74.8 | 84.9 | 74.7 | 74.9 | — | — | — | — |
| MiniCPM3-4B(LoRA) | 75.7 | 73.8 | 70.7 | 81.5 | 74.9 | 94.0 | 78.2 | 71.9 | 65.9 | 80.4 | 68.9 | 63.1 | 72.7 | 93.2 | 74.1 | 71.5 |
| LLaMA3-8B(LoRA) | 64.3 | 68.5 | 74.0 | 56.9 | 76.2 | 94.3 | 79.9 | 72.8 | 73.5 | 84.7 | 76.6 | 70.6 | 80.0 | 94.6 | 79.5 | 80.5 |
| MulNet | 87.2 | 87.2 | 85.1 | 89.7 | 79.6 | 95.1 | 82.1 | 77.2 | 76.1 | 85.1 | 73.2 | 79.2 | 82.7 | 95.8 | 86.1 | 80.0 |
表3 MOH-X、VUA All、VUA Verb和META-ZH数据集上的实验结果 (%)
Tab. 3 Experimental results on MOH-X, VUA All, VUA Verb and META-ZH datasets
| 模型 | MOH-X | VUA All | VUA Verb | META-ZH | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | |
| RNN_ELMo | 75.6 | 77.2 | 79.1 | 73.5 | 72.6 | 93.1 | 71.6 | 73.6 | 69.7 | 81.4 | 68.2 | 71.3 | — | — | — | — |
| RNN_BERT | 78.2 | 78.1 | 75.1 | 81.8 | 71.7 | 92.9 | 71.5 | 71.9 | 69.0 | 80.7 | 66.7 | 71.5 | 76.5 | 93.9 | 77.0 | 76.0 |
| RNN_HG | 79.8 | 79.7 | 79.7 | 79.8 | 74.0 | 93.6 | 71.8 | 76.3 | 70.8 | 82.1 | 69.3 | 72.3 | — | — | — | — |
| RNN_MHCA | 80.0 | 79.8 | 77.5 | 83.1 | 74.3 | 93.8 | 73.0 | 73.0 | 70.5 | 81.8 | 66.3 | 75.2 | — | — | — | — |
| MUL_GCN | 79.6 | 79.9 | 79.7 | 80.5 | 75.1 | 93.8 | 74.8 | 75.5 | 71.7 | 83.2 | 72.5 | 70.9 | — | — | — | — |
| MelBERT | 81.1 | 81.6 | 79.7 | 82.7 | 78.4 | 94.0 | 80.5 | 76.4 | 71.0 | 80.7 | 64.6 | 78.8 | 76.4 | 94.9 | 84.4 | 71.8 |
| MisNet | 82.5 | 83.1 | 83.2 | 82.5 | 77.5 | 94.7 | 82.4 | 73.2 | 72.4 | 84.4 | 77.0 | 68.3 | 80.4 | 95.3 | 83.6 | 77.9 |
| MisNetDeBERTa | 85.0 | 85.6 | 86.2 | 84.6 | 70.3 | 91.7 | 63.2 | 79.1 | 70.4 | 82.2 | 70.3 | 70.5 | 80.0 | 95.0 | 81.8 | 78.4 |
| CLCL | 83.4 | 84.3 | 84.0 | 82.7 | 78.4 | 94.5 | 80.8 | 76.1 | 74.4 | 84.7 | 74.9 | 73.9 | 78.2 | 95.1 | 84.3 | 74.3 |
| QMM | 86.0 | 86.0 | 83.8 | 88.6 | 78.1 | 94.6 | 78.9 | 77.3 | 72.6 | 84.9 | 79.8 | 66.6 | — | — | — | — |
| QMMDeBERTa | 85.7 | 86.2 | 85.5 | 86.3 | 78.8 | 94.7 | 77.9 | 79.8 | 74.8 | 84.9 | 74.7 | 74.9 | — | — | — | — |
| MiniCPM3-4B(LoRA) | 75.7 | 73.8 | 70.7 | 81.5 | 74.9 | 94.0 | 78.2 | 71.9 | 65.9 | 80.4 | 68.9 | 63.1 | 72.7 | 93.2 | 74.1 | 71.5 |
| LLaMA3-8B(LoRA) | 64.3 | 68.5 | 74.0 | 56.9 | 76.2 | 94.3 | 79.9 | 72.8 | 73.5 | 84.7 | 76.6 | 70.6 | 80.0 | 94.6 | 79.5 | 80.5 |
| MulNet | 87.2 | 87.2 | 85.1 | 89.7 | 79.6 | 95.1 | 82.1 | 77.2 | 76.1 | 85.1 | 73.2 | 79.2 | 82.7 | 95.8 | 86.1 | 80.0 |
| 模型 | Fiction | News | Conversation | Academic | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | |
| RNN_ELMo | 65.1 | 93.1 | 61.4 | 69.1 | 71.9 | 91.6 | 72.7 | 71.2 | 79.2 | 92.8 | 78.2 | 80.2 | 64.0 | 94.6 | 64.9 | 63.1 |
| RNN_BERT | 67.5 | 93.9 | 66.5 | 68.6 | 71.8 | 91.4 | 71.2 | 72.5 | 76.4 | 91.9 | 76.7 | 76.0 | 64.4 | 94.6 | 64.7 | 64.2 |
| RNN_HG | 67.5 | 93.4 | 61.8 | 74.5 | 74.1 | 91.9 | 71.6 | 76.8 | 79.6 | 92.7 | 76.5 | 83.0 | 67.8 | 94.8 | 63.6 | 72.5 |
| RNN_MHCA | 67.7 | 93.8 | 64.8 | 70.9 | 75.0 | 92.4 | 74.8 | 75.3 | 79.8 | 93.0 | 79.6 | 80.0 | 67.4 | 94.8 | 64.0 | 71.1 |
| RoBERTa_SEQ | 73.3 | — | 73.9 | 72.7 | 77.9 | — | 82.2 | 74.1 | 81.4 | — | 86.0 | 77.3 | 70.1 | — | 70.5 | 69.8 |
| DeepMet | 73.0 | — | 76.1 | 70.1 | 75.0 | — | 84.1 | 67.6 | 81.0 | — | 88.4 | 74.7 | 71.4 | — | 71.6 | 71.1 |
| MelBERT | 75.4 | — | 74.0 | 76.8 | 77.2 | — | 81.0 | 73.7 | 83.9 | — | 85.3 | 82.5 | 70.9 | — | 70.1 | 71.7 |
| MisNet | 76.0 | 95.5 | 74.5 | 77.5 | 79.2 | 94.1 | 82.6 | 77.0 | 83.8 | 94.5 | 85.1 | 82.5 | 71.9 | 95.7 | 71.8 | 72.2 |
| MulNet | 76.7 | 95.7 | 76.5 | 76.9 | 80.3 | 94.4 | 86.1 | 75.2 | 84.3 | 94.7 | 87.4 | 81.4 | 72.3 | 95.5 | 70.3 | 74.4 |
| 模型 | Noun | Adjective | Verb | Adverb | ||||||||||||
| F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | |
| RNN_ELMo | 60.4 | — | 59.9 | 60.8 | 58.3 | — | 56.1 | 60.6 | 69.9 | — | 68.1 | 71.9 | 59.7 | 94.8 | 67.2 | 53.7 |
| RNN_BERT | 59.9 | 88.6 | 63.3 | 56.8 | 54.7 | 88.3 | 58.1 | 51.6 | 69.5 | 87.9 | 67.1 | 72.1 | 62.9 | 94.8 | 64.8 | 61.1 |
| RNN_HG | 63.4 | 88.4 | 60.3 | 66.8 | 62.2 | 89.1 | 59.2 | 65.6 | 70.7 | 88.0 | 66.4 | 75.5 | 63.8 | 94.5 | 61.0 | 66.8 |
| RNN_MHCA | 63.2 | 89.4 | 69.1 | 58.2 | 61.6 | 89.5 | 61.4 | 61.7 | 70.7 | 87.9 | 66.0 | 76.0 | 63.2 | 94.9 | 66.1 | 60.7 |
| RoBERTa_SEQ | 66.6 | — | 76.5 | 59.0 | 63.7 | — | 72.0 | 57.1 | 74.8 | — | 74.4 | 75.1 | 70.1 | — | 77.6 | 63.9 |
| DeepMet | 65.4 | — | 76.5 | 57.1 | 63.3 | — | 79.0 | 52.9 | 73.3 | — | 78.8 | 68.5 | 72.3 | — | 79.4 | 66.4 |
| MelBERT | 70.7 | — | 75.4 | 66.5 | 64.4 | — | 69.4 | 60.1 | 75.1 | — | 74.2 | 75.9 | 74.6 | — | 80.2 | 69.7 |
| MisNet | 70.6 | 91.6 | 74.4 | 67.2 | 67.0 | 91.2 | 68.8 | 65.2 | 77.6 | 91.4 | 77.5 | 77.7 | 73.3 | 96.3 | 76.4 | 70.5 |
| MulNet | 71.7 | 92.2 | 78.3 | 66.2 | 69.4 | 92.3 | 75.9 | 64.0 | 77.8 | 91.5 | 77.1 | 78.6 | 76.0 | 96.7 | 79.7 | 72.5 |
表4 细分数据集VUA All_Genre和VUA All_POS上的实验结果 (%)
Tab. 4 Experimental results on subdivision datasets VUA All_Genre and VUA All_POS
| 模型 | Fiction | News | Conversation | Academic | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | |
| RNN_ELMo | 65.1 | 93.1 | 61.4 | 69.1 | 71.9 | 91.6 | 72.7 | 71.2 | 79.2 | 92.8 | 78.2 | 80.2 | 64.0 | 94.6 | 64.9 | 63.1 |
| RNN_BERT | 67.5 | 93.9 | 66.5 | 68.6 | 71.8 | 91.4 | 71.2 | 72.5 | 76.4 | 91.9 | 76.7 | 76.0 | 64.4 | 94.6 | 64.7 | 64.2 |
| RNN_HG | 67.5 | 93.4 | 61.8 | 74.5 | 74.1 | 91.9 | 71.6 | 76.8 | 79.6 | 92.7 | 76.5 | 83.0 | 67.8 | 94.8 | 63.6 | 72.5 |
| RNN_MHCA | 67.7 | 93.8 | 64.8 | 70.9 | 75.0 | 92.4 | 74.8 | 75.3 | 79.8 | 93.0 | 79.6 | 80.0 | 67.4 | 94.8 | 64.0 | 71.1 |
| RoBERTa_SEQ | 73.3 | — | 73.9 | 72.7 | 77.9 | — | 82.2 | 74.1 | 81.4 | — | 86.0 | 77.3 | 70.1 | — | 70.5 | 69.8 |
| DeepMet | 73.0 | — | 76.1 | 70.1 | 75.0 | — | 84.1 | 67.6 | 81.0 | — | 88.4 | 74.7 | 71.4 | — | 71.6 | 71.1 |
| MelBERT | 75.4 | — | 74.0 | 76.8 | 77.2 | — | 81.0 | 73.7 | 83.9 | — | 85.3 | 82.5 | 70.9 | — | 70.1 | 71.7 |
| MisNet | 76.0 | 95.5 | 74.5 | 77.5 | 79.2 | 94.1 | 82.6 | 77.0 | 83.8 | 94.5 | 85.1 | 82.5 | 71.9 | 95.7 | 71.8 | 72.2 |
| MulNet | 76.7 | 95.7 | 76.5 | 76.9 | 80.3 | 94.4 | 86.1 | 75.2 | 84.3 | 94.7 | 87.4 | 81.4 | 72.3 | 95.5 | 70.3 | 74.4 |
| 模型 | Noun | Adjective | Verb | Adverb | ||||||||||||
| F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | F1 | Acc | Prec | Rec | |
| RNN_ELMo | 60.4 | — | 59.9 | 60.8 | 58.3 | — | 56.1 | 60.6 | 69.9 | — | 68.1 | 71.9 | 59.7 | 94.8 | 67.2 | 53.7 |
| RNN_BERT | 59.9 | 88.6 | 63.3 | 56.8 | 54.7 | 88.3 | 58.1 | 51.6 | 69.5 | 87.9 | 67.1 | 72.1 | 62.9 | 94.8 | 64.8 | 61.1 |
| RNN_HG | 63.4 | 88.4 | 60.3 | 66.8 | 62.2 | 89.1 | 59.2 | 65.6 | 70.7 | 88.0 | 66.4 | 75.5 | 63.8 | 94.5 | 61.0 | 66.8 |
| RNN_MHCA | 63.2 | 89.4 | 69.1 | 58.2 | 61.6 | 89.5 | 61.4 | 61.7 | 70.7 | 87.9 | 66.0 | 76.0 | 63.2 | 94.9 | 66.1 | 60.7 |
| RoBERTa_SEQ | 66.6 | — | 76.5 | 59.0 | 63.7 | — | 72.0 | 57.1 | 74.8 | — | 74.4 | 75.1 | 70.1 | — | 77.6 | 63.9 |
| DeepMet | 65.4 | — | 76.5 | 57.1 | 63.3 | — | 79.0 | 52.9 | 73.3 | — | 78.8 | 68.5 | 72.3 | — | 79.4 | 66.4 |
| MelBERT | 70.7 | — | 75.4 | 66.5 | 64.4 | — | 69.4 | 60.1 | 75.1 | — | 74.2 | 75.9 | 74.6 | — | 80.2 | 69.7 |
| MisNet | 70.6 | 91.6 | 74.4 | 67.2 | 67.0 | 91.2 | 68.8 | 65.2 | 77.6 | 91.4 | 77.5 | 77.7 | 73.3 | 96.3 | 76.4 | 70.5 |
| MulNet | 71.7 | 92.2 | 78.3 | 66.2 | 69.4 | 92.3 | 75.9 | 64.0 | 77.8 | 91.5 | 77.1 | 78.6 | 76.0 | 96.7 | 79.7 | 72.5 |
| 模型 | F1 | Acc | Prec | Rec |
|---|---|---|---|---|
| RoBERTa_SEQ | 60.7 | 60.6 | 53.6 | 70.1 |
| DeepMet | 61.7 | 60.8 | 53.7 | 72.9 |
| MelBERT | 62.0 | 60.6 | 53.4 | 74.1 |
| MrBERT | 62.7 | 61.1 | 53.8 | 75.0 |
| MisNet | 63.1 | 61.2 | 53.8 | 76.2 |
| RoPPT | 63.3 | 61.6 | 54.2 | 76.2 |
| MiceCL | 62.9 | 61.5 | 54.2 | 75.0 |
| MulNet | 64.2 | 62.7 | 55.1 | 77.0 |
表5 TroFi数据集上的Zero-shot迁移实验结果 (%)
Tab. 5 Zero-shot transfer experimental results on TroFi dataset
| 模型 | F1 | Acc | Prec | Rec |
|---|---|---|---|---|
| RoBERTa_SEQ | 60.7 | 60.6 | 53.6 | 70.1 |
| DeepMet | 61.7 | 60.8 | 53.7 | 72.9 |
| MelBERT | 62.0 | 60.6 | 53.4 | 74.1 |
| MrBERT | 62.7 | 61.1 | 53.8 | 75.0 |
| MisNet | 63.1 | 61.2 | 53.8 | 76.2 |
| RoPPT | 63.3 | 61.6 | 54.2 | 76.2 |
| MiceCL | 62.9 | 61.5 | 54.2 | 75.0 |
| MulNet | 64.2 | 62.7 | 55.1 | 77.0 |
| 消融 | F1 | Acc | Prec | Rec |
|---|---|---|---|---|
| w/o MIP | 79.4 | 95.1 | 82.3 | 76.7 |
| w/o SPV | 79.4 | 95.0 | 81.9 | 77.1 |
| w/o SUC | 78.3 | 94.9 | 82.7 | 74.4 |
| w/o POS | 79.1 | 95.0 | 83.1 | 75.5 |
| w/o Basic Usage | 78.4 | 94.8 | 81.7 | 75.3 |
| w/o Feature Embedding | 78.7 | 94.9 | 81.7 | 76.0 |
| MulNet | 79.6 | 95.1 | 82.1 | 77.2 |
表6 多重不一致性特征的消融实验结果 (%)
Tab. 6 Ablation experimental results of multi-incongruity features
| 消融 | F1 | Acc | Prec | Rec |
|---|---|---|---|---|
| w/o MIP | 79.4 | 95.1 | 82.3 | 76.7 |
| w/o SPV | 79.4 | 95.0 | 81.9 | 77.1 |
| w/o SUC | 78.3 | 94.9 | 82.7 | 74.4 |
| w/o POS | 79.1 | 95.0 | 83.1 | 75.5 |
| w/o Basic Usage | 78.4 | 94.8 | 81.7 | 75.3 |
| w/o Feature Embedding | 78.7 | 94.9 | 81.7 | 76.0 |
| MulNet | 79.6 | 95.1 | 82.1 | 77.2 |
| 消融 | F1 | Acc | Prec | Rec |
|---|---|---|---|---|
| w/o ( | 78.8 | 94.9 | 81.9 | 75.8 |
| w/o ( | 78.9 | 94.9 | 82.0 | 76.1 |
| w/o ( | 79.2 | 95.0 | 82.4 | 76.2 |
| w/o ( | 79.2 | 94.9 | 80.6 | 77.9 |
| w/o ( | 79.0 | 94.9 | 81.5 | 76.6 |
| w/o ( | 78.9 | 94.9 | 81.1 | 76.8 |
| MulNet | 79.6 | 95.1 | 82.1 | 77.2 |
表7 MulNet不同特征集成方法的消融实验结果 (%)
Tab. 7 Ablation experimental results of different feature ensemble methods in MulNet
| 消融 | F1 | Acc | Prec | Rec |
|---|---|---|---|---|
| w/o ( | 78.8 | 94.9 | 81.9 | 75.8 |
| w/o ( | 78.9 | 94.9 | 82.0 | 76.1 |
| w/o ( | 79.2 | 95.0 | 82.4 | 76.2 |
| w/o ( | 79.2 | 94.9 | 80.6 | 77.9 |
| w/o ( | 79.0 | 94.9 | 81.5 | 76.6 |
| w/o ( | 78.9 | 94.9 | 81.1 | 76.8 |
| MulNet | 79.6 | 95.1 | 82.1 | 77.2 |
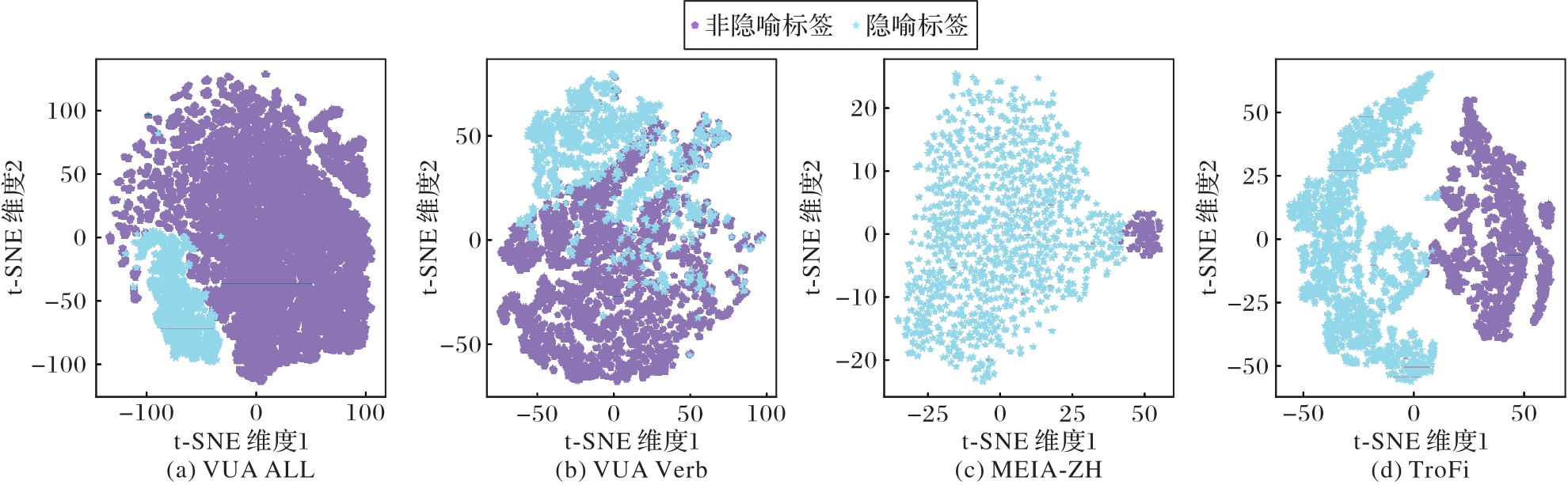
图4 VUA All、VUA Verb、META-ZH、TroFi数据集上的t-SNE特征可视化
Fig. 4 t-SNE feature visualization on VUA All, VUA Verb, META-ZH and TroFi datasets
| 语言 | 目标词 | 目标语句 | 真实值 | 预测值 |
|---|---|---|---|---|
| 中文 | 讹诈 | 1) 新中国成立后,为了打破某些大国的核讹诈,发展国防核能工业,中央对原子能的原料资源铀矿的勘查 非常重视。 | 隐喻 | 隐喻 |
| 循 | 2) 接着,我们循着喊声,又走进“小芙蓉”美容美发店。 | 非隐喻 | 非隐喻 | |
| 流动 | 3) 在这种流动中,最使人感念的是父母的牺牲。 | 非隐喻 | 隐喻 | |
| 开启 | 4) 正是这位智慧的老人最先开启国门,推船下海的。 | 隐喻 | 非隐喻 | |
| 英文 | hands | 1) Money may not have changed hands. | 隐喻 | 隐喻 |
| capacity | 2) Five more incinerators currently proposed in various parts of the country will double capacity. | 非隐喻 | 非隐喻 | |
| bear | 3) There are a number of points to bear in mind. | 隐喻 | 隐喻 | |
| vague | 4) PEOPLE tend to look vague when you mention Poitou. | 隐喻 | 非隐喻 |
表8 中英文隐喻检测示例
Tab. 8 Examples of metaphor detection in Chinese and English
| 语言 | 目标词 | 目标语句 | 真实值 | 预测值 |
|---|---|---|---|---|
| 中文 | 讹诈 | 1) 新中国成立后,为了打破某些大国的核讹诈,发展国防核能工业,中央对原子能的原料资源铀矿的勘查 非常重视。 | 隐喻 | 隐喻 |
| 循 | 2) 接着,我们循着喊声,又走进“小芙蓉”美容美发店。 | 非隐喻 | 非隐喻 | |
| 流动 | 3) 在这种流动中,最使人感念的是父母的牺牲。 | 非隐喻 | 隐喻 | |
| 开启 | 4) 正是这位智慧的老人最先开启国门,推船下海的。 | 隐喻 | 非隐喻 | |
| 英文 | hands | 1) Money may not have changed hands. | 隐喻 | 隐喻 |
| capacity | 2) Five more incinerators currently proposed in various parts of the country will double capacity. | 非隐喻 | 非隐喻 | |
| bear | 3) There are a number of points to bear in mind. | 隐喻 | 隐喻 | |
| vague | 4) PEOPLE tend to look vague when you mention Poitou. | 隐喻 | 非隐喻 |
| [1] | LAKOFF G, JOHNSON M. Conceptual metaphor in everyday language[M]// SARASVATHY S, DEW N, VENKATARAMAN S. Shaping entrepreneurship research: made, as well as found. London: Routledge, 2020: 475-504. |
| [2] | LAKOFF G, JOHNSON M. Metaphors we live by[M]. Chicago: University of Chicago Press, 2003: 201-207. |
| [3] | SUARDANA I K. Grammatical metaphor in Pan BalangTamak: systemic functional linguistics perspective[J]. International Journal of Linguistics and Discourse Analytics, 2020, 2(1): 14-28. |
| [4] | BOSMAN N. The cup as metaphor and symbol: a cognitive linguistics perspective[J]. HTS Teologiese Studies/Theological Studies, 2019, 75(3): No.a5338. |
| [5] | FAXRIDDIN QIZI M U, TURSINALI QIZI M M, SHUXRAT QIZI N M, et al. The theoretical approaches to the study of metaphor in a cognitive aspect[J]. International Journal of Early Childhood Special Education, 2022(14): 959-962. |
| [6] | TONG X, SHUTOVA E, LEWIS M. Recent advances in neural metaphor processing: a linguistic, cognitive and social perspective[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 4673-4686. |
| [7] | GROUP P. MIP: a method for identifying metaphorically used words in discourse [J]. Metaphor and Symbol, 2007, 22(1): 1-39. |
| [8] | WILKS Y. A preferential, pattern-seeking, semantics for natural language inference[J]. Artificial Intelligence, 1975, 6(1): 53-74. |
| [9] | FASS D, WILKS Y. Preference semantics, ill-formedness, and metaphor[J]. American Journal of Computational Linguistics, 1983, 9(3/4): 178-187. |
| [10] | SONG Z, TIAN S, YU L, et al. Multi-task metaphor detection based on linguistic theory[J]. Multimedia Tools and Applications, 2024, 83(24): 64065-64078. |
| [11] | FENG H, MA Q. It’s better to teach fishing than giving a fish: an auto-augmented structure-aware generative model for metaphor detection[C]// Findings of the Association for Computational Linguistics: EMNLP 2022. Stroudsburg: ACL, 2022: 656-667. |
| [12] | YANG C, LI Z, LIU Z, et al. Deep learning-based knowledge injection for metaphor detection: a comprehensive review[EB/OL]. [2025-02-25].. |
| [13] | 张声龙,刘颖,马艳军. SaGE:基于句法感知图卷积神经网络和ELECTRA的中文隐喻识别模型[J]. 中文信息学报, 2024, 38(3): 24-32. |
| ZHANG S L, LIU Y, MA Y J. SaGE: syntax-aware GCN with ELECTRA for Chinese metaphor detection[J]. Journal of Chinese Information Processing, 2024, 38(3): 24-32. | |
| [14] | ZHANG L, YU L, TIAN S, et al. Sequential verb metaphor detection with linguistic theories[J]. Journal of Intelligent and Fuzzy Systems, 2022, 43(3): 2765-2775. |
| [15] | SU C, WU K, CHEN Y. Enhanced metaphor detection via incorporation of external knowledge based on linguistic theories[C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg: ACL, 2021: 1280-1287. |
| [16] | HU E J, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models[EB/OL]. [2025-02-25].. |
| [17] | PRAMANICK M, GUPTA A, MITRA P. An LSTM-CRF based approach to token-level metaphor detection[C]// Proceedings of the 2018 Workshop on Figurative Language Processing. Stroudsburg: ACL, 2018: 67-75. |
| [18] | CHEN X, HAI Z, WANG S, et al. Metaphor identification: a contextual inconsistency based neural sequence labeling approach[J]. Neurocomputing, 2021, 428: 268-279. |
| [19] | LI S, ZENG J, ZHANG J, et al. Albert-BiLSTM for sequential metaphor detection[C]// Proceedings of the 2nd Workshop on Figurative Language Processing. Stroudsburg: ACL, 2020: 110-115. |
| [20] | SUN S, XIE Z. BiLSTM-based models for metaphor detection[C]// Proceedings of the 2017 CCF International Conference on Natural Language Processing and Chinese Computing, LNCS 10619. Cham: Springer, 2018: 431-442. |
| [21] | ZAYED O, McCRAE J P, BUITELAAR P. Contextual modulation for relation-level metaphor identification[C]// Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg: ACL, 2020: 388-406. |
| [22] | GONG H, GUPTA K, JAIN A, et al. IlliniMet: Illinois system for metaphor detection with contextual and linguistic information[C]// Proceedings of the 2nd Workshop on Figurative Language Processing. Stroudsburg: ACL, 2020: 146-153. |
| [23] | SU C, FUKUMOTO F, HUANG X, et al. DeepMet: a reading comprehension paradigm for token-level metaphor detection[C]// Proceedings of the 2nd Workshop on Figurative Language Processing. Stroudsburg: ACL, 2020: 30-39. |
| [24] | LI S, YANG L, HE W, et al. Label-enhanced hierarchical contextualized representation for sequential metaphor identification[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 3533-3543. |
| [25] | SONG W, ZHOU S, FU R, et al. Verb metaphor detection via contextual relation learning[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 4240-4251. |
| [26] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019: 4171-4186. |
| [27] | WAN H, LIN J, DU J, et al. Enhancing metaphor detection by gloss-based interpretations[C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg: ACL, 2021: 1971-1981. |
| [28] | CHOI M, LEE S, CHOI E, et al. MelBERT: metaphor detection via contextualized late interaction using metaphorical identification theories[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 1763-1773. |
| [29] | ZHANG S, LIU Y. Metaphor detection via linguistics enhanced Siamese network[C]// Proceedings of the 29th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2022: 4149-4159. |
| [30] | GE M, MAO R, CAMBRIA E. Explainable metaphor identification inspired by conceptual metaphor theory[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 10681-10689. |
| [31] | LI Y, WANG S, LIN C, et al. Metaphor detection via explicit basic meanings modelling[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg: ACL, 2023: 91-100. |
| [32] | LIU X, ZHAO G. A comparative study of emotion metaphors between English and Chinese[J]. Theory and Practice in Language Studies, 2013, 3(1): 155-162. |
| [33] | BARNDEN J. Broadly reflexive relationships, a special type of hyperbole, and implications for metaphor and metonymy[J]. Metaphor and Symbol, 2018, 33(3): 218-234. |
| [34] | DANKERS V, REI M, LEWIS M, et al. Modelling the interplay of metaphor and emotion through multitask learning[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 2218-2229. |
| [35] | LE D M, THAI M, NGUYEN T H. Multi-task learning for metaphor detection with graph convolutional neural networks and word sense disambiguation[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 8139-8146. |
| [36] | ZHANG S, LIU Y. Adversarial multi-task learning for end-to-end metaphor detection[C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 1483-1497. |
| [37] | BADATHALA N, RAJAKUMAR KALARANI A, SILEDAR T, et al. A match made in heaven: a multi-task framework for hyperbole and metaphor detection[C]// Findings of the Association for Computational Linguistics: ACL 2023. Stroudsburg: ACL, 2023: 388-401. |
| [38] | TIAN Y, XU N, MAO W. A theory guided scaffolding instruction framework for LLM-enabled metaphor reasoning[C]// Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 7738-7755. |
| [39] | WANG J, WANG J, ZHANG X. Chinese metaphor recognition using a multi-stage prompting large language model [EB/OL]. [2025-02-25]. . |
| [40] | XIAO K, YANG L, ZHANG X, et al. Combining LLM efficiency with human expertise: addressing systematic biases in figurative language detection[EB/OL]. [2025-02-25].. |
| [41] | SENNRICH R, HADDOW B, BIRCH A. Neural machine translation of rare words with subword units[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2016: 1715-1725. |
| [42] | HU S, TU Y, HAN X, et al. MiniCPM: unveiling the potential of small language models with scalable training strategies[EB/OL]. [2025-02-25].. |
| [43] | ZHENG Y, ZHANG R, ZHANG J, et al. LlamaFactory: unified efficient fine-tuning of 100+ language models[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). Stroudsburg: ACL, 2024: 400-410. |
| [44] | MOHAMMAD S, SHUTOVA E, TURNEY P. Metaphor as a medium for emotion: an empirical study[C]// Proceedings of the 5th Joint Conference on Lexical and Computational Semantics. Stroudsburg: ACL, 2016: 23-33. |
| [45] | STEHEN G J, DORST A G, HERRMANN J B, et al. A method for linguistic metaphor identification: from MIP to MIPVU preface[M]. Amsterdam: John Benjamins Publishing Company, 2010. |
| [46] | BIRKE J, SARKAR A. A clustering approach for nearly unsupervised recognition of nonliteral language[C]// Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg: ACL, 2006: 329-336. |
| [47] | BIRKE J, SARKAR A. Active learning for the identification of nonliteral language[C]// Proceedings of the 2007 Workshop on Computational Approaches to Figurative Language. Stroudsburg: ACL, 2007: 21-28. |
| [48] | GAO G, CHOI E, CHOI Y, et al. Neural metaphor detection in context[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 607-613. |
| [49] | MAO R, LIN C, GUERIN F. End-to-end sequential metaphor identification inspired by linguistic theories[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 3888-3898. |
| [50] | PENNINGTON J, SOCHER R, MANNING C D. GloVe: global vectors for word representation[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2014: 1532-1543. |
| [51] | C W (B) LEONG, KLEBANOV B B, HAMILL C, et al. A report on the 2020 VUA and TOEFL metaphor detection shared task[C]// Proceedings of the 2nd Workshop on Figurative Language Processing. Stroudsburg: ACL, 2020: 18-29. |
| [52] | WANG S, LI Y, LIN C, et al. Metaphor detection with effective context denoising[C]// Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg: ACL, 2023: 1404-1409. |
| [53] | ZHOU J, ZENG Z, BHAT S. CLCL: non-compositional expression detection with contrastive learning and curriculum learning[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 730-743. |
| [54] | JIA K, LI R. Metaphor detection with context enhancement and curriculum learning[C]// Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Stroudsburg: ACL, 2024: 2726-2737. |
| [55] | QIAO W, ZHANG P, MA Z L. A quantum-inspired matching network with linguistic theories for metaphor detection[C]// Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation. [S.l.]: ELRA and ICCL, 2024: 1435-1445. |
| [56] | META AI. Introducing Meta Llama 3: the most capable openly available LLM to date[EB/OL]. [2025-02-25]. . |
| [57] | TENENBAUM J B, DE SILVA V, LANGFORD J C. A global geometric framework for nonlinear dimensionality reduction[J]. Science, 2000, 290(5500): 2319-2323. |
| [1] | 谢欣冉, 崔喆, 陈睿, 彭泰来, 林德坤. 基于层次过滤与标签语义扩展的大模型零样本重排序方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 60-68. |
| [2] | 林怡, 夏冰, 王永, 孟顺达, 刘居宠, 张书钦. 基于AI智能体的隐藏RESTful API识别与漏洞检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(1): 135-143. |
| [3] | 张滨滨, 秦永彬, 黄瑞章, 陈艳平. 结合大语言模型与动态提示的裁判文书摘要方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2783-2789. |
| [4] | 冯涛, 刘晨. 自动化偏好对齐的双阶段提示调优方法[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2442-2447. |
| [5] | 孙熠衡, 刘茂福. 基于知识提示微调的标书信息抽取方法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1169-1176. |
| [6] | 何静, 沈阳, 谢润锋. 大语言模型幻觉现象的识别与优化[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 709-714. |
| [7] | 陈维, 施昌勇, 马传香. 基于多模态数据融合的农作物病害识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 840-848. |
| [8] | 张学飞, 张丽萍, 闫盛, 侯敏, 赵宇博. 知识图谱与大语言模型协同的个性化学习推荐[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 773-784. |
| [9] | 徐月梅, 叶宇齐, 何雪怡. 大语言模型的偏见挑战:识别、评估与去除[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 697-708. |
| [10] | 杨燕, 叶枫, 许栋, 张雪洁, 徐津. 融合大语言模型和提示学习的数字孪生水利知识图谱构建[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 785-793. |
| [11] | 鲁超峰, 陶冶, 文连庆, 孟菲, 秦修功, 杜永杰, 田云龙. 融合大语言模型和预训练模型的少量语料说话人-情感语音转换方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 815-822. |
| [12] | 孙晨伟, 侯俊利, 刘祥根, 吕建成. 面向工程图纸理解的大语言模型提示生成方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 801-807. |
| [13] | 董艳民, 林佳佳, 张征, 程程, 吴金泽, 王士进, 黄振亚, 刘淇, 陈恩红. 个性化学情感知的智慧助教算法设计与实践[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 765-772. |
| [14] | 马灿, 黄瑞章, 任丽娜, 白瑞娜, 伍瑶瑶. 基于大语言模型的多输入中文拼写纠错方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 849-855. |
| [15] | 曹鹏, 温广琪, 杨金柱, 陈刚, 刘歆一, 季学纯. 面向测试用例生成的大模型高效微调方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 725-731. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||