


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (10): 3277-3283.DOI: 10.11772/j.issn.1001-9081.2024091244
• 多媒体计算与计算机仿真 • 上一篇
文连庆1, 陶冶1( ), 田云龙2, 牛丽2, 孙宏霞2
), 田云龙2, 牛丽2, 孙宏霞2
收稿日期:2024-09-05
修回日期:2024-10-23
接受日期:2024-10-24
发布日期:2024-11-05
出版日期:2025-10-10
通讯作者:
陶冶
作者简介:文连庆(2000—),男,黑龙江哈尔滨人,硕士研究生,主要研究方向:语音合成、信号处理基金资助:
Lianqing WEN1, Ye TAO1(), Yunlong TIAN2, Li NIU2, Hongxia SUN2
Received:2024-09-05
Revised:2024-10-23
Accepted:2024-10-24
Online:2024-11-05
Published:2025-10-10
Contact:
Ye TAO
About author:WEN Lianqing, born in 2000, M. S. candidate. His researchinterests include speech synthesis, signal processing.摘要:
非自回归的文本到语音(NAR-TTS)模型的发展使得快速且高质量的语音合成成为可能。然而,合成语音的韵律仍有待提升,且在文本单元与语音之间存在一对多的问题,导致难以生成具有丰富韵律且高质量的梅尔频谱。此外,现有的NAR-TTS模型中存在大量冗余的神经网络。因此,提出一种基于流的轻量化高质量NAR-TTS方法——AirSpeech。首先,分析文本,得到不同粒度的语音特征编码;其次,采用基于注意力机制的技术对齐这些特征编码,从混合编码中提取韵律信息;在此过程中,利用长短距离注意力(LSRA)机制和单一网络技术使特征提取轻量化;最后,设计基于流的解码器,从而显著降低模型的参数量和峰值内存,并通过引入仿射耦合层(ACL),使解码出的梅尔频谱更细致和自然。实验结果表明,相较于BVAE-TTS和PortaSpeech方法,AirSpeech的结构相似性(SSIM)和平均意见得分(MOS)指标更优,能够兼顾合成语音的高质量和模型的轻量化。
中图分类号:
文连庆, 陶冶, 田云龙, 牛丽, 孙宏霞. 基于流的轻量化高质量文本到语音转换方法[J]. 计算机应用, 2025, 45(10): 3277-3283.
Lianqing WEN, Ye TAO, Yunlong TIAN, Li NIU, Hongxia SUN. Flow-based lightweight high-quality text-to-speech conversion method[J]. Journal of Computer Applications, 2025, 45(10): 3277-3283.
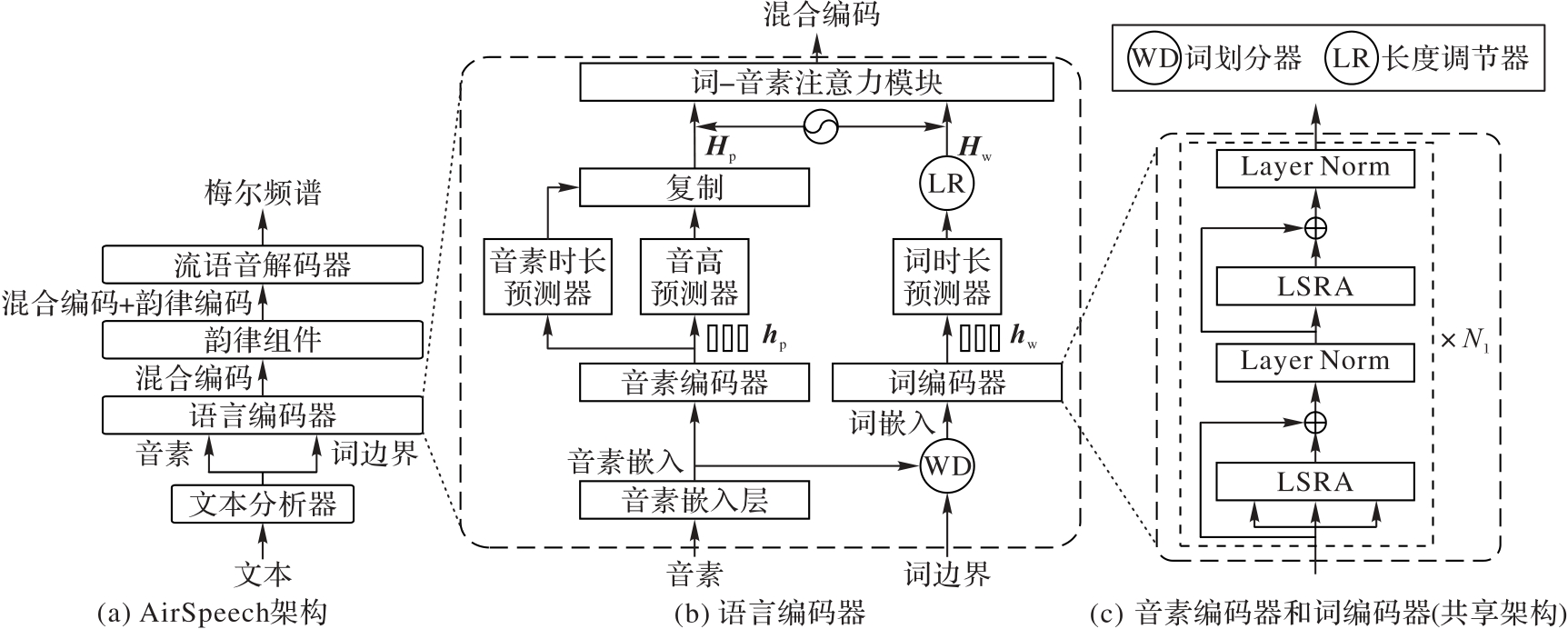
图1 AirSpeech架构及语言编码器结构
Fig. 1 AirSpeech architecture and language encoder structure
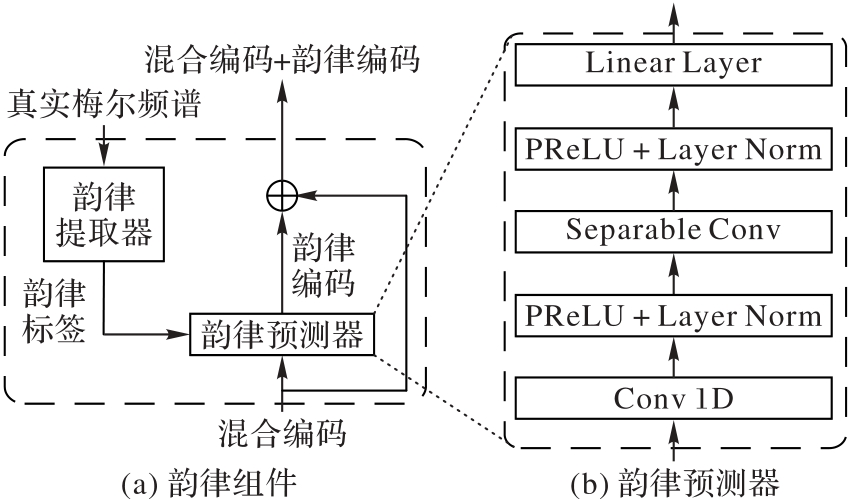
图2 韵律组件的结构
Fig. 2 Structure of prosodic component
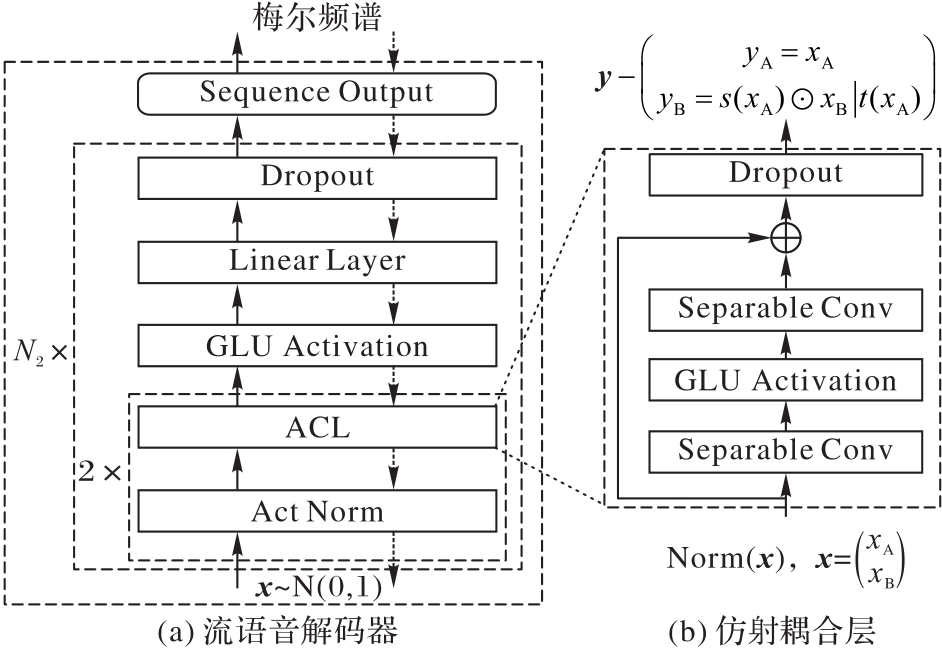
图3 流语音解码器的结构
Fig. 3 Structure of flow-based speech decoder
| 评分标准 | 描述 | 典型表现 |
|---|---|---|
| (4.5,5.0] | 完美无瑕 | 语音完全自然流畅,与真人发声无异,韵律、音调、音质无任何瑕疵 |
| (3.5,4.5] | 有轻微问题 | 语音基本自然流畅,有极少量不影响理解的微小问题,如轻微的韵律或音调不一致 |
| (2.5,3.5] | 有明显问题 | 语音可以理解,但存在明显的韵律、音调或音质问题,听起来不完全自然 |
| (1.5,2.5] | 有严重问题 | 语音理解有一定困难,存在较多严重的韵律、音调或音质问题,听起来不自然,存在音节失真或断续 |
| [0,1.5] | 无法接受 | 语音难以理解,有大量严重问题,如严重失真、音节丢失、大量噪声或极度不自然的音质,导致语音基本无法使用 |
表1 MOS的评分标准
Tab. 1 Scoring standards of MOS
| 评分标准 | 描述 | 典型表现 |
|---|---|---|
| (4.5,5.0] | 完美无瑕 | 语音完全自然流畅,与真人发声无异,韵律、音调、音质无任何瑕疵 |
| (3.5,4.5] | 有轻微问题 | 语音基本自然流畅,有极少量不影响理解的微小问题,如轻微的韵律或音调不一致 |
| (2.5,3.5] | 有明显问题 | 语音可以理解,但存在明显的韵律、音调或音质问题,听起来不完全自然 |
| (1.5,2.5] | 有严重问题 | 语音理解有一定困难,存在较多严重的韵律、音调或音质问题,听起来不自然,存在音节失真或断续 |
| [0,1.5] | 无法接受 | 语音难以理解,有大量严重问题,如严重失真、音节丢失、大量噪声或极度不自然的音质,导致语音基本无法使用 |
| 模型 | SSIM↑ | MCD↓ | F0 RMSE↓ | STOI↑ | PESQ↑ | MOS↑ | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LibriTTS | AISHELL-3 | LibriTTS | AISHELL-3 | LibriTTS | AISHELL-3 | LibriTTS | AISHELL-3 | LibriTTS | AISHELL-3 | LibriTTS | AISHELL-3 | |
| FastSpeech 2 | 0.502 | 0.445 | 10.76 | 15.84 | 46.62 | 60.68 | 0.792 | 0.705 | 1.302 | 1.343 | 3.93±0.08 | 3.82±0.07 |
| LiteTTS | 0.507 | 0.462 | 10.25 | 14.56 | 45.81 | 60.42 | 0.791 | 0.709 | 1.309 | 1.353 | 4.00±0.07 | 3.86±0.08 |
| BVAE-TTS | 0.522 | 0.476 | 10.21 | 14.35 | 45.01 | 60.33 | 0.798 | 0.707 | 1.315 | 1.355 | 4.02±0.06 | 3.91±0.07 |
| PortaSpeech | 0.529 | 0.478 | 10.18 | 14.82 | 44.83 | 60.29 | 0.806 | 0.715 | 1.316 | 1.358 | 4.04±0.08 | 3.93±0.07 |
| AirSpeech | 0.545 | 0.488 | 9.56 | 13.58 | 42.96 | 59.17 | 0.835 | 0.751 | 1.326 | 1.368 | 4.13±0.06 | 4.05±0.07 |
表2 AirSpeech与其他模型的比较评估
Tab. 2 Comparison evaluation of AirSpeech and other models
| 模型 | SSIM↑ | MCD↓ | F0 RMSE↓ | STOI↑ | PESQ↑ | MOS↑ | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LibriTTS | AISHELL-3 | LibriTTS | AISHELL-3 | LibriTTS | AISHELL-3 | LibriTTS | AISHELL-3 | LibriTTS | AISHELL-3 | LibriTTS | AISHELL-3 | |
| FastSpeech 2 | 0.502 | 0.445 | 10.76 | 15.84 | 46.62 | 60.68 | 0.792 | 0.705 | 1.302 | 1.343 | 3.93±0.08 | 3.82±0.07 |
| LiteTTS | 0.507 | 0.462 | 10.25 | 14.56 | 45.81 | 60.42 | 0.791 | 0.709 | 1.309 | 1.353 | 4.00±0.07 | 3.86±0.08 |
| BVAE-TTS | 0.522 | 0.476 | 10.21 | 14.35 | 45.01 | 60.33 | 0.798 | 0.707 | 1.315 | 1.355 | 4.02±0.06 | 3.91±0.07 |
| PortaSpeech | 0.529 | 0.478 | 10.18 | 14.82 | 44.83 | 60.29 | 0.806 | 0.715 | 1.316 | 1.358 | 4.04±0.08 | 3.93±0.07 |
| AirSpeech | 0.545 | 0.488 | 9.56 | 13.58 | 42.96 | 59.17 | 0.835 | 0.751 | 1.326 | 1.368 | 4.13±0.06 | 4.05±0.07 |
| 模型 | 参数量/ | 峰值内存/MB |
|---|---|---|
| FastSpeech 2 | 27.3 | 124.8 |
| Lite-TTS | 13.4 | 98.2 |
| BVAE-TTS | 12.5 | 90.1 |
| PortaSpeech | 6.7 | 39.3 |
| AirSpeech | 7.5 | 45.3 |
表3 各系统的模型参数量和峰值内存占用
Tab. 3 Number of model parameters and peak memory usage of each system
| 模型 | 参数量/ | 峰值内存/MB |
|---|---|---|
| FastSpeech 2 | 27.3 | 124.8 |
| Lite-TTS | 13.4 | 98.2 |
| BVAE-TTS | 12.5 | 90.1 |
| PortaSpeech | 6.7 | 39.3 |
| AirSpeech | 7.5 | 45.3 |
| 模型 | 编码器参数量/ | 解码器参数量/ |
|---|---|---|
| FastSpeech 2 | 8.5 | 18.5 |
| Lite-TTS | 4.4 | 9.0 |
| BVAE-TTS | 3.7 | 8.3 |
| PortaSpeech | 2.0 | 3.6 |
| AirSpeech | 2.5 | 4.3 |
表4 各系统的编码器和解码器参数量
Tab. 4 Number of encoder and decoder parameters of each system
| 模型 | 编码器参数量/ | 解码器参数量/ |
|---|---|---|
| FastSpeech 2 | 8.5 | 18.5 |
| Lite-TTS | 4.4 | 9.0 |
| BVAE-TTS | 3.7 | 8.3 |
| PortaSpeech | 2.0 | 3.6 |
| AirSpeech | 2.5 | 4.3 |
| 模型 | 描述 |
|---|---|
| w/o LE | 替换AirSpeech的语言编码器为基于Transformer的编码器 |
| w/o PC | 移除AirSpeech中的韵律组件 |
| w/o SSD | 替换AirSpeech的流语音解码器为基于Transformer的解码器 |
表5 消融实验设计
Tab. 5 Ablation experimental design
| 模型 | 描述 |
|---|---|
| w/o LE | 替换AirSpeech的语言编码器为基于Transformer的编码器 |
| w/o PC | 移除AirSpeech中的韵律组件 |
| w/o SSD | 替换AirSpeech的流语音解码器为基于Transformer的解码器 |
| 模型 | LJSpeech | AISHELL-3 | ||
|---|---|---|---|---|
| SSIM | CMOS | SSIM | CMOS | |
| AirSpeech | 0.545 | 0.00 | 0.488 | 0.00 |
| w/o LE | 0.513 | -0.25 | 0.456 | -0.23 |
| w/o PC | 0.519 | -0.15 | 0.467 | -0.14 |
| w/o SSD | 0.525 | -0.18 | 0.452 | -0.21 |
表6 AirSpeech中各模块的消融实验结果
Tab. 6 Ablation experimental results of each module in AirSpeech
| 模型 | LJSpeech | AISHELL-3 | ||
|---|---|---|---|---|
| SSIM | CMOS | SSIM | CMOS | |
| AirSpeech | 0.545 | 0.00 | 0.488 | 0.00 |
| w/o LE | 0.513 | -0.25 | 0.456 | -0.23 |
| w/o PC | 0.519 | -0.15 | 0.467 | -0.14 |
| w/o SSD | 0.525 | -0.18 | 0.452 | -0.21 |
| [1] | HUANG R, ZHAO Z, LIU H, et al. ProDiff: progressive fast diffusion model for high-quality text-to-speech [C]// Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 2595-2605. |
| [2] | TRIANTAFYLLOPOULOS A, SCHULLER B W, İYMEN G, et al. An overview of affective speech synthesis and conversion in the deep learning era [J]. Proceedings of the IEEE, 2023, 111(10): 1355-1381. |
| [3] | 张小峰,谢钧,罗健欣,等. 深度学习语音合成技术综述[J]. 计算机工程与应用, 2021, 57(9):50-59. |
| ZHANG X F, XIE J, LUO J X, et al. Overview of deep learning speech synthesis technology [J]. Computer Engineering and Applications, 2021, 57(9):50-59. | |
| [4] | TAN X, CHEN J, LIU H, et al. NaturalSpeech: end-to-end text-to-speech synthesis with human-level quality [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(6): 4234-4245. |
| [5] | XUE J, DENG Y, WANG F, et al. M2-CTTS: end-to-end multi-scale multi-modal conversational text-to-speech synthesis [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [6] | KAWAMURA M, SHIRAHATA Y, YAMAMOTO R, et al. Lightweight and high-fidelity end-to-end text-to-speech with multi-band generation and inverse short-time Fourier transform [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [7] | SHEN J, PANG R, WEISS R J, et al. Natural TTS synthesis by conditioning WaveNet on MEL spectrogram predictions [C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 4779-4783. |
| [8] | REN Y, HU C, TAN X, et al. FastSpeech 2: fast and high-quality end-to-end text to speech[EB/OL]. [2024-08-10]. . |
| [9] | ŁAŃCUCKI A. FastPitch: parallel text-to-speech with pitch prediction [C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 6588-6592. |
| [10] | LIU S, SU D, YU D. DiffGAN-TTS: high-fidelity and efficient text-to-speech with denoising diffusion GANs [EB/OL]. [2024-08-14]. . |
| [11] | 王翠英. 基于深度学习的合成语音转换问题研究[J]. 自动化与仪器仪表, 2023(7):196-200. |
| WANG C Y. Research on synthetic speech conversion based on deep learning [J]. Automation and Instrumentation, 2023(7): 196-200. | |
| [12] | NGUYEN H K, JEONG K, UM S, et al. Lite-TTS: a lightweight Mel-spectrogram-free text-to-wave synthesizer based on generative adversarial networks [C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 3595-3599. |
| [13] | SHIRAHATA Y, YAMAMOTO R, SONG E, et al. Period VITS: variational inference with explicit pitch modeling for end-to-end emotional speech synthesis [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [14] | PAMISETTY G, RAMA MURTY K SRI. Prosody-TTS: an end-to-end speech synthesis system with prosody control [J]. Circuits, Systems, and Signal Processing, 2023, 42(1): 361-384. |
| [15] | CHEN J, SONG X, PENG Z, et al. LightGrad: lightweight diffusion probabilistic model for text-to-speech [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [16] | SINGH A, NAGIREDDI A, JAYAKUMAR A, et al. Lightweight, multi-speaker, multi-lingual Indic text-to-speech [J]. IEEE Open Journal of Signal Processing, 2024, 5: 790-798. |
| [17] | HUANG S F, CHEN C P, CHEN Z S, et al. Personalized lightweight text-to-speech: voice cloning with adaptive structured pruning [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [18] | DUTOIT T. An introduction to text-to-speech synthesis, TLTB 3[M]. Dordrecht: Springer, 1997. |
| [19] | TOKUDA K, YOSHIMURA T, MASUKO T, et al. Speech parameter generation algorithms for HMM-based speech synthesis[C]// Proceedings of the 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing — Volume 3. Piscataway: IEEE, 2000: 1315-1318. |
| [20] | SUN G, ZHANG Y, WEISS R J, et al. Generating diverse and natural text-to-speech samples using a quantized fine-grained VAE and autoregressive prosody prior [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 6699-6703. |
| [21] | RAITIO T, LI J, SESHADRI S. Hierarchical prosody modeling and control in non-autoregressive parallel neural TTS [C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7587-7591. |
| [22] | JIANG Y, LI T, YANG F, et al. Towards expressive zero-shot speech synthesis with hierarchical prosody modeling [EB/OL]. [2024-07-19]. . |
| [23] | CHEN M, TAN X, LI B, et al. AdaSpeech: adaptive text to speech for custom voice [EB/OL]. [2024-07-13]. . |
| [24] | GUO H, XIE F, WU X, et al. MSMC-TTS: multi-stage multi-codebook VQ-VAE based neural TTS [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 1811-1824. |
| [25] | LEE Y, SHIN J, JUNG K. Bidirectional variational inference for non-autoregressive text-to-speech [EB/OL]. [2024-05-10].. |
| [26] | HWANG I S, HAN Y S, JEON B K. CyFi-TTS: cyclic normalizing flow with fine-grained representation for end-to-end text-to-speech [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [27] | MEHTA S, TU R, BESKOW J, et al. Matcha-TTS: a fast TTS architecture with conditional flow matching [C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 11341-11345. |
| [28] | MOSIŃSKI J, BILIŃSKI P, MERRITT T, et al. AE-Flow: autoencoder normalizing flow [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [29] | XUE L, SOONG F K, ZHANG S, et al. ParaTTS: learning linguistic and prosodic cross-sentence information in paragraph-based TTS [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 2854-2864. |
| [30] | CHIEN C M, LEE H Y. Hierarchical prosody modeling for non-autoregressive speech synthesis [C]// Proceedings of the 2021 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2021: 446-453. |
| [31] | SHOPOV G, GERDJIKOV S, MIHOV S. StreamSpeech: low-latency neural architecture for high-quality on-device speech synthesis [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [32] | YANG Y, KARTYNNIK Y, LI Y, et al. StreamVC: real-time low-latency voice conversion [C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 11016-11020. |
| [33] | IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 448-456. |
| [34] | BA J L, KIROS J R, HINTON G E. Layer normalization [EB/OL]. [2024-04-01]. . |
| [35] | KINGMA D P, DHARIWAL P. Glow: generative flow with invertible 1x1 convolutions [C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 10236-10245. |
| [36] | DAUPHIN Y N, FAN A, AULI M, et al. Language modeling with gated convolutional networks [C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 933-941. |
| [37] | ITO K, JOHNSON L. The LJSpeech dataset[DS/OL]. [2024-06-14]. . |
| [38] | SHI Y, BU H, XU X, et al. AISHELL-3: a multi-speaker Mandarin TTS corpus and the baselines [C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 2756-2760. |
| [39] | KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL]. [2024-04-13]. . |
| [40] | KONG J, KIM J, BAE J. HiFi-GAN: generative adversarial networks for efficient and high fidelity speech synthesis [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 17022-17033. |
| [41] | REN Y, LIU J, ZHAO Z. PortaSpeech: portable and high-quality generative text-to-speech [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 13963-13974.This work is partially supported by National Key Research and Development Program of China (2023 YFF 0612100); Key Technology Research and Industrialization Demonstration Project of Qingdao (24-1-2-qljh-19-gx).WEN Lianqing, in born 2000, M. S. candidate. His research interests include speech synthesis, signal processing.TAO Ye, in born 1981, Ph. D., professor. His research interests include software engineering, artificial intelligence, human-computer interaction.TIAN Yunlong, born in 1981, M. S., engineer senior . His research interests include smart home, digital transformation of brain, scene-based applications of next-generation artificial intelligence.NIU Li, born in 1983, M. S., engineer senior . Her research interests include intelligent home appliance scene generation, recognition speech, internet of things communication.SUN Hongxia, in born 1987, engineer. Her research interests include internet of things communication. |
| [1] | 鲁超峰, 陶冶, 文连庆, 孟菲, 秦修功, 杜永杰, 田云龙. 融合大语言模型和预训练模型的少量语料说话人-情感语音转换方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 815-822. |
| [2] | 蒋铭, 王琳钦, 赖华, 高盛祥. 基于编辑约束的端到端越南语文本正则化方法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 362-370. |
| [3] | 李卓然, 李华, 王桐, 蒋朝哲. 基于融合特征状态空间模型的轻量化人体姿态估计[J]. 《计算机应用》唯一官方网站, 2025, 45(10): 3179-3186. |
| [4] | 张勇进, 徐健, 张明星. 面向轻量化的改进YOLOv7棉杂检测算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2271-2278. |
| [5] | 程小辉, 黄云天, 张瑞芳. 基于多尺度和加权坐标注意力的轻量化红外道路场景检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1927-1934. |
| [6] | 宋霄罡, 张冬冬, 张鹏飞, 梁莉, 黑新宏. 面向复杂施工环境的实时目标检测算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1605-1612. |
| [7] | 吴郅昊, 迟子秋, 肖婷, 王喆. 基于元学习自适应的小样本语音合成[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1629-1635. |
| [8] | 耿焕同, 刘振宇, 蒋骏, 范子辰, 李嘉兴. 基于改进YOLOv8的嵌入式道路裂缝检测算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1613-1618. |
| [9] | 封筠, 毕健康, 霍一儒, 李家宽. 轻量化沥青路面裂缝图像分割网络PIPNet[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1520-1526. |
| [10] | 黄子杰, 欧阳, 江德港, 郭彩玲, 李柏林. 面向牵引座焊缝表面质量检测的轻量型深度学习算法[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 983-988. |
| [11] | 张成涵宇, 林钰哲, 谭程珂, 王俊帆, 顾烨婷, 董哲康, 高明煜. 基于轻量化YOLOv5的新型菜品识别网络[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 638-644. |
| [12] | 陈姿芊, 牛科迪, 姚中原, 斯雪明. 适用于物联网的区块链轻量化技术综述[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3688-3698. |
| [13] | 赵欣, 李鑫杰, 徐健, 刘步云, 毕祥. 基于卷积神经网络与Transformer并行的医学图像配准模型[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3915-3921. |
| [14] | 王宏, 钱清, 王欢, 龙永. 融合大核注意力卷积的轻量化图像篡改定位算法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2692-2699. |
| [15] | 郝巨鸣, 杨景玉, 韩淑梅, 王阳萍. 引入Ghost模块和ECA的YOLOv4公路路面裂缝检测方法[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1284-1290. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||