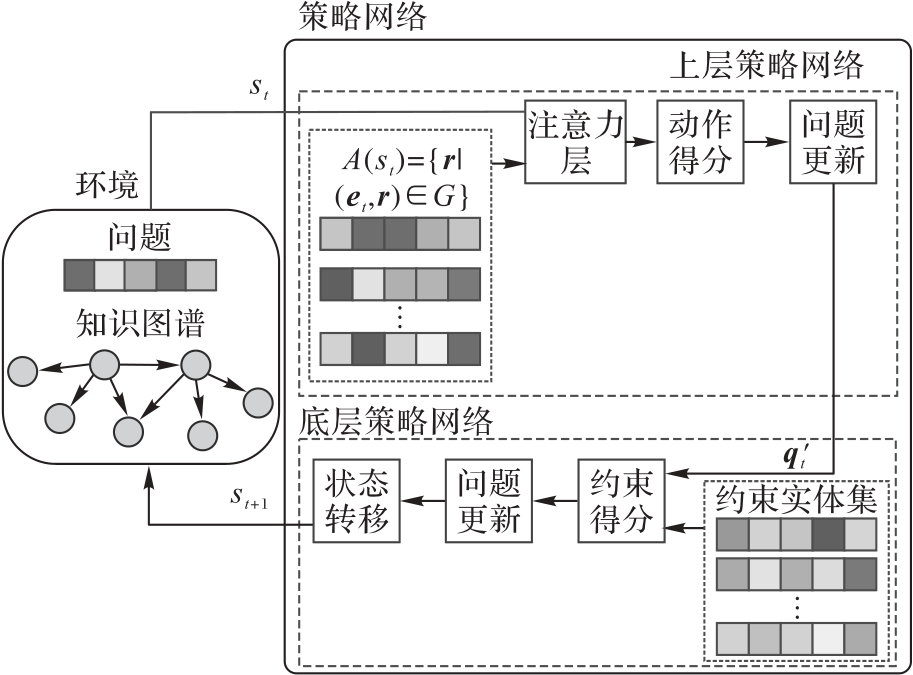
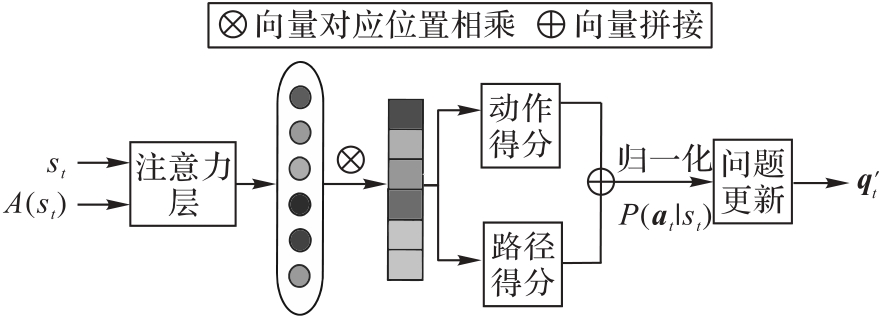
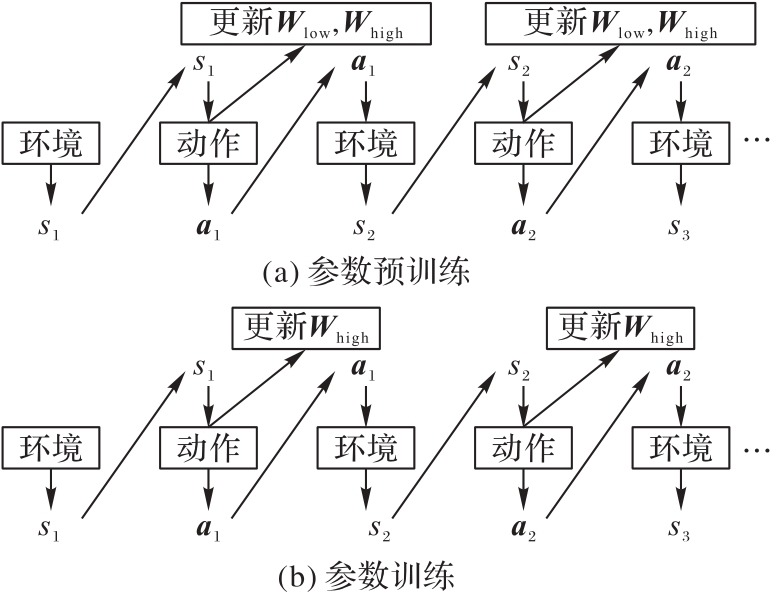
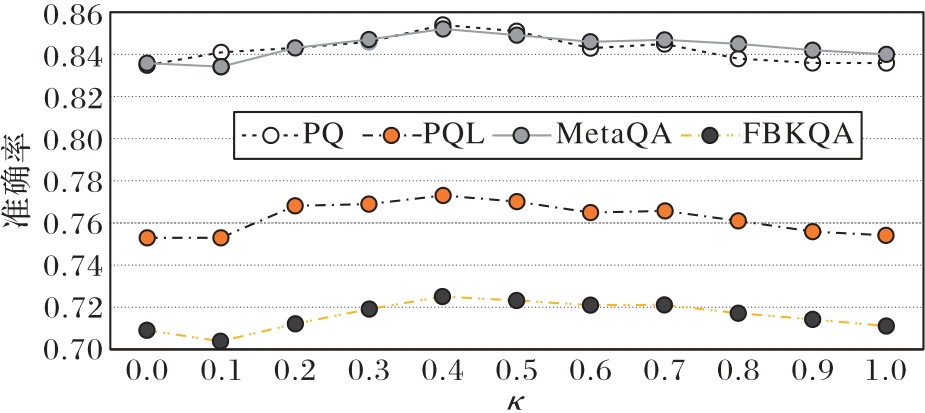
| [1] |
姚奕,尹瑞江,陈朝阳. 问答系统构建及推理研究综述[J]. 计算机技术与发展, 2023, 33(12): 8-16.
|
|
YAO Y, YIN R J, CHEN Z Y. A review of question answering system construction and inference research[J]. Computer Technology and Development, 2023, 33(12): 8-16.
|
| [2] |
毕鑫,聂豪杰,赵相国,等. 面向知识图谱约束问答的强化学习推理技术[J]. 软件学报, 2023, 34(10): 4565-4583.
|
|
BI X, NIE H J, ZHAO X G, et al. Reinforcement learning inference techniques for knowledge graph constrained question answering [J]. Journal of Software, 2023, 34(10): 4565-4583.
|
| [3] |
YANI M, KRISNADHI A A. Challenges, techniques, and trends of simple knowledge graph question answering: a survey[J]. Information, 2021, 12(7): No.271.
|
| [4] |
李振军,赵华,刘祖军,等. 基于路径排序的元路径模式搜索算法[J].微处理机, 2024, 45(5): 29-32.
|
|
LI Z J, ZHAO H, LIU Z J, et al. Metapath pattern search algorithm based on path ranking[J]. Microprocessors, 2024, 45(5): 29-32.
|
| [5] |
ZHOU M, HUANG M, ZHU X. An interpretable reasoning network for multi-relation question answering [C]// Proceedings of the 27th International Conference on Computational Linguistics. Stroudsburg: ACL, 2018: 2010-2022.
|
| [6] |
XIONG W, HOANG T, WANG W Y. DeepPath: a reinforcement learning method for knowledge graph reasoning [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2017: 564-573.
|
| [7] |
DAS R, DHULIAWALA S, ZAHEER M, et al. Go for a walk and arrive at the answer: reasoning over paths in knowledge bases using reinforcement learning [EB/OL]. [2025-04-07]..
|
| [8] |
BAI L, YU W, CHEN M, et al. Multi-hop reasoning over paths in temporal knowledge graphs using reinforcement learning[J]. Applied Soft Computing, 2021, 103: No.107144.
|
| [9] |
杨旭华,高良煜. 基于动态分层强化学习的知识图谱推理[J]. 小型微型计算机系统, 2025, 46(5): 1081-1088.
|
|
YANG X H, GAO L Y. Knowledge graph reasoning based on dynamic hierarchical reinforcement learning[J]. Journal of Chinese Computer Systems, 2025, 46(5): 1081-1088.
|
| [10] |
ZHAO T, HACHIYA H, NIU G, et al. Analysis and improvement of policy gradient estimation[J]. Neural Networks, 2012, 26: 118-129.
|
| [11] |
SHEN Y, CHEN J, HUANG P S, et al. M-Walk: learning to walk over graphs using Monte Carlo tree search [C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 6787-6798.
|
| [12] |
WAN G, PAN S, GONG C, et al. Reasoning like human: hierarchical reinforcement learning for knowledge graph reasoning[C]// Proceedings of the 29th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2020: 1926-1932.
|
| [13] |
WANG Q, HAO Y, CAO J. ADRL: an attention-based deep reinforcement learning framework for knowledge graph reasoning[J]. Knowledge-Based Systems, 2020, 197: No.105910.
|
| [14] |
ZHANG Q, WENG X, ZHOU G, et al. ARL: an adaptive reinforcement learning framework for complex question answering over knowledge base[J]. Information Processing and Management, 2022, 59(3): No.102933.
|
| [15] |
QIU Y, WANG Y, JIN X, et al. Stepwise reasoning for multi-relation question answering over knowledge graph with weak supervision[C]// Proceedings of the 13th International Conference on Web Search and Data Mining. New York: ACM, 2020: 474-482.
|
| [16] |
王宇航. 面向复杂问题的知识图谱问答方法研究[D]. 成都:电子科技大学, 2024.
|
|
WANG Y H. Research on knowledge graph question answering methods for complex problems[D]. Chengdu: University of Electronic Science and Technology of China, 2024.
|
| [17] |
LIN X V, SOCHER R, XIONG C. Multi-hop knowledge graph reasoning with reward shaping[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 3243-3253.
|
| [18] |
KAISER M, SAHA ROY R, WEIKUM G. Reinforcement learning from reformulations in conversational question answering over knowledge graphs [C]// Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 459-469.
|
| [19] |
PUTERMAN M L. Chapter 8 Markov decision processes[J]. Handbooks in Operations Research and Management Science, 1990, 2: 331-434.
|
| [20] |
周岩,范永胜,孙松,等. 一种面向知识图谱多跳问答的分层语义解析方法[J]. 计算机应用研究, 2025, 42(3): 714-719.
|
|
ZHOU Y, FAN Y S, SUN S, et al. Hierarchical semantic parsing approach for multi-hop question answering on knowledge graphs[J]. Application Research of Computers, 2025, 42(3): 714-719.
|
| [21] |
BOLLACKER K, EVANS C, PARITOSH P, et al. Freebase: a collaboratively created graph database for structuring human knowledge [C]// Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2008: 1247-1250.
|
| [22] |
ZHANG Y, DAI H, KOZAREVA Z, et al. Variational reasoning for question answering with knowledge graph [EB/OL]. [2024-10-26]. .
|
| [23] |
TAPASWI M, ZHU Y, STIEFELHAGEN R, et al. MovieQA: understanding stories in movies through question-answering [EB/OL]. [2024-10-26]. .
|
| [24] |
MILLER A, FISCH A, DODGE J, et al. Key-value memory networks for directly reading documents [C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2016: 1400-1409.
|
| [25] |
SHEN Y, HUANG P-S, CHANG M-W, et al. Implicit ReasoNet: modeling large-scale structured relationships with shared memory [EB/OL]. [2024-10-26]. .
|


 ), 肖奎1,2
), 肖奎1,2