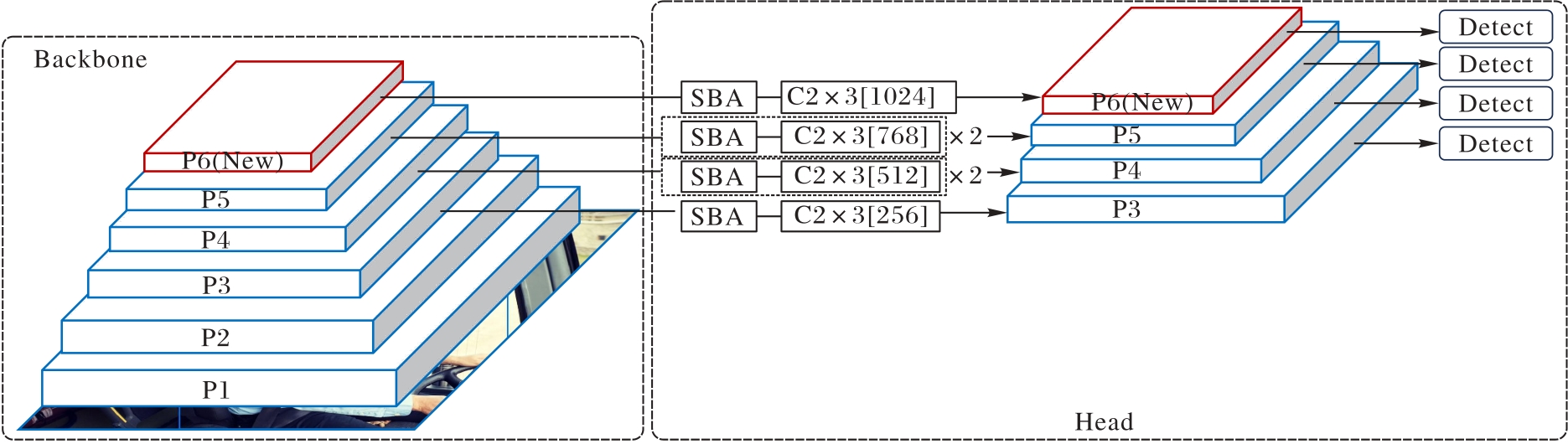
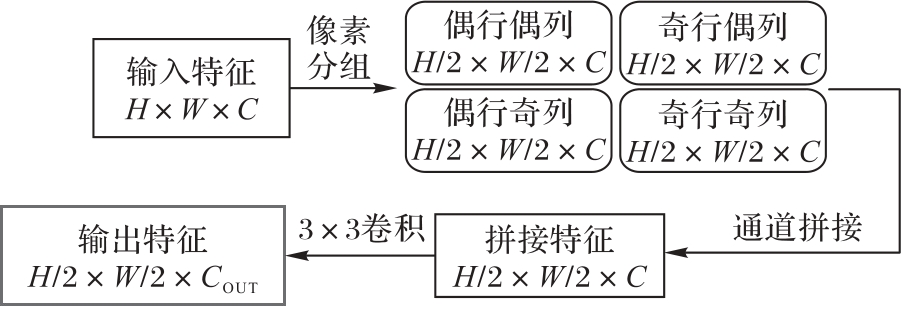
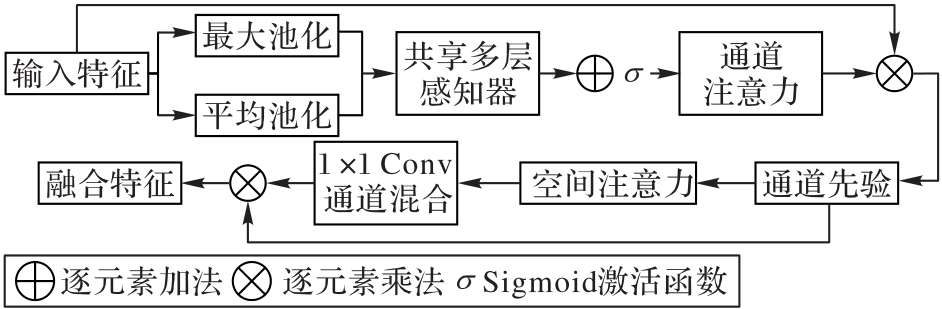
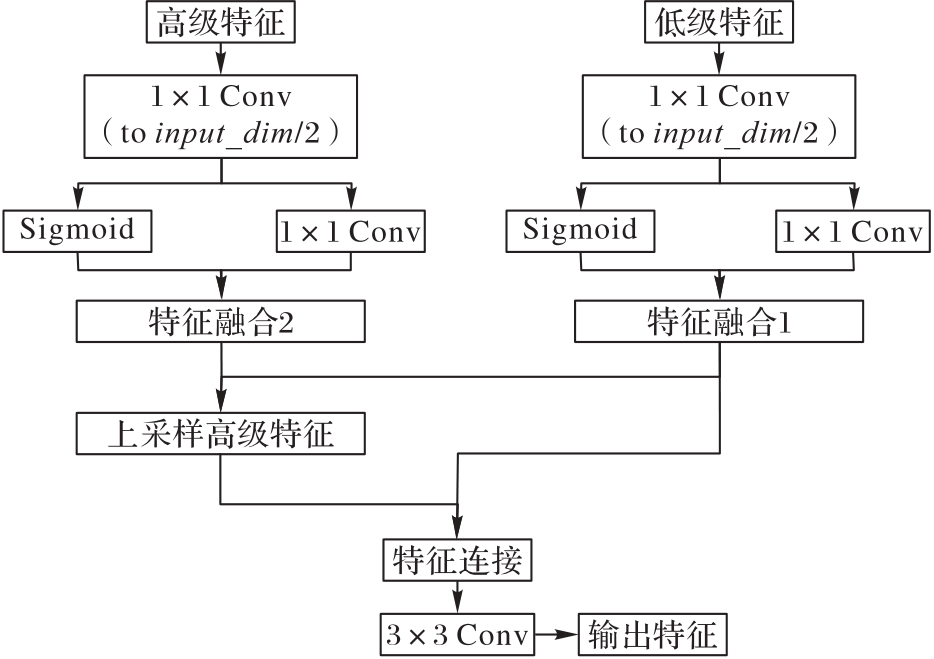
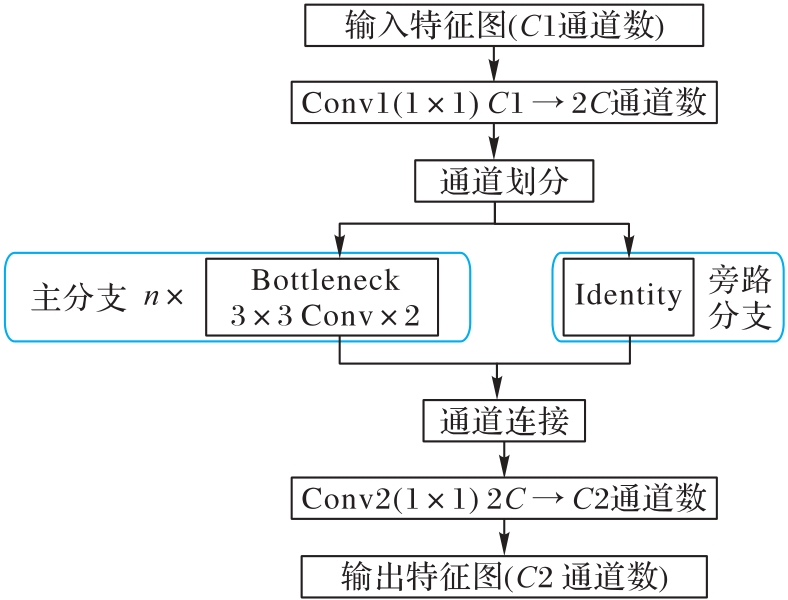
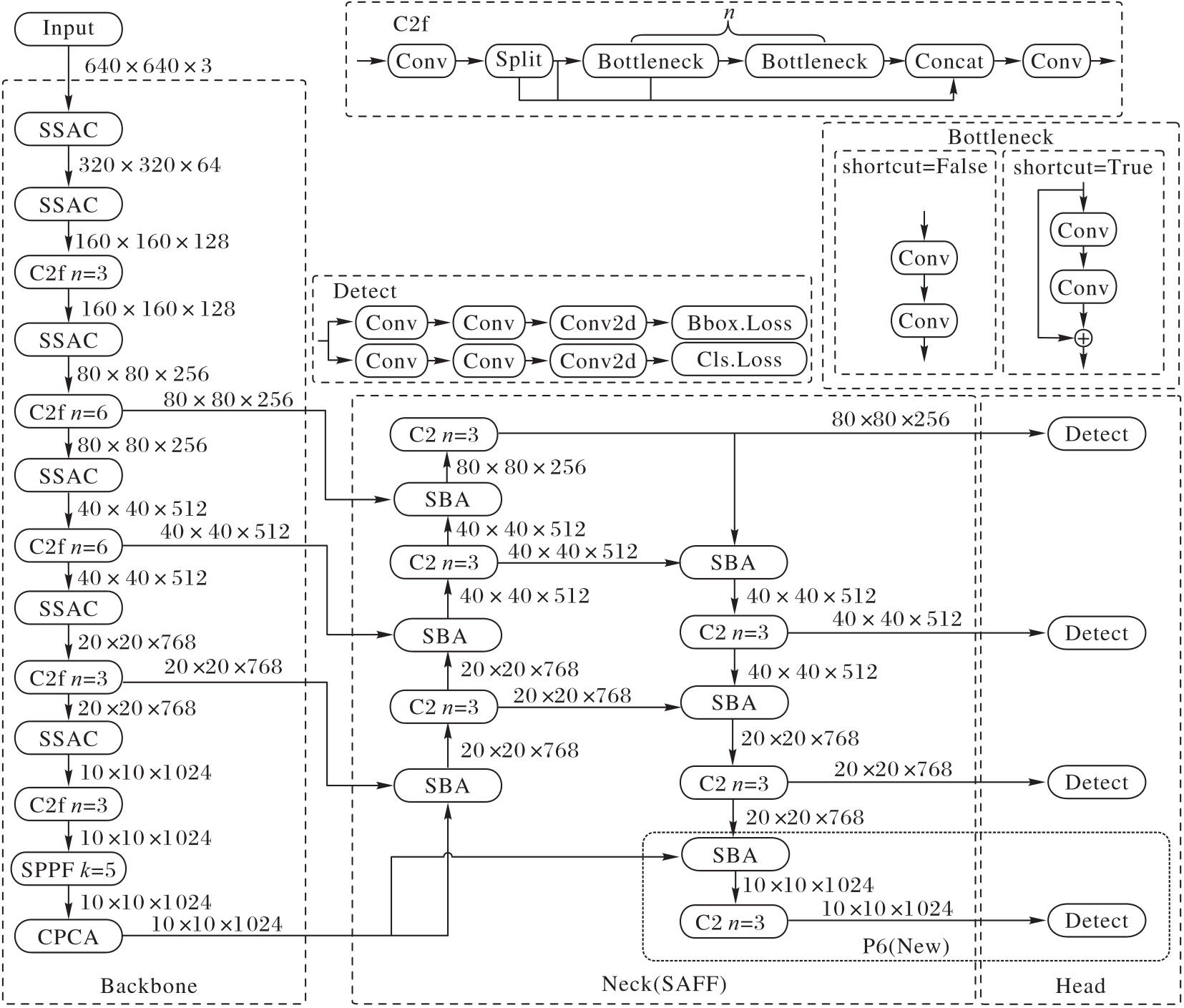
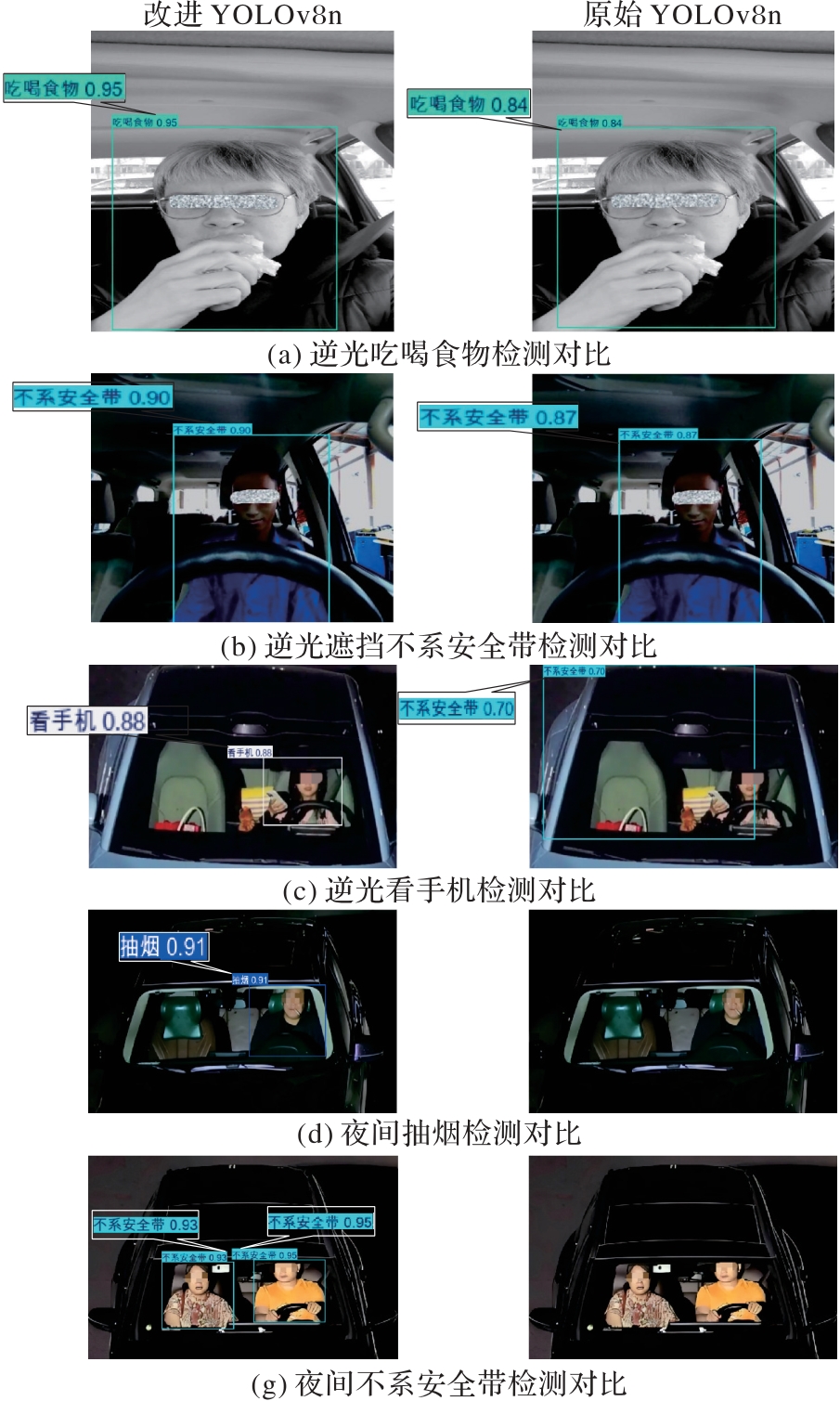
| [1] |
MOHD AZAMI M F A, MISRO M Y, HAMIDUN R. Road crash dynamics in Malaysia: analysis of trends and patterns[J]. Heliyon, 2024, 10(18): No.e37457.
|
| [2] |
KHOSRAVI E, HEMMATYAR A M A, SIAVOSHANI M J, et al. Safe Deep Driving behavior Detection (S3D)[J]. IEEE Access, 2022, 10: 113827-113838.
|
| [3] |
宁华晶. 不安全驾驶行为与道路交通事故之间的关系研究[D]. 兰州:兰州交通大学, 2023: 62-63.
|
|
NING H J. Study on the relationship between unsafe driving behaviors and traffic crashes[D]. Lanzhou: Lanzhou Jiaotong University, 2023: 62-63.
|
| [4] |
LATTANZI E, FRESCHI V. Machine learning techniques to identify unsafe driving behavior by means of in-vehicle sensor data[J]. Expert Systems with Applications, 2021, 176: No.114818.
|
| [5] |
QU F, DANG N, FURHT B, et al. Comprehensive study of driver behavior monitoring systems using computer vision and machine learning techniques[J]. Journal of Big Data, 2024, 11: No.32.
|
| [6] |
KANG H B. Various approaches for driver and driving behavior monitoring: a review[C]// Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops. Piscataway: IEEE, 2013: 616-623.
|
| [7] |
ABOSAQ H A, RAMZAN M, ALTHOBIANI F, et al. Unusual driver behavior detection in videos using deep learning models[J]. Sensors, 2022, 23(1): No.311.
|
| [8] |
HU J, ZHANG X, MAYBANK S. Abnormal driving detection with normalized driving behavior data: a deep learning approach[J]. IEEE Transactions on Vehicular Technology, 2020, 69(7): 6943-6951.
|
| [9] |
田文洪,曾柯铭,莫中勤,等. 基于卷积神经网络的驾驶员不安全行为识别[J]. 电子科技大学学报, 2019, 48(3): 381-387.
|
|
TIAN W H, ZENG K M, MO Z Q, et al. Recognition of unsafe driving behaviors based on convolutional neural network[J]. Journal of University of Electronic Science and Technology of China, 2019, 48(3): 381-387.
|
| [10] |
骆文婕. 基于机器视觉的非安全驾驶行为检测算法研究[D]. 长沙:湖南大学, 2018: 26-27.
|
|
LUO W J. Research on the detection algorithm of non-safe driving behavior based on machine vision[D]. Changsha: Hunan University, 2018: 26-27.
|
| [11] |
宋知霖. 基于深度学习的不安全驾驶行为检测算法研究[D]. 沈阳:沈阳工业大学, 2021: 22-27.
|
|
SONG Z L. Research on unsafe driving behavior detection algorithm based on deep learning[D]. Shenyang: Shenyang University of Technology, 2021: 22-27.
|
| [12] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 779-788.
|
| [13] |
李明煜,林家泉,高梅. 面向驾驶员面部目标的FD-YOLOv8轻量化检测算法[J]. 小型微型计算机系统, 2025, 46(11): 2700-2707.
|
|
LI M Y, LIN J Q, GAO M. FD-YOLOv8 lightweight detection algorithm for driver’s facial target[J]. Journal of Chinese Computer Systems, 2025, 46(11): 2700-2707.
|
| [14] |
孙铁强,魏光辉,宋超,等. 基于YOLO的多模态钢轨表面缺陷检测方法[J]. 电子测量技术, 2024, 47(21): 72-81.
|
|
SUN T Q, WEI G H, SONG C, et al. Multi-modal rail surface defect detection method based on YOLO[J]. Electronic Measurement Technology, 2024, 47(21): 72-81.
|
| [15] |
邱琳琳,朱卫纲,李永刚,等. 基于改进YOLOv8的SAR图像飞机目标检测算法[J]. 电光与控制, 2025, 32(3): 101-110.
|
|
QIU L L, ZHU W G, LI Y G, et al. Aircraft detection in SAR images based on improved YOLOv8[J]. Electronics Optics and Control, 2025, 32(3): 101-110.
|
| [16] |
HUANG H, CHEN Z, ZOU Y, et al. Channel prior convolutional attention for medical image segmentation[J]. Computers in Biology and Medicine, 2024, 178: No.108784.
|
| [17] |
赵佰亭,程瑞丰,贾晓芬. 融合多尺度特征的YOLOv8裂缝缺陷检测算法[J]. 计算机工程与应用, 2024, 60(22): 261-270.
|
|
ZHAO B T, CHENG R F, JIA X F. YOLOv8 crack defect detection algorithm based on multi-scale features[J]. Computer Engineering and Applications, 2024, 60(22): 261-270.
|
| [18] |
BOUHSISSIN S, SAEL N, BENABBOU F, et al. SafeSmartDrive: real-time traffic environment detection and driver behavior monitoring with machine and deep learning[J]. IEEE Access, 2024, 12: 169499-169517.
|
| [19] |
CHENG Q, LI H, YANG Y, et al. Towards efficient risky driving detection: a benchmark and a semi-supervised model[J]. Sensors, 2024, 24(5): No.1386.
|


 )
)